DEN: Lifelong Learning with Dynamically Expandable Networks
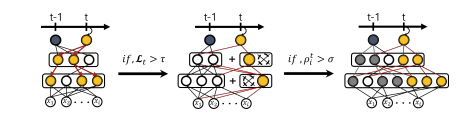
동영상 내용)lifelong learning에서 발생할 수 있는 catastropic forgetting을 해결하기 위해 선택적으로 prior knowledge를 활용하는 것도 굉장히 중요하고 네트워크를 필요한 만큼만 확장하도록 해야한다는 것도 중요하므로 이를 고려하여 DEN을 고안하였는데 3단계로 이루어져 있는데 (1) Selective retraining / (2) Dynamic network expansion / (3) Network split/duplication으로 이루어져 있습니다. Selective retraining은 간단하게 이전에 배웠던 prior knowledge들을 선택적으로 재학습을 하겠다는 것으로 이때 네트워크는 sparse network로 구성을 하여 상대적으로 informative한 neuron들만 가지고 재학습을 하도록 합니다. 이후에 Dynamic network expansion 이전단계에서 학습에서 이전에 배웠던 task와 현재 task가 유사할 때는 1,Selective retraining으로도 충분한 학습이 가능한데 그렇지 않을 때(유사하지 않을 때)는 지금 이 2번째 과정인 동적인 네트워크 확장을 진행하는데 loss를 측정했을 때 기준 점보다 높다면은 네트워크 확장이 필요하다고 판단하고 그런경우에는 네트워크를 일단 고정적으로 레이어마다 뉴런을 확장합니다.이렇게 뉴런을 고정적으로 확장한 다음에 group sparsity regularization((2,1)-norm이라고도 하며 feature sharing을 위한 regularization term으로 feature그룹단위의 학습이 되고 상위의 객체의 공통적인 특징과 같은 것들을 하위 feature로 특정 것들만 선택하는 형식)을 통해서 필요한 뉴런들을 선별을 하고 선별을 한다음에 그림에서 처럼 학습을 할 수 있도록 합니다.
이후 (3) Network split/duplication step에서는 continual learning에서 발생하는 catastrophic forgetting문제를 완화하기 위해서 진행하는 것으로 이전에 배웠던 feature들의 모습과 파라미터와 현재 학습된 파라미터와 비교를 해서 만일 어느정도 이상의 drift가 일어났다면 이를 복제하는데 현재 테스크에 좀 더 fit한 feature를 학습했다는 거니까 이것들을 복제하는 과정을 거칩니다.
Method 내용)
(1. Selective Retraining (선택적 재학습)
Selective retraining은 새로운 작업(task)이 도입될 때 전체 네트워크를 재학습하지 않고, 필요한 부분만 선택적으로 재학습하는 방법입니다. 이를 통해 학습 비용을 줄이고, 불필요한 negative transfer(이전 작업에 대한 성능 저하)를 방지합니다.
초기 학습: 초기 작업을 학습할 때는 네트워크의 가중치에 L1 정규화를 적용하여 가중치가 희소하게 유지되도록 합니다. 이로 인해 각 뉴런이 적은 수의 다른 뉴런들과 연결됩니다. 이는 연산량을 줄이고, 네트워크가 새로운 작업을 학습할 때 필요한 부분만을 선택적으로 학습할 수 있게 합니다.
새로운 작업 도입: 새로운 작업이 추가되면, 최상위 은닉층의 뉴런을 기반으로 희소한 선형 모델을 학습합니다. 이 과정에서 새로운 작업과 관련된 뉴런들과 그 가중치를 선택적으로 학습하며, 이전 작업과 관련된 뉴런은 변경하지 않습니다.
선택적 가중치 학습: 새로운 작업과 관련된 서브네트워크를 선택한 후, 그 서브네트워크만을 학습하여 성능을 최적화합니다. 이를 통해 전체 네트워크를 재학습하지 않고도 새 작업에 맞는 최적의 성능을 낼 수 있습니다.
이 방식은 전체 네트워크를 학습하는 것보다 훨씬 적은 연산 비용으로 새로운 작업에 대한 성능을 유지할 수 있게 해줍니다.
- Dynamic Network Expansion (동적 네트워크 확장)
새로운 작업이 도입되었을 때, 기존 네트워크만으로는 성능을 충분히 확보하지 못하는 경우가 있습니다. 이때, Dynamic network expansion을 통해 네트워크를 확장하여 필요한 뉴런을 동적으로 추가합니다.
확장 필요성 평가: 선택적 재학습 이후, 손실 함수 값이 설정된 임계값(Threshold)을 초과하면 네트워크가 새로운 작업을 처리하기에 충분하지 않다고 판단하고, 네트워크 용량을 확장합니다.
뉴런 추가: 각 층에 일정한 수의 뉴런을 추가하지만, 모든 뉴런이 필요하지 않을 수 있기 때문에 그룹 희소성 정규화(group sparsity regularization)를 적용합니다. 이를 통해 불필요한 뉴런을 자동으로 제거하고, 필요한 뉴런만 남겨둡니다.
효율적인 확장: 이 과정에서 반복적인 학습을 수행하지 않고, 단 한 번의 학습으로 확장할 뉴런의 수를 결정합니다. 이를 통해 계산 복잡성을 최소화하면서 네트워크 용량을 효율적으로 확장할 수 있습니다.
결과적으로, 이 방법은 기존에 필요한 용량을 동적으로 조절하여 새로운 작업을 처리하면서도 불필요한 뉴런을 최소화하는 방식으로, 네트워크의 효율성과 성능을 극대화합니다.
