1 Zookeeper의 이해
1.1. Zookeeper 란?
주키퍼는 분산 어플리케이션을 위한 분산 코디네이션 서비스다.
-
ZooKeeper 자체도 분산 애플리케이션 형태로 구성돼 있고, 여러 노드가 모여 있는 클러스터 형태로 운영된다.
-
코디네이션 서비스 : 분산 시스템에서는 노드들이 서로 상태를 맞추거나(데이터 싱크), 어떤 노드가 어떤 역할을 맡을지 결정해야 하는 상황이 자주 발생하는데, 이때 각 애플리케이션이 직접 이런 조정 로직을 구현하면 복잡도와 오류 가능성이 매우 높아진다.
- ZooKeeper는 이런 역할(선출, 락, 상태 동기화 등)을 공통 서비스 형태로 제공해서 분산 시스템 간 조율(coordination)을 쉽게 할 수 있도록 도와준다.
- 즉, 각 분산 시스템이 직접 조정하지 않고, ZooKeeper에 위임하면 된다.
분산 어플리케이션을 만들기 위해 필요한 동기화, 설정, group, naming 에 대한 추상화된 수준의 서비스를 제공한다. 이 기능들을 API로 제공해서 사용하기 쉽고, 데이터 모델도 디렉토리구조를 하고 있어 이해하기 쉽다. (Java로 작성된 프로그램이고 Java와 C를 사용한다.)
분산 시스템에 있어서 Coordination 기능은 중요하지만 구현하기 힘들다. Lock, Race condition, Deadlock 때문이다. Zookeeper 를 이용하면 coordination 은 zookeeper에게 맡기고 분산 어플리케이션을 쉽게 구현할 수 있다.
- 예를 들어, 공유 자원을 업데이트하려면 락을 걸어야 하고, 락을 걸기 위해서는 동시에 접근하려는 여러 프로세스 간의 경쟁 상황(Race Condition)을 처리해야 한다. 이를 잘못 처리하면 데드락이 발생할 수 있다.
- 이러한 동기화 문제들을 직접 처리하는 것은 복잡하고 오류 가능성이 높기 때문에, Zookeeper와 같은 도구를 활용하면 coordination 기능을 안정적으로 위임할 수 있고, 분산 애플리케이션을 보다 쉽게 구현할 수 있다.
1.2 Zookeeper 의 주요 기능과 특징
1.2.1 ZNodes
ZooKeeper는 파일 시스템과 유사하게 구성된 shared hierarchical namespace를 통해 분산 프로세스가 서로 상호작용할 수 있다.
네임스페이스는 ZooKeeper 용어로 znodes라고 불리는 데이터 레지스터(저장공간)로 구성되어 있는데, 파일 시스템 디렉터리 구조와 유사하다.
저장용으로 설계된 일반적인 파일 시스템과 달리 ZooKeeper 데이터는 메모리에서 처리하기 때문에, ZooKeeper는 high throughput과 low latency를 제공한다.
여기서 말하는 저장은 persistant 디스크나 외부의 object_storage나 이런 거에다가 저장하기 위한 일반적인 파일 시스템.
shared hierarchical namespace
여러 클라이언트가 공유하는 트리 형태의 계층적 구조(hierarchical structure) 를 가진 이름 공간(name space) 을 말한다.
High Throughput (높은 처리량)
의미: 단위 시간당 처리할 수 있는 요청이나 작업의 수가 많다는 뜻
예시: 1초에 수천 개의 요청을 처리할 수 있다면, 그것은 high throughput 시스템입니다.
Low Latency (낮은 지연 시간)
의미: 하나의 요청에 대한 응답이 매우 빠르다
예시: 요청을 보내고 1ms 안에 응답을 받는 경우
1.2.2 비기능적 특징
ZooKeeper는 크게 세가지 목표를 다음과 같이 만족하도록 구현되어있다.
high performance
분산어플리케이션 수백 대가 같이 운영되는데 서로 락거니까 힘들잖아 그거 우리가 해줄게
- ZooKeeper의 성능은 대규모(수천 대) 분산 시스템에서 사용할 수 있는 수준이다.
high available
자기 자신이 클러스로 구성되어 있어서 특정 노드가 죽더라도 전체 시스템은 유지될 수 있도록 함
- Reliability는 SPOF(single point of failure)가 발생하지 않도록 설계되었다.
strictly ordered access
모든 접근의 순서를 다 매기는 것
- Strictly Ordered access는 클라이언트에서 정교한 동기화 기능을 구현할 수 있게 한다.
