a style-based generator architecture for generative adversarial net
StyleGAN의 등장은 스타일 기반 이미지 생성 아키텍처에서 비롯되었습니다. 기존 GAN 모델들이 생성 과정을 블랙박스처럼 처리한 반면, StyleGAN은 고해상도 이미지의 속성을 해석 가능하게 만들었습니다. 이 모델은 중간 잠재 공간을 도입하여 이미지의 고수준 속성(예: 얼굴의 포즈와 정체성)과 저수준의 무작위 변동(예: 주근깨, 머리카락)을 분리했습니다. 또한, 그림을 통해 알수 있듯이
스타일 벡터
w 사용: 전통적인 GAN에서는 잠재 벡터
z가 첫 번째 입력으로만 사용되는 반면, StyleGAN은 중간 잠재 공간
w를 통해 각 합성 단계에서 이미지 스타일을 세밀하게 조정합니다.
AdaIN: Adaptive Instance Normalization을 사용하여 각 합성곱 계층마다 스타일 벡터를 적용함으로써 이미지의 다양한 요소를 조절할 수 있습니다.
노이즈 추가: 단순한 합성곱과 업샘플링 외에도 노이즈가 추가되어 이미지의 세부 사항을 더 자연스럽고 무작위적으로 만든다는 차이 점이 있고 이를 통해 이미지의 세부 속성을 직관적으로 제어합니다. 또한 mixing regularization을 통해 다양한 스타일 조합이 가능해졌습니다.
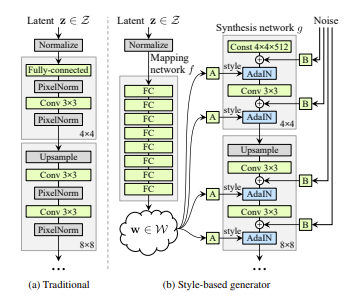
그림을 통해 알수 있듯이
스타일 벡터
w 사용: 전통적인 GAN에서는 잠재 벡터
z가 첫 번째 입력으로만 사용되는 반면, StyleGAN은 중간 잠재 공간
w를 통해 각 합성 단계에서 이미지 스타일을 세밀하게 조정합니다.
AdaIN: Adaptive Instance Normalization을 사용하여 각 합성곱 계층마다 스타일 벡터를 적용함으로써 이미지의 다양한 요소를 조절할 수 있습니다.
노이즈 추가: 단순한 합성곱과 업샘플링 외에도 노이즈가 추가되어 이미지의 세부 사항을 더 자연스럽고 무작위적으로 만듭니다.
https://hyoseok-personality.tistory.com/entry/StyleGAN-A-Style-Based-Generator-Architecture-for-Generative-Adversarial-Networks-%EB%A6%AC%EB%B7%B0-1%EC%84%B8%EC%84%B8%ED%95%9C-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
StyleGAN에서 중간 잠재 공간을 도입함으로써 고수준 속성과 저수준 무작위 변동을 분리하는 방법은 잠재 벡터(Latent Vector)를 두 단계에 걸쳐 변환하는 방식에 기반합니다.
잠재 공간 Z와 중간 잠재 공간 W: StyleGAN은 기존의 GAN처럼 기본 잠재 공간 Z에서 시작하지만, 이를 중간 잠재 공간 W로 변환하는 추가 단계를 도입합니다. 이 변환 과정은 고차원의 복잡한 특징을 처리하며, W 공간은 Z 공간에 비해 더 해석 가능하고, 이미지의 속성을 조정하기 쉽게 만듭니다.
스타일 변환 네트워크: W 공간에서 얻은 벡터는 스타일 변환 네트워크를 통해 각 레이어의 다양한 수준에서 이미지 생성에 영향을 미칩니다. 이 과정에서 고수준 속성은 주로 네트워크의 상위 레이어에서 제어되고, 저수준의 세부 변동은 하위 레이어에서 결정됩니다. 예를 들어, 얼굴의 포즈나 정체성과 같은 큰 변화는 네트워크의 앞쪽 레이어에서 결정되고, 머리카락의 질감이나 주근깨 같은 세부 사항은 뒷쪽 레이어에서 제어됩니다.
