이번에 리뷰할 논문은 2019 CVPR에 발표된 "A Style-Based Generator Architecture for Generative Adversarial Networks"입니다. 흔히 StyleGAN으로 불리는 모델입니다. 논문에서 제안된 style-based generator만으로 기본적인 discriminator나 loss에도 robust하게 동작할 수 있습니다.
PGGAN을 baseline으로 사용하였기 때문에, 결과실험을 할때에는 PGGAN의 discriminator에 WGAN-GP를 사용하였고, 일부 데이터셋에서는 non-saturation loss와 R1 regularization을 사용하였습니다.
image synthesis task에서 정말 많이 등장하는 모델인데요, PGGAN,Style transfer 등 사전지식을 필요로하는 논문입니다. Style transfer에서 흔히 사용되는 AdaIN에 대한 포스팅을 먼저 보시고, 본 포스팅을 보시는 것을 추천드립니다.
Motivation
Contribution
- 본 논문에서 제안된 style-based generator로 고해상도 이미지를 높은 퀄리티로 생성합니다.
- Disentanglement를 측정하는 지표 두가지를 제안합니다.
- 1024x1024 고해상도 사람얼굴 데이터셋 "FFHQ" 발표
Style-based generator
앞서 말씀드렸듯이, StlyeGAN논문에서는 Discriminator나 loss에 관한 설명은 자세하게 나와있지 않고 style-based generator에 대한 설명이 대부분입니다. Style-based generator를 사용한 GAN구조를 StyleGAN이라고 합니다. generator를 제외한 다른 부분은 대체로 PGGAN의 구조를 그대로 사용합니다.(discriminator&loss)
PGGAN
baseline으로 사용된 PGGAN을 간단하게 설명하자면, 학습과정에서 layer를 추가하는 방식의 고해상도 이미지 생성에 잘 동작하는 GAN model입니다.출처 :https://towardsdatascience.com/explained-a-style-based-generator-architecture-for-gans-generating-and-tuning-realistic-6cb2be0f431 고해상도 이미지는 high dimension이기 때문에, Generator보다 Discriminator학습이 쉬워집니다. real과 fake를 너무 구분하기 쉽다는 의미입니다. 또한 메모리 제약과 같은 computation 문제도 있습니다. PGGAN은 이를 해결하기 위해 학습을 하면서 4x4 reolution부터 1024x1024까지 점차 키워나갑니다. (Discriminator와 Generator 모두) 4x4와 같은 low resolution에서는 large scale의 feature들을 학습하고, high resolution으로 갈수록 세부적인 feature들을 학습하게 됩니다. 이렇게 점진적으로 layer를 추가하면서 학습하기 때문에 안정적으로 high resolution image를 만들 수 있습니다.
WGAN_GP에 대한 내용은 "WGAN,WGAN-GP"포스팅을 참고하시기 바랍니다.
 출처 : StyleGAN paper
출처 : StyleGAN paper
style-based generator는 크게 두가지 network로 이루어져있습니다.
- 1. Mapping Network
- 2. Synthesis Network
본 논문은 baseline인 PGGAN의 generator에 StyleGAN의 사용된 기능을 추가하면서 비교합니다.
 출처 :StyleGAN paper
출처 :StyleGAN paper
1. Mapping Network
baseline인 PGGAN의 문제는 세부적인 attribute를 조절하지 못한다는 것입니다. 이 단점을 해결하기 위해 latent sapce (Gaussian)에서 samping한 를 intermediate latent space 의 로 mapping해주는 non-linear mapping network를 사용합니다.
 출처 :https://towardsdatascience.com/explained-a-style-based-generator-architecture-for-gans-generating-and-tuning-realistic-6cb2be0f431
출처 :https://towardsdatascience.com/explained-a-style-based-generator-architecture-for-gans-generating-and-tuning-realistic-6cb2be0f431
이 mapping network는 8-layer MLP로 구성되고, 512차원 z를 512차원 w로 mapping해주는 역할을 합니다. 이러한 mapping network를 사용하는 이유는 feature들의 disentanglement를 보장하기 위해서 입니다. factor of variation become more linear
이와같이 구조는 간단한데요, 이 mapping network가 쓰이는 이유를 알아보겠습니다.
