3 분산시스템의 대표 use case
3.1 Software LoadBalancer
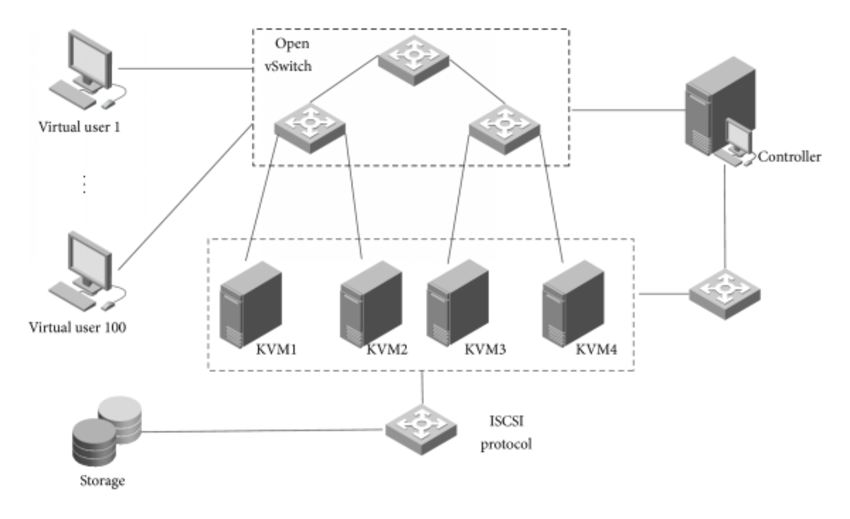
image source : https://www.researchgate.net/figure/Load-balancing-architecture-in-virtualization-environment-using-Open-vSwitch_fig6_282823478
과거 Loadbalancer 는 하나 또는 두개의 고 스펙의 하드웨어 장비/스위치가 로드밸런싱을 했다.
현대 LoadBalancer 에는 인스턴스가 많게는 수백~수천대 까지 연결되므로 하나의 고스펙 하드웨어로 모든 LB를 처리할 수 없다. 또한 설정이나 규칙의 변경이 잦고 그 복잡도까지 높아졌다.
따라서 AWS, Azure 등에서 선택하는 로드밸런서는 모두 소프트웨어 로드밸런서이고, 외부에 노출되는 IP주소, DNS 주소는 하나이지만, 내부적으로는 HA를 위해 여러 서버와 스위치로 구성되어있고, 실시간 설정 반영을 위한 동기화 시스템도 구축되어있다.
3.2 분산 메세지 큐
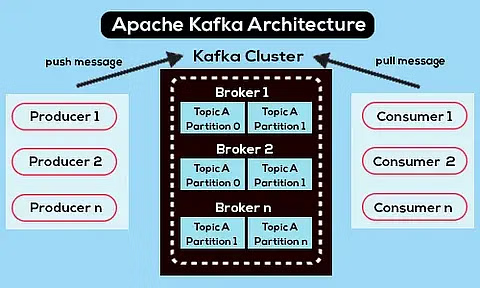
image source : https://www.projectpro.io/article/apache-kafka-architecture-/442
Queue 라고 하면 FIFO가 가능해야하므로, 순서가 보장이 되어야 한다. Queue 는 하나만 존재할 수 밖에 없다. (하나의 큐는 하나의 순서를 보장해야 하므로, 단일 큐로 존재할 수밖에 없다.)
하지만 하나의 큐만으로는 물리적인 처리량 한계가 존재한다.
이를 해결하기 위해 등장한 방식이, 하나의 논리적인 큐(=Topic)를
여러 개의 물리적인 큐(=Partition)로 나누어 처리량을 분산시키는 구조다.
이 구조의 대표적인 예가 Kafka이다.
Kafka에서는:
- 하나의 Topic은 여러 Partition으로 구성됨
- 각 Partition 내에서는 순서가 보장됨
- 하지만 Topic 전체적으로는 순서가 보장되지 않음
만약 Topic 전체에서 순서를 강제로 보장하려면, 하나의 Partition만 사용해야 하므로, 결국 처리량 손해(Throughput bottleneck)를 감수해야 한다.
즉, "처리량 vs. 전역 순서 보장"의 트레이드오프가 존재한다.
3.3 분산 데이터 저장소
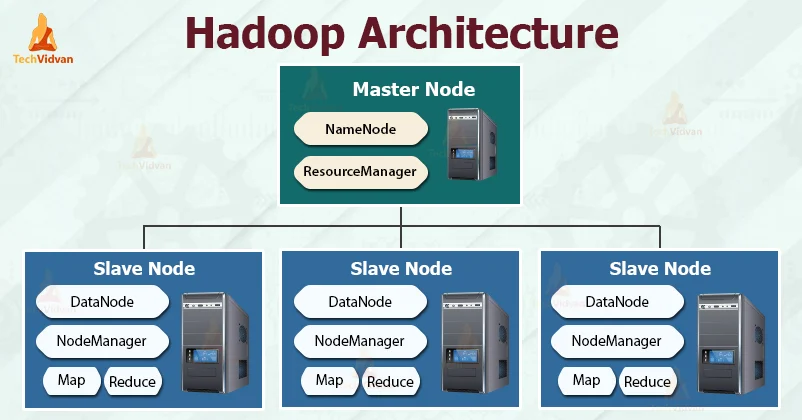
image source : https://techvidvan.com/tutorials/hadoop-architecture/
대용량의 분산시스템이 가장 필요한 곳이 저장소이다. 대량의 데이터를 나누어서 저장하면서도 유실되면 안되고, 언제든지 조회가 가능해야 했다. 대표적으로 Hadoop 이 있다.