- Network Split/Duplication (네트워크 분리/복제)
Network split/duplication은 네트워크가 특정 작업을 학습하는 과정에서 기존 작업의 성능을 잃어버리는 semantic drift(의미적 변형)나 catastrophic forgetting(파국적 망각)을 방지하는 방법입니다.
Semantic drift 감지: 새로운 작업을 학습할 때, 각 뉴런의 가중치 변화량을 계산하여 그 뉴런이 기존 작업의 의미에서 너무 많이 벗어났는지를 확인합니다. 이를 ρ 값으로 측정하며, 이 값이 설정된 임계값(σ)을 초과하면 그 뉴런이 이전 작업과 너무 달라졌다고 판단합니다.
뉴런 복제: 의미가 크게 변한 뉴런은 복제합니다. 복제된 뉴런은 새로운 작업에 적합하도록 학습되고, 기존 뉴런은 이전 작업에 대한 의미를 유지하도록 합니다. 이렇게 하면 하나의 뉴런이 여러 작업을 처리하면서 생기는 혼란을 방지할 수 있습니다.
타임스탬프 도입: 추가된 뉴런에는 타임스탬프를 부여하여 어느 시점에 추가되었는지 기록합니다. 추론 시에는 각 작업이 학습된 시점 이전에 추가된 뉴런들만 사용함으로써, 의미적 변형을 방지하고, 작업별로 최적화된 서브네트워크를 유지할 수 있습니다.
이 방식은 기존 작업에 대한 성능을 유지하면서도 새로운 작업을 처리할 수 있게 해주며, 특히 여러 작업을 연속적으로 학습할 때 발생할 수 있는 문제를 효과적으로 해결할 수 있습니다.)
Network split/duplication의 역할
기존 작업과 새로운 작업의 차이점: 새로운 작업을 학습할 때, 일부 뉴런들이 이전 작업에서 배웠던 정보와는 다르게 새로운 정보를 학습하게 됩니다. 이 과정에서 semantic drift(의미 변형)라는 현상이 발생할 수 있습니다. 즉, 뉴런이 이전 작업에 비해 새로운 작업에서 다른 특징(피처)을 학습하면서 그 의미가 크게 변합니다.
semantic drift에 대한 대응: 어떤 뉴런이 이전에 학습한 특징과 현재 학습한 특징 간에 큰 차이가 있을 때, 그 뉴런은 현재 테스크에 더 적합한 새로운 정보를 학습했다고 판단합니다. 하지만 이 뉴런이 기존 작업에서도 여전히 중요한 역할을 할 수 있기 때문에, 기존 작업의 성능을 유지하면서도 새로운 작업을 잘 처리하기 위해 해당 뉴런을 복제합니다.
뉴런 복제의 이유: 뉴런을 복제하는 것은 새로운 작업에 적합한 학습 결과를 유지하기 위함입니다. 특정 뉴런이 새로운 작업에서 더 잘 맞는 특징을 학습하면, 그 뉴런이 현재 작업에 중요한 역할을 할 가능성이 높습니다. 하지만 기존 작업에서 그 뉴런의 의미가 사라지는 것을 방지하기 위해 복제된 뉴런은 새로운 작업에 맞게 학습되며, 원래 뉴런은 이전 작업의 특징을 유지합니다. 이렇게 하면 새로운 작업과 이전 작업 모두에 적합한 뉴런을 각각 유지할 수 있게 됩니다.
"fit한 feature를 학습했다는 거니까"의 의미
여기서 "현재 테스크에 좀 더 fit한 feature를 학습했다"는 의미는, 현재 작업의 요구에 더 잘 맞는(즉, 더 적합한) 특징을 그 뉴런이 학습했다는 뜻입니다. 그 뉴런이 새로운 작업에 맞게 변형된 것은 그 작업에 유리한 정보를 담고 있다는 것을 의미합니다. 따라서 그 뉴런을 복제함으로써 새로운 작업에 맞게 학습된 뉴런을 유지하고, 동시에 기존 작업의 성능을 유지하는 두 가지 목적을 모두 달성할 수 있습니다.
정리)continual learning에서 catastropic forgetting을 해결하기 위해 DEN을 고안하였는데 ewc의 경우에는 regularization term을 이용해서 retrain하되 expansion을 진행하지 않는것에 비해 den은 network를 확장을 하고 retrain을 진행을 하되 중요한 부분들만 retraining을 진행한다는 차이점이 있습니다. method는 3부분으로 나누어지는데 (1) Selective retraining / (2) Dynamic network expansion / (3) Network split/duplication으로 이루어져 있습니다.각각을 간단히 설명하면 Selective retraining은 새로운 작업(task)이 도입될 때 전체 네트워크를 재학습하지 않고, 필요한 부분만 선택적으로 재학습하는 방법입니다.Dynamic Network Expansion은 이전에 배웠던 task와 현재 task가 유사할 때는 1.Selective retraining으로도 충분한 학습이 가능한데 그렇지 않을 때(유사하지 않을 때)Dynamic network expansion을 통해 네트워크를 확장하여 필요한 뉴런을 동적으로 추가합니다.(3) Network split/duplication은 이전에 배웠던 feature들의 모습과 파라미터와 현재 학습된 파라미터와 비교를 해서 만일 어느정도 이상의 drift가 일어난 의미가 크게 변한 뉴런을 복제하는 것은 현재 테스크에 좀 더 fit한 feature를 학습했다는 거니까 이를 복제하는과정을 거칩니다.
출처)
https://velog.io/@wsh7787/%EB%85%BC%EB%AC%B8%EB%B6%84%EC%84%9D-LIFELONG-LEARNING-WITH-DYNAMICALLY-EXPANDABLE-NETWORKS
https://daeun-computer-uneasy.tistory.com/114
https://www.youtube.com/watch?v=MEWUZRMxdwU