Disenstanglement란?
entanglement를 직역하면 '꼬여있다'라는 의미입니다. 반대로 disentanglement는 '잘 분리되어있다'로 해석할 수 있습니다. GAN에서 사용되는 disentanglement도 어떤 attribute를 잘 나눌 수 있는 것을 의미합니다.
논문에서 말하듯, disentanglement에서는 많은 정의가 있습니다. '각 attribute가 잘 분리 된다', 'content와 style이 잘 분리된다'등 범용적으로 쓰이는 표현입니다. disentanglement의 공통된 정의는 "latent space가 linear subspace로 구성된 다"는 것 입니다.
There are various definitions for disentanglement, but a common goal is a latent space that consists of linear subspaces, each of which controls one factor of variation.
 출처 :coursera - Build Basic Generative Adversarial Networks (GANs), 'Challenges with Controllable Generation'
출처 :coursera - Build Basic Generative Adversarial Networks (GANs), 'Challenges with Controllable Generation'
만약 random vector 로부터 생성한 이미지가 왼쪽의 수염이 없는 여자라고 할 때, 수염을 추가하고싶고 축을 조절하여 수염을 추가할 수 있는 random vector를 찾았다고 가정해보겠습니다. 이 여성의 그림에 수염을 추가할 수 있을까요?
물론 가능합니다. 그러나, 기존의 GAN같이 entangle되어있다면 오랜쪽 아래의 수염을 가진 남성의 사진이 나오게 됩니다. 즉 수염을 추가한 것 뿐만 아니라 다른 feature들이 동시에 변한 것입니다. 이는 수염이라는 feature에 다른 feature들이 correlated되어있기 때문입니다.
 출처 :coursera - Build Basic Generative Adversarial Networks (GANs), 'Challenges with Controllable Generation'
출처 :coursera - Build Basic Generative Adversarial Networks (GANs), 'Challenges with Controllable Generation'
수염(beard)를 조작하였을 때, 이 특징과 연관된 '머리','눈매'등이 함께 바뀌는 것을 보면 이들은 서로 entangle되어있다라고 할 수 있습니다. 내가 원하는 feature들 이외에 나머지는 고정한 상태로 조작하고 싶다면, 축을 disentangle하게 만들면 됩니다.
(모든 attribute를 disentangle하게 하는 것은 거의 불가능하지만, 최대한 less entanglement하도록 만들 수 있겠죠)
그렇다면 왜 latent space 에서 바로 이미지를 생성하는 것이 아닌, intermediate latent space 로 mapping해야 할까요??
 출처 :StyleGAN paper
출처 :StyleGAN paper
위 그림의 를 실제 데이터의 분포라고 하고 가로축은 성별에 대한 축, 세로축은 머리길이에 대한 축이라고 하겠습니다.
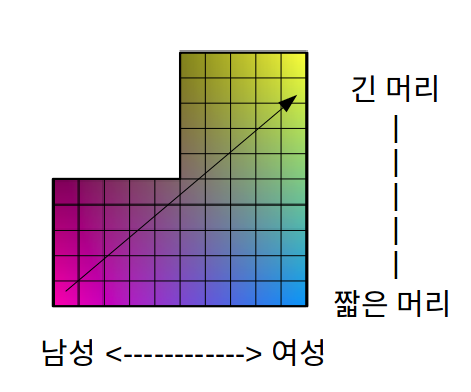
만약 "머리가 짧은 남성"에서 "머리가 긴 여성"으로 interpolation을 점점 수행한다면, 남성에서 여성으로 성별이 바뀌면서 머리가 점점길어지는 양상을 확인할 수 있습니다. 머리가 긴 남성은 데이터셋에 존재하지 않는다고 가정하여 위와같은 모양입니다.