3.4 분산 Application State Cluster
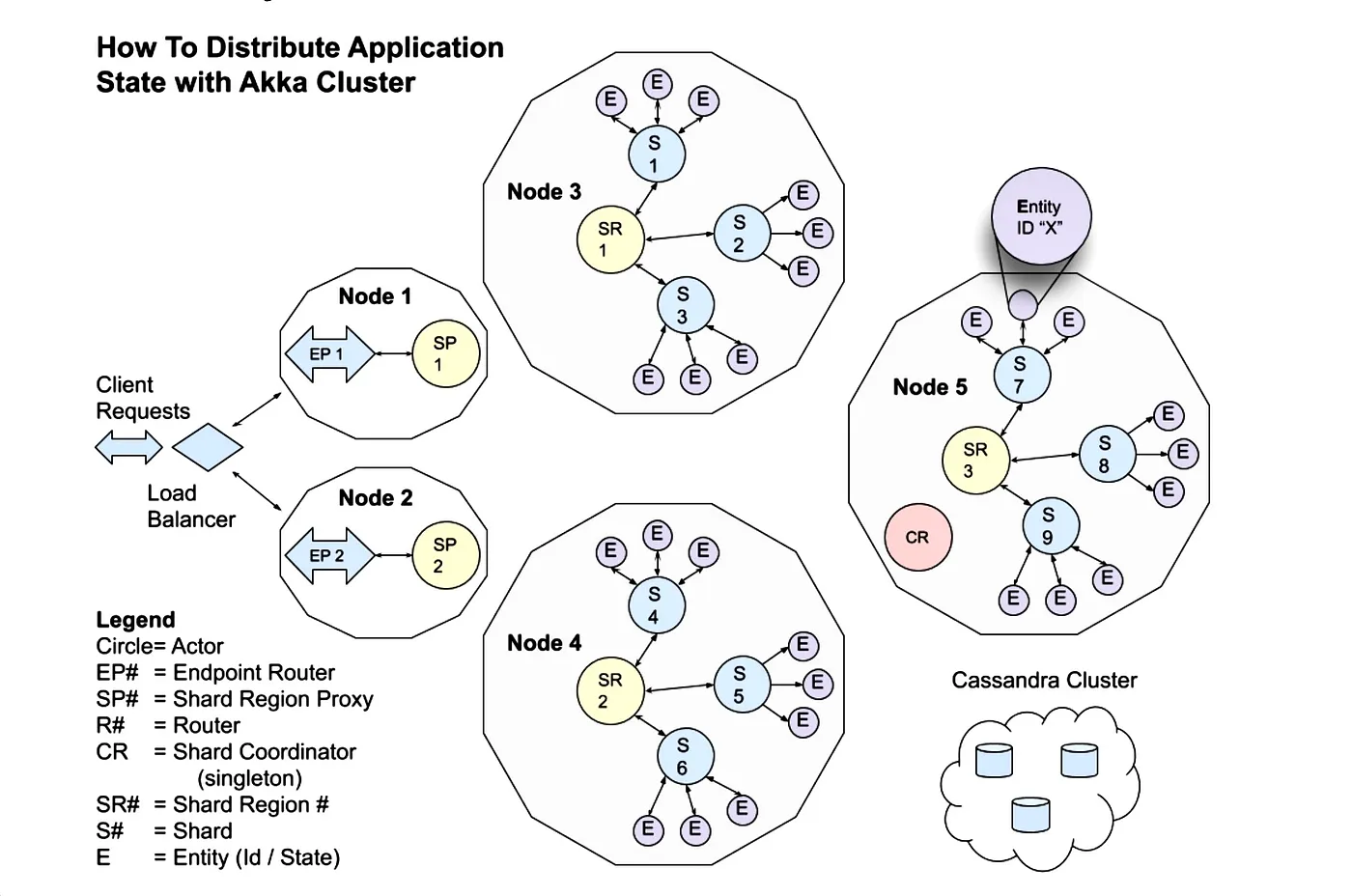
image source : https://susmitsircar.medium.com/reactive-data-pipelines-how-akka-powers-fast-fault-tolerant-data-connectors-a7803e5618fa
Database 말고 어플리케이션 서버도 확장하면서도 상태가 필요한데, 이걸 구현할 수는 없을까?
이 문제를 Actor 시스템을 기반으로한 Cluster 아키텍처로 푼 Akka System 이 있다.