1.2.3 복제된 구성요소
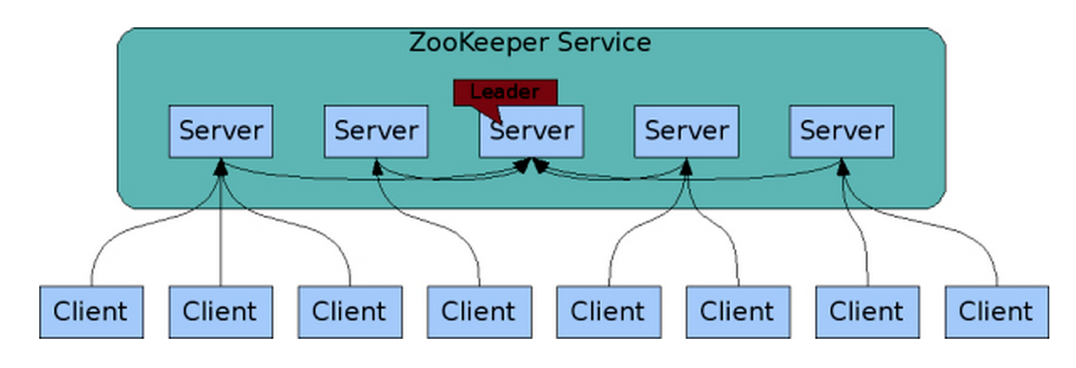
image source : https://unagi44.wordpress.com/2015/09/24/zookeeper-cluster/
모든 주키퍼 서버들은 같은 데이터를 복제한 것을 가지고 있고, 서로서로 연결을 가지고 있다. (서로서로 연결된 것을 앙상블이라고 부름.)
ZooKeeper가 상호작용하는 분산 프로세스와 마찬가지로 ZooKeeper 자체도 ensemble(앙상블)이라는 호스트 집합을 통해 복제된다.
우선 Zookeeper 클러스터를 구성하는 서버들은 모두 서로에 대해 알고 있다. Persistent store(disk)에 트랜잭션 로그, 스냅샷, 메모리 내 상태 이미지를 유지한다. Cluster를 구성하는 서버들 중 과반수(quorum)이상이 유지된다면, 일부에 장애나 문제가 있어도 전체 Zookeeper 서비스는 유지된다.
클라이언트는 ZooKeeper 서버에 연결한다. 클라이언트는 Zookeeper 연결에 대해 다음 기능을 할 수 있따.
- request
- read/write
- response
- read/write
- watch event
- 시그널이 오면 내가 여기에 대한 callback함수를 수행하는 식이 됨.
- heartbeat
- connection(session)이 활성화된 상태에서 client library에서 주기적으로 보낸다.
클라이언트가 연결된 서버에 대한 TCP 연결이 끊어지면, Cluster 내의 다른 서버에 연결한다.
1.2.4 Ordered
Zookeeper 는 모든 transaction에 대해서 순서에 대한 숫자를 남기고 그대로 관리한다. 이 순서를 사용하여 synchronization primitives 와 같은 더 높은 수준의 추상화를 구현할 수 있다.
1.2.5 Performance
Zookeeper 는 read 위주의 워크로드에 적합하다. 수천대의 서버에서 하나의 주키퍼 클러스터를 이용해서 코디네이션 서비스를 이용할 수 있지만, 이것은 read 위주의 작업이고 그 데이터의 양이 많지 않을 때 가능하다(memory). Zookeeper 에서 감당 가능한 적정한 read: write 비율은 10:1 (혹은 그 이하) 이다.
1.3 Zookeeper 요청 처리
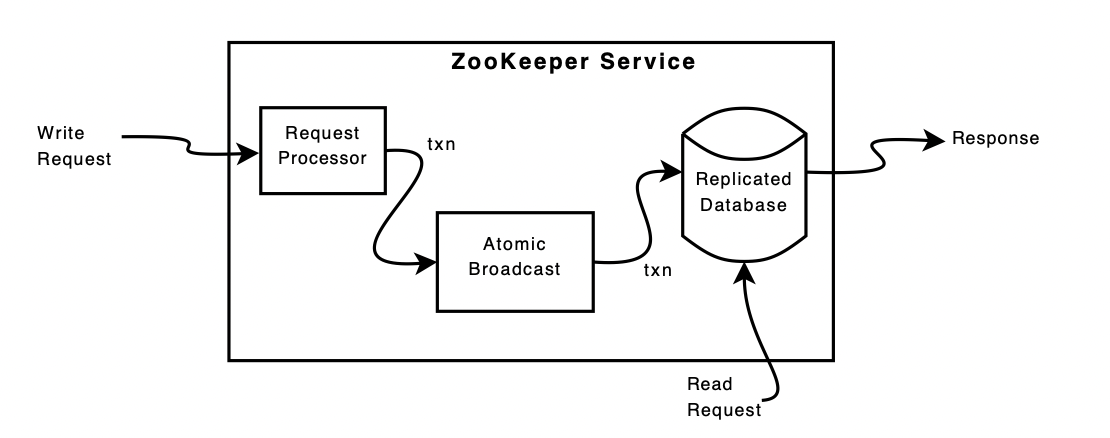
image source : https://omkarprabhu-98.github.io/2021/05/zookeeper.html
1.3.1 Replication & read
위 그림은 ZooKeeper 서비스의 high-level component 표현한 그림이다. request process(read/write Request, Request processor 포함) 를 제외하면 ZooKeeper 서비스를 구성하는 각 서버는 각 구성 요소의 자체 복사본을 복제한다.