만약 interpolation과정에서 성별이나 머리길이에 상관없는 feature들이 갑자기 나타난다면 space가 linear하지 않다는 의미입니다. 즉, entangle되어있다는 것이죠
기존 GAN모델들은 latent space가 데이터의 분포를 따라야 합니다. 따라서 Gaussian 또는 Uniform을 latent space로 하여 sampling하게 됩니다. PGGAN은 Gaussian에서 sampling합니다
는 PGGAN의 경우입니다. 데이터의 분포를 Gaussian으로 가정하기 때문에, space는 원래의 분포가 Gaussian에 맞춰 구부러져 모델링될 것입니다. 때문에 원래 분포보다 뒤틀림이 생기고, 보다 engtangle될 수 밖에 없습니다.
의 경우는 이러한 entanglement를 방지하고자, mapping network를 통해 imediate latent space로 한번 보내서 less entangle하게 만듭니다. latent space 보다 less entangle한 imediate latent space 에서 이미지를 생성하게되어 style을 interpolation하는 과정에서 더 linear하게 동작할 수 있습니다.
Synthesis Network
mapping network를 통해 sampling한 vector를 vector로 만들었습니다. 이제 vector로 이미지를 synthesis하는 방법을 알아보겠습니다.
PGGAN는 4x4부터 1024x1024까지, 총 9개의 layer가 있는 progressive growing구조입니다. 낮은 resolution의 layer에서는 얼굴형이나 피부색, 머리 스타일 같은 대략적인 특징을 만들고, 높은 resolution으로 갈 수록 머리 색이나 세부적이고 세밀한 특징을 만들게 됩니다. 이러한 동작으로 고화질의 이미지를 잘 생성할 수 있는 것입니다. StyleGAN에서도 이 progressive growing 구조를 유지하여 고화질의 이미지를 만들어냅니다.
synthesis network는 4x4부터 1024x1024 resolution feature map을 만드는 총 9개의 style block으로 이루어져있습니다. 마지막에는 RGB로 바꿔주는 layer가 있어 이미지 channel에 맞춰줍니다. Style block의 input은 전 style block의 output인 featuremap입니다. 하나의 style block당 두번의 convolution을 진행합니다.
Style block의 세부 구조는 크게 세가지로 나누어 설명드리겠습니다.
1) Style Modules (AdaIN)
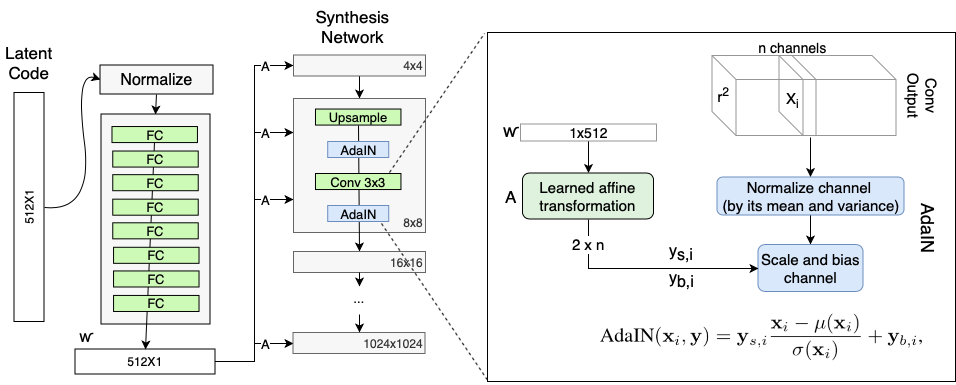
mapping network로 만들어진 w는 affine transform을 거쳐 style vector로 변합니다. A는 "learned affine transform" (fully connected layer) 으로 학습되는 parameter입니다. convolution 다음에 들어가기 때문에 총 18번 들어가게 됩니다. A로 스타일 벡터 를 만들고 AdaIN의 style scaling factor와 style bias factor의 역할을 하게 됩니다.
