CNN(Convolutional Neural Netwrok)
MLP 이미지 분석
- MLP 신경망을 이미지 처리에 사용하면 이미지 위치에 민감하게 동작하며 위치에 종속적인 결과를 얻게 됨(모든 픽셀을 연산하기 때문)

CNN 구조
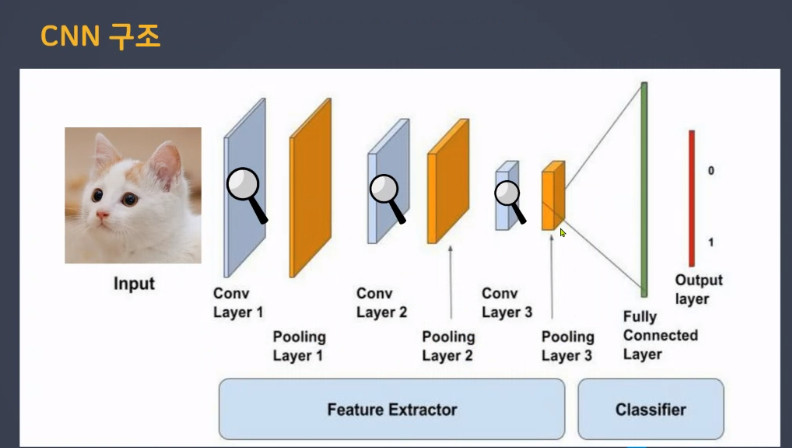

특성추출부의 층들이 깊어지면서 조금 더 디테일한 특징들을 잡아낸 후 특징들이 모여서 최종 판단
CNN은 어떻게 특징을 추출할까?
- CNN은 입력된 이미지에서 특징을 추출하기 위해 필터의 개념을 도입
- 이미지 전체 영역에 대해 서로 동일한 연관성(중요도)로 처리하는 대신 특정 범위에 한정해 처리한다면 훨씬 효과적일 것이라는 아이디어에서 착안
이미지 데이터에서 색상의 개념
- 합성곱 계층에서 이미지의 색상 정보를 채널이라고 부름
- 흑백으로 코딩 된 경우(ex.손글씨 이미지) 흑백의 그레이 스케일(0: 검은색, 255:흰색)만 나타내면 되므로 채널은 1이 됨
- 입력신호가 RGB 신호로 코딩된 경우, 채널은 세가지 색을 각각 나타내는 3이 됨(데이터의 색상 정보를 유지할 수 있음)
패딩

축소샘플링

스트라이드(Stride)
- 합성곱 연산을 수행할 때 한 픽셀씩 옆으로 이동하는 것이 아니라 2픽셀 또는 3픽셀씩 건너 뛰면서 합성곱 연산을 수행
- 이를 스트라이드2 또는 스트라이드3이라고 하는데 이렇게 하면 출력 데이터(특성맵)의 크기를 1/4 또는 1/9로 줄일 수 있음
풀링(Pooling)
- 가장 큰 값 하나만 선택하여 넘기는 방법
- 지역내 최대 값만 선택하는 풀링을 최대 풀링(max pooling)이라고 함
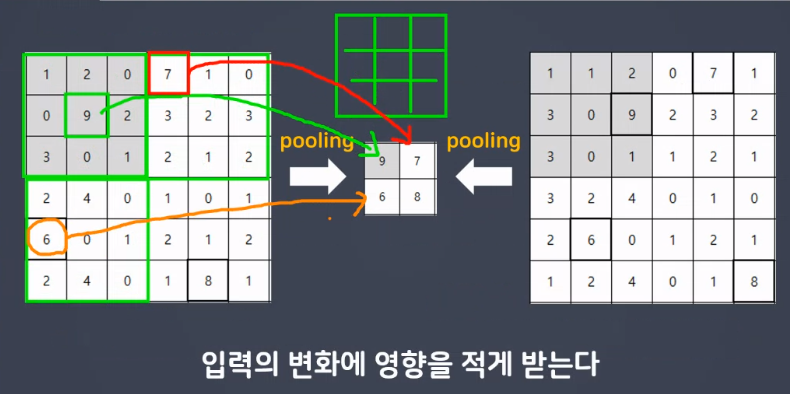
큰 값 : 중요한 데이터라고 인식
일반적으로 average pooling보다 max pooling을 많이 이용
1. 특성추출부(Conv - 특징이 되는 정보를 부각)
Conv2D : 2D 이미지 데이터에 대해서 특징이 되는 부분들을 부각
MaxPool2D : 2D 이미지 데이터에 대해서 필요없는 부분을 삭제cnn_model = Sequential() cnn_model.add(Conv2D(input_shape=(224,224,3), # 필터(돋보기)의 개수 -> 추출하는 특징의 개수를 설정(필터별로) filters=128, kernel_size=(3,3), # same : 원본데이터의 크기에 맞게 알아서 패딩을 적용(valid : 패딩 적용X) padding = 'same', activation = 'relu' ))
#### 2. 특성추출부(Pooling - 불필요한 정보 삭제)
```python
# pool_size : 디폴트 2(필터의 크기가 2X2)
cnn_model.add(MaxPool2D())
cnn_model.add(Conv2D(filters=256,
kernel_size=(3,3),
padding = 'same',
activation = 'relu'
))
cnn_model.add(MaxPool2D())
cnn_model.add(Conv2D(filters=256,
kernel_size=(3,3),
padding = 'same',
activation = 'relu'
))
cnn_model.add(MaxPool2D())
cnn_model.add(Conv2D(filters=64,
kernel_size=(3,3),
padding = 'same',
activation = 'relu'
))
cnn_model.add(MaxPool2D())
# MLP
cnn_model.add(Flatten())
cnn_model.add(Dense(128, activation='relu'))
cnn_model.add(Dense(64, activation='relu'))
cnn_model.add(Dense(32, activation='relu'))
cnn_model.add(Dense(3, activation='softmax'))
cnn_model.summary()
# CNN 첫 층에서의 파라미터수(w,b값)개수는 입력필터수 * 필터크기 * 채널수 + 필터수