복제된 데이터베이스는 전체 데이터 트리를 포함하는 in-memory 데이터베이스이다.
update는 복구 가능성을 위해 디스크에 기록된다.
쓰기는 메모리 내 데이터베이스에 적용되기 전에 디스크에 serialization된다.
- 메모리 기반이긴 하지만 디스크에 serialization되니까 안전하게 사용할 수 있다~
1.3.2 Contract Protocol
모든 ZooKeeper 서버는 클라이언트에 서비스를 제공한다. 클라이언트는 cluster 내의 여러 서버중 하나의 서버에 연결하고 요청을 보낸다. read request는 각 서버 데이터베이스의 로컬 복제본에서 처리한다. 서비스 상태를 변경하는 요청, write 요청은 contract protocol에 의해 처리된다.
Zookeeper 클러스터 내의 서버는 역할에 따라 leader, follower로 나뉜다. 역할에 따라 contract protocol은 다음 기능을 한다.
- leader: 데이터의 수정 권한을 가진 노드.
- write operation 이 수행된다.
- follower: leader 가 아닌 클러스터 내의 모든 서버
- write operation 은 leader 에게 전달한다.
- leader로부터 메세지를 받고 전달한다.
1.3.3 Messaging Layer
메시징 계층은 장애가 발생했을 때 리더 교체와 팔로워 노드를 리더와 동기화하는 작업을 담당한다.
ZooKeeper는 custom atomic messaging protocol 을 사용한다.
메시징 계층이 atomic 하기 때문에 ZooKeeper는 로컬 복제본 간의 분기(forking)가 발생하지 않도록 보장할 수 있다.
리더 노드는 write 요청을 수신하면, 해당 변경을 기반으로 시스템의 새로운 상태를 계산하고, 이를 트랜잭션 형태로 변환하여 클러스터 전체에 전파한다.
1.4 Performance Test
1.4.1 Performance Benchmark
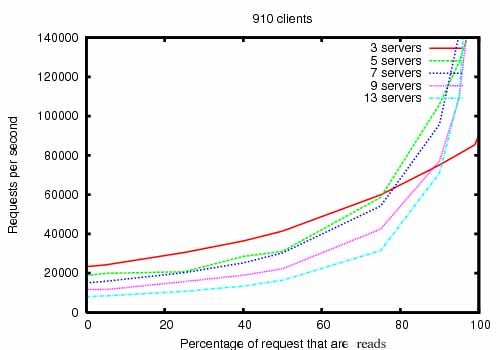
The ZooKeeper Throughput as the Read-Write Ratio Varies is a throughput graph of ZooKeeper release 3.2 running on servers with dual 2Ghz Xeon and two SATA 15K RPM drives. One drive was used as a dedicated ZooKeeper log device.
The snapshots were written to the OS drive. Write requests were 1K writes and the reads were 1K reads.
"Servers" indicate the size of the ZooKeeper ensemble, the number of servers that make up the service. Approximately 30 other servers were used to simulate the clients. The ZooKeeper ensemble was configured such that leaders do not allow connections from clients.
읽기:쓰기 비율이 달라질 때 ZooKeeper의 처리량(throughput)이 어떻게 변하는지를 측정한 것. (쓰기 부하가 많아질수록 성능이 감소하는 경향)
1.4.2 Reliability Benchmark
To show the behavior of the system over time as failures are injected we ran a ZooKeeper service made up of 7 machines.
We ran the same saturation benchmark as before, but this time we kept the write percentage at a constant 30%, which is a conservative ratio of our expected workloads.