AdaIN은 content 이미지 에 style 이미지 의 스타일을 입힐 때 사용하는 normalization으로, style transfer에 거의 공식적으로 사용됩니다.
먼저 content 이미지를 정규화 합니다. style 이미지에 affine transform을 하여 style scaling factor 와 style bias factor 를 얻습니다. 정규화된 content이미지는 이에 맞춰 scaling되고 bias가 더해집니다.
Adaptive Instance Normalization인만큼 Instance Normalization에서 style factor들이 적용된 것입니다. AdaIN역시 IN과 동일하게 instance(각 이미지), channel별로 normalize됩니다.
style 이미지에 적용되는 affine transform은 학습됩니다.(learned)출처 :AdaIN paper
기존 AdaIn과 비교하면, convolution을 거친 featuremap이 AdaIN의 content이미지의 역할이고 가 style이미지의 역할입니다. feature map은 statistic하게 normalization되고 w으로 부터 나온 scaling factor와 곱해지고, bais factor가 더해집니다. normalize연산은 AdaIN,IN과 동일하게 당연히 channel specific하게 진행됩니다.
2) Constant input
style-based generator는 를 입력으로 받기 때문에, 더이상 PGGAN이나 다른 GAN과 같이 에서 convolution연산을 하지 않아도 됩니다. 때문에 synthesis network는 4x4x512 contant tensor에서 부터 시작합니다.
 출처 :https://towardsdatascience.com/explained-a-style-based-generator-architecture-for-gans-generating-and-tuning-realistic-6cb2be0f431
출처 :https://towardsdatascience.com/explained-a-style-based-generator-architecture-for-gans-generating-and-tuning-realistic-6cb2be0f431
뒤에 말씀드리겠지만, random한 noise에서 시작하는 것보다 contant에서 시작하는 것이 더욱 성능이 좋았습니다.
이유에 대한 본 논문에 나와있지 않지만, disenstangle한 를 사용하기 때문에 entangle된 를 사용하는 것을 피하는 효과가 아닐까 합니다..
3) Stochastic variation
Progressive growing구조와 AdaIN으로 고해상도의 이미지를 생성할 수 있습니다. 여기에 세부적인 attribute를 추가하기 위해 Noise를 추가해줍니다.
 출처 :https://towardsdatascience.com/explained-a-style-based-generator-architecture-for-gans-generating-and-tuning-realistic-6cb2be0f431
Gaussian에서 sampling한 nosie를 Convolution의 output인 featuremap에 더해줍니다(sum) B block을 통해 featuremap 사이즈에 맞게 변형됩니다. B 역시 학습되는 parameter입니다.
출처 :https://towardsdatascience.com/explained-a-style-based-generator-architecture-for-gans-generating-and-tuning-realistic-6cb2be0f431
Gaussian에서 sampling한 nosie를 Convolution의 output인 featuremap에 더해줍니다(sum) B block을 통해 featuremap 사이즈에 맞게 변형됩니다. B 역시 학습되는 parameter입니다.
이를 통해 stochastic variation을 추가할 수 있습니다. 여기서 Stochastic variation이란 머리카락의 배치이나 모공, 주근깨 같이 아주 세밀하고 때에 따라 달라지는 특징들을 말합니다.
 출처 :StyleGAN paper
이러한 Noise추가는 stochastic variation에만 영향을 주고, Styleblock과 AdaIN으로 만드는 high-level attribute에는 영향을 주지 않습니다.
출처 :StyleGAN paper
이러한 Noise추가는 stochastic variation에만 영향을 주고, Styleblock과 AdaIN으로 만드는 high-level attribute에는 영향을 주지 않습니다.
Properties of the style-based generator
Style mixing
StyleGAN의 특징 중 하나는 localization입니다. 여기서 의미하는 localization은 style의 특정 subset을 변경하는 것이 이미지의 특정 부분을 변경하는데 효과를 낸다는 의미입니다. 즉, layer의 특정한 부분을 바꾸는 것이 이미지 어떤 부분을 바꾸는 것에 영향을 줍니다.