AdaIN은 스타일 변환 과정에서 매우 중요한 역할을 합니다. 스타일 벡터
𝑤
w를 사용하여 각 합성곱 계층마다 이미지의 특정 속성을 조절하게 되는데, 이 과정은 다음과 같은 방식으로 이루어집니다:
스타일 벡터 적용: 잠재 공간
𝑧
z에서 추출된 스타일 벡터
𝑤
w는 각 레이어에 전달되어 그 레이어에서 생성되는 이미지의 스타일을 조정합니다. 이때 스타일 벡터는 AdaIN에 의해 각 레이어의 출력값에 영향을 미칩니다.
AdaIN 메커니즘: AdaIN은 각각의 합성곱 레이어에서 입력 피처 맵을 표준화한 후, 스타일 벡터가 주입된 값에 따라 스케일링(scale)과 시프팅(shift)을 수행합니다. 이 과정을 통해 이미지의 특정 스타일 속성이 조절됩니다.
스케일링: AdaIN은 각 피처 맵의 표준화된 값에 스타일 벡터가 제공하는 스케일 값을 곱함으로써, 해당 이미지의 특정 스타일 속성을 조정합니다.
시프팅: 그런 다음, 시프팅 값을 더해줌으로써 이미지의 특성을 더욱 세밀하게 조정합니다.
고수준 속성 및 저수준 속성 조절:
고수준 속성: 네트워크의 상위 레이어에서는 얼굴의 포즈, 정체성, 구조와 같은 고수준 속성이 조절됩니다. 예를 들어, AdaIN을 통해 얼굴의 기울기나 눈, 코의 위치와 같은 중요한 구조적 변화가 일어납니다.
저수준 속성: 하위 레이어에서는 이미지의 세부적인 질감, 주근깨, 머리카락의 패턴 등과 같은 저수준 속성이 조절됩니다. 이때도 AdaIN을 사용하여 스타일 벡터가 각 세부 요소의 크기, 밀도, 질감을 제어할 수 있습니다.
직관적 조절: AdaIN을 통해 다양한 스타일이 이미지의 특정 부분에 적용될 수 있기 때문에, 스타일 벡터의 변형만으로 이미지의 전체적인 스타일뿐만 아니라 특정 부분만 선택적으로 조절하는 것이 가능합니다. 이를 통해 포즈, 색상, 질감 등 다양한 요소를 쉽게 조정할 수 있습니다.
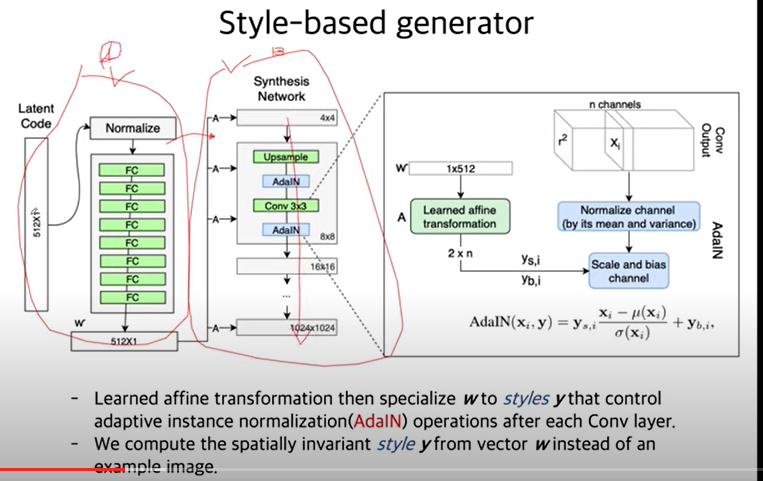
B부분은 어떠한 constant이미지로 부터 이미지를 쭉 만들어내는 과정이고, A라는 부분은 이미지로 부터 어떤 style을 구해서 B로 전달을 해주는 구조.AdaIN은 scale을 곱하고 bias를 더해주는 과정이 style을 입히는 concept으로 볼 수 있음.
출처)https://velog.io/@minjung-s/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0StyleGAN-A-Style-Based-Generator-Architecture-for-Generative-Adversarial-Networks
https://velog.io/@choidaedae/%EB%85%BC%EB%AC%B8%EB%A6%AC%EB%B7%B0-A-Style-Based-Generator-Architecture-for-Generative-Adversarial-Networks-StyleGAN1https://jjuon.tistory.com/42https://hyoseok-personality.tistory.com/entry/StyleGAN-A-Style-Based-Generator-Architecture-for-Generative-Adversarial-Networks-%EB%A6%AC%EB%B7%B0-1%EC%84%B8%EC%84%B8%ED%95%9C-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