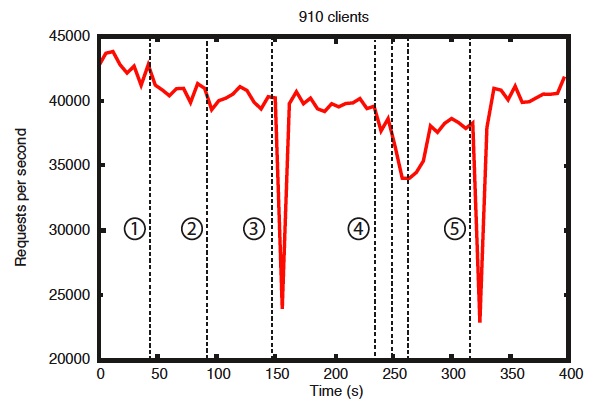
- Failure and recovery of a follower
- Failure and recovery of a different follower
- Failure of the leader
- Failure and recovery of two followers
- Failure of another leader
There are a few important observations from this graph.
First, if followers fail and recover quickly, then ZooKeeper is able to sustain a high throughput despite the failure.
But maybe more importantly, the leader election algorithm allows for the system to recover fast enough to prevent throughput from dropping substantially.
In our observations, ZooKeeper takes less than 200ms to elect a new leader.
Third, as followers recover, ZooKeeper is able to raise throughput again once they start processing requests.
팔로워 장애는 큰 영향 없음
→ 빠르게 복구되면 처리량(throughput)을 거의 유지함
리더가 죽어도 빠르게 복구됨
→ ZooKeeper는 200ms 이내에 새로운 리더를 선출
→ 처리량 하락이 크지 않음
팔로워 복구 시 처리량 다시 증가
→ 요청을 다시 처리하면서 성능 회복
ZooKeeper는 일부 서버에 장애가 발생해도 고성능을 유지하며,
리더 선출이 빠르고 안정적이기 때문에 전체 시스템이 크게 흔들리지 않음.
1.5 Zookeeper Quorum
1.5.1 Quorum 이란
Quorum은 주키퍼 클러스터의 앙상블(ensemble)을 이루고 있는 모든 서버 중 과반수 서버로 이루어진 그룹을 말한다.
Quorum을 이루는 노드들은 반드시 running 상태여야 하고 클라이언트의 요청을 처리하는 최소한의 서버 노드로 구성되어 있어야 한다.
주키퍼에서 데이터의 변경(write)이 성공했다면, Quorum을 구성하는 노드들은 변경 트랜잭션이 반영된 상태를 유지해야 한다.
1.5.2 Majority of Quorum
주키퍼는 앙상블을 구성할 때, 과반수의 서버 노드들로 Quorum을 구성한다. 과반수를 채택하는 이유는 분산 coordination 환경에서 예상치 못한 장애가 발생해도, 분산 시스템의 consistency를 유지시키기 위함이다.
Quorum을 과반수로 구성하지 않았을 때 생길 수 있는 문제 ( 앙상블 5대, Quorum 2대 일때 )
-
클라이언트가 주키퍼에게 쓰기 작업을 요청
-
주키퍼는 쓰기 작업 요청을 Quorum으로 복제 (2대)
-
5대 중 Quorum 2대에 쓰기 작업 요청이 완료되면 쓰기 작업이 성공
-
Quorum 2대에 장애가 발생하여 쓰기 작업 요청이 유실
-
주키퍼는 Quorum에 장애가 발생하였으므로 새로운 쿼럼 구성
-
쿼럼은 2대로 구성 가능하기 때문에 남은 3대의 서버중 2대로 새로운 쿼럼을 구성
-
클라이언트에서 쓰기 요청했던 내용은 유실되어 확인할 수 없음.
주키퍼 서비스는 안정적으로 돌아가고 있는데 데이터는 없어져 버렸다. consistency를 유지하지 못한다.
과반수로 구성한다면, ( 앙상블 5대, Quorum 3대 일때 )
-
클라이언트가 주키퍼에게 쓰기 작업을 요청
-
주키퍼는 쓰기 작업 요청을 Quorum으로 복제 (쿼럼 3대)
-
5대 중 Quorum 3대에 쓰기 작업 요청이 완료되면 쓰기 작업이 성공
-
Quorum 3대에 장애가 발생하여 쓰기 작업 요청이 유실
-
주키퍼는 Quorum에 장애가 발생했지만 남아 있는 서버가 과반수가 되지 못해 새로운 Quorum을 구성하지 못함
-
주키퍼는 이용 불가 상태가 됨
이렇게 이용불가 상태가 된다면, Client 또는 개발자는 장애인 것을 인지하고 대응할 수 있다.
- 이 상황에서 복구를 하려면 장애난 서버 또는 데이터의 하나를 복구해서 quorom을 구성해야한다.