StyleGAN의 progressive growing 구조의 장점을 앞에서 언급하였습니다. mapping network로 만들어진 는 synthesis network의 모든 layer에 적용될 style을 표현하도록 학습합니다. 낮은 resolution의 Style block에서는 symentic한 정보를 만들고 높은 resolution으로 갈 수록 세밀한 attribute에 영향을 준다는 것이었습니다. 이 성질을 이용하여 style의 localized network(Synthesis network의 block)을 조절하여 (scale-specific 수정) 이미지를 생성할 때 style attribute를 조절하는 것이 가능합니다.
예를 들어, 서로 다른 과 를 sampling하여 (from ) 4x4부터 32x32까지의 style block에는 을 사용하고, 64x64부터 1024x1024의 style block에는 을 사용하는 것입니다. 4x4부터 32x32 resolution에서 얼굴형, 안경의 유무를 만들고 그러한 특성들은 을 따릅니다. 64x64부터 1024x1024 resolution에서는 머리색 피부톤과 같은 세밀한 특징을 만들어내어 그러한 특징은 에서 영향을 받게 되는 것입니다.
 출처 :StyleGAN paper
출처 :StyleGAN paper
위 표는, 로만 만든 source A와 로만 만든 source B가 있을 때, 각 를 어느 resolution에서 cross over하여 style을 합성하는지에 따른 결과입니다.
- Coarse style : coarse resolution ( - )→ high level aspects (ex. pose, general hair style, face shape, eyeglasses) 전반적인, 큰 정보
- Middle style : middle resolution ( - ) → smaller scale facial features, hair style,eyes open/closed from B
- Fine style : fine resolution ( - ) → hair color, 피부톤 같은 세밀한 정보
fine resolution에서 cross over한다면, 전반적인 style은 source A를 따르고 머리색이나 세밀한 부분들같은 fine style는 source B를 담아 생성된 결과를 볼 수 있습니다.
mixing regularization
mixing regularization은 style mixing으로 만든 이미지도 discriminator에 "fake"로 넣어주는 기법입니다. mixing regularization을 사용하면 각 style이 더 잘 localization되어 다른 style에 correlation되지 않도록 합니다.
 출처 :StyleGAN paper
출처 :StyleGAN paper
위 표는 style mixing으로 생성한 image를 training시에 반영할 비율과 (하나의 latent code에서 만든 fake image와 style mixing으로 만든 generated image의 비율), 이미지를 생성할 때 몇개의 latent code로 style mixing을 하는지에 대한 FID 결과비교 입니다. 표에서 볼 수 있듯 mixing regularization을 하였을 때 성능이 확연히 좋은것을 확인할 수 있습니다.
Stochastic variation
Noise로 stochastic variation을 만들 때, B block을 거쳐 resolution마다 더해지기 때문에 scale-specific하게 stochastic variation을 수정할 수 있습니다. noise도 layer의 resolution에 따라 Coarse noise와 Fine noise로 나뉩니다.
- Course noise : 세기가 강한 머리의 곱슬거림,appearance of larger background features
- Fine nosie :세밀한 곱슬거림, finer background detail, 모공
 출처 :StyleGAN paper
출처 :StyleGAN paper
(a) 모든 layer에 noise
(b) No noise → stochastic variation control 불가. 머리카락 같은 정보의 디테일이 많이 떨어지는 것을 확인할 수 있다.
(c) fine noise → 세밀한 강도의 stochastic variation
(d) coarse noise →강한 강도의 stochastic variation
결론적으로 mixing을 통해 w는 global한 feature를 noise는 확률적인 feature를 조절할 수 있습니다.
Disentanglement measurement method
contribution에서 언급했던것 처럼, 본 논문에서는 disentanglement를 측정할 수 있는 두가지 지표를 제안합니다.
