BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language
Method
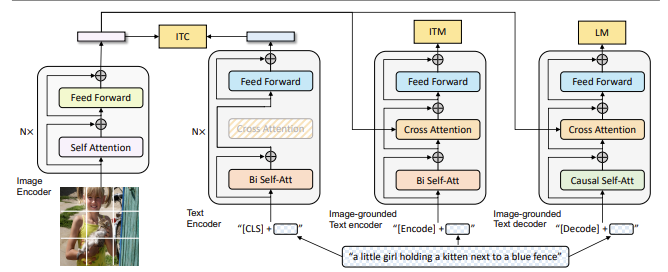
현존하는 VLP model은 understanding-based tasks나 generation-based tasks 하나만 잘하는데 논문은 vision-language understanding와 generation tasks 모두 유연하게 transfer하는 BLIP을 제안하였습니다. 기존 모델들과의 차별점은 모델 구조와 데이터 처리 방법이 다른데, 모델 측면에서는 멀티모달 인코더-디코더 즉,(MED) 구조를 도입하여 이미지-텍스트 검색, 캡셔닝, 질의응답 등 다양한 작업에 유연하게 대응합니다. 그림에서 보이는 것과 같이 Unimodal Encoder,Image-grounded text encoder,image-grounded text decoder로 구성되어 있으며 Image-Text Encoder (ITC): 이미지와 텍스트의 상관관계를 학습하여 특징을 독립적으로 추출합니다.
Image-Text Matching (ITM): 이미지와 텍스트의 일치 여부를 크로스 어텐션으로 예측합니다.
Language Model (LM): 크로스 어텐션을 사용해 이미지를 참조하며 텍스트를 생성합니다.각각의 역할을 수행합니다. 또한 각각 데이터 측면에서는 CapFilt 방식을 사용해 웹 데이터의 잡음을 줄이는데, 캡셔너가 생성한 텍스트를 필터링하여 더 나은 학습 데이터를 구축합니다. 이를 통해 BLIP는 기존 모델들보다 다양한 비전-언어 작업에서 성능을 개선하며, 비디오-언어 작업으로의 제로샷 전이에서도 우수한 결과를 보입니다.
• Image-Text Encoder (ITC):
• 이미지를 텍스트와 함께 인코딩하며, 두 모달리티의 상관관계를 학습합니다.
• 이미지와 텍스트 인코더가 각각 독립적으로 피드포워드 및 자기 주의(Self-Attention) 메커니즘을 사용해 특징을 추출합니다.
• 주로 이미지-텍스트 대칭 검색(Retrieval) 작업에 사용됩니다.
• Image-Text Matching (ITM):
• 주어진 이미지와 텍스트의 일치 여부를 예측하기 위해 크로스 어텐션(Cross Attention)을 사용합니다.
• 텍스트와 이미지 간 깊은 상호작용을 학습하여, 이미지 캡셔닝이나 질의응답 태스크에 적합합니다.
• Language Model (LM):
• 이미지 정보를 바탕으로 텍스트 생성 작업을 수행합니다.
• 크로스 어텐션을 통해 이미지를 참조하면서, 인과적 자기 주의(Causal Self-Attention) 메커니즘으로 텍스트를 순차적으로 생성합니다.
BLIP은 Unimodal Encoder,Image-grounded text encoder,image-grounded text decoder로 구성되어있습니다.Unimodal encoder를 사용하여 image와 text를 별도로 인코딩. Image Encoder는 ViT를 사용하며 입력 이미지를 패치로 나누어 임베딩합니다. Image-grounded text encoder는 각 transformer block에 대해 self-attention layer와 feed-forward network사이에 cross-attention layer를 삽입합니다. 이때 encode token이 텍스트에 추가되어 들어가고, 해당 encode embedding은 image-text pair의 multimodal representation으로 사용됩니다. 그리고 image-grounded text decoder는 image-grounded text encoder의 bidirectional self-attention layer를 casual self-attention layer로 대체되었습니다.
CapFilt의 동작 방식:
1. 사전 학습된 캡셔닝 모델 활용:
o 이미 학습된 모델을 사용해 이미지에 대한 새로운 캡션을 생성합니다.
o 이 과정에서 웹에서 수집한 원본 캡션과 모델이 생성한 캡션을 비교합니다.
2. 캡션 일치도 평가:
o 원본 캡션과 생성된 캡션 사이의 유사도를 측정합니다.
o 유사도가 높은 쌍은 학습에 적합한 데이터로 간주되고, 그렇지 않은 쌍은 필터링됩니다.
3. 노이즈 감소:
o CapFilt를 통해 신뢰도 높은 캡션만 학습에 사용하므로, 모델의 성능을 저해할 수 있는 부정확한 텍스트를 제거합니다.
출처)
https://seandoprep.tistory.com/5
https://velog.io/@qtly_u/BLIP-Bootstrapping-Language-Image-Pre-training-for-Unified-Vision-Language-Understanding-and-Generation
https://www.youtube.com/watch?v=Kgf7CigUfZc