1. Perceptural Path Length
두개의 vector를 interpolation할 때 부드럽게 바뀌는지 측정하는 지표입니다. 앞서 언급했듯이, disentangle되어있다면 어떤 두 벡터를 samlping하여 interpolation을 진행할 때 자연스럽게 변화하는 양상을 보여야 합니다. 즉, 두 z를 interpolation할 때 결과 image의 semantic정보가 급격하게 변화한다면 entangled, smooth하게 변화한다면 disentanglement (less entanglement)하다고 할 수 있습니다.
논문에 "a perceptually-based pairwise image distance"라고 표현되어있는데, 어렵지 않습니다. 두 개의 로 생성한 이미지를 VGG16을 통과시켜 embedding시킨 뒤, 두 embedding vector의 차이를 계산하는 것입니다.
disentanglement를 비교하기 위해 space에서 sampling한 경우와 space에서 sampling한 경우로 나누었습니다.
를 각각 다른 방식으로 interpolation합니다.
-
latent pace
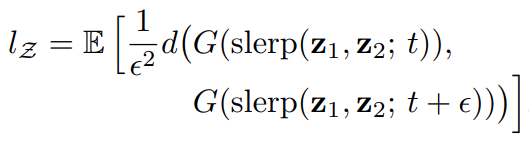 는 shpherical linear interpolation(구면선형보간법)을 합니다.
는 shpherical linear interpolation(구면선형보간법)을 합니다. -
intermediate latent space
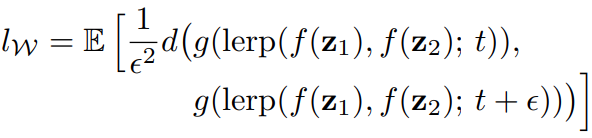 는 linear interpolation(선형보간법)을 합니다.
는 linear interpolation(선형보간법)을 합니다.
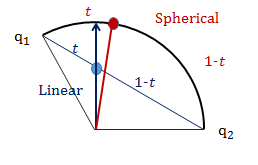
의 의미는 을 직선으로 이어(linear) 의 중간에 t의 지점을 sampling한다는 의미입니다. 이해를 쉽게하기 위해 t지점이라고 했지만, 사이를 t와 (1-t)의 비율로 나눈 지점을 의미합니다.
은 을 기준으로 포물선을 만들어 중간에 t의 지점을 sampling한다는 의미입니다.
왜 latent space의 disentanglement를 측정할 때, 와 가 서로 다른 보간법을 사용할 까요??
논문에서는 "는 normalize하지 않기 때문에 linear interpolation을 수행한다"라고만 언급되어있습니다. 이 이상의 설명은 다른 포스팅에서 찾아보기 힘
는 normalize되어 구면선형보간(Spherical Linear Interpolation)을 사용하는 것인데요, 왜 space에서는 구면을 따라 interpolation을 할까요??
space는 Gaussian으로 normalize됩니다. 2차원을 예시로 들자면
구면선형보간 선형보간
style mixing을 사용하지 않을 때가 더 좋다. style mixing은 style간의 uncorrelation을 없애도록 2개 이상의 w로 만드는 것
2. 선형적으로 얼마나 잘 분류되는지 측정
선형분류기를 학습한 뒤 선형분류기에 의해 서로다른 binary한 특징이 얼마나 잘 구분되는지 측정하였습니다. 선형분류기를 학습하여 latent vector가 얼마나 선형적인 sub-space에 존재하는지 확인할 수 있습니다.
latent space의 point가 linear 하이퍼프레인에 의해 잘 분류될 수 있는지를 보는 것 입니다.
celebA로 보조네트워크를 학습합니다. 40개의 binary한 정보
stylegan으로 w에서 200000개의 이미지를 생성하고 분류모델에 집어넣고 confidence가 높은 10만개 이미지들만 남깁니다.
(latent space를 가로지르는 선형분류기)
conditional 엔트로피값을 측정합니다. 입력 벡터 X가 주어졌을 때 트루클래스에 대한 entropy가 얼마나 높은지를 측정하는 것 입니다. x가 트루클래스로 분류되기 위해 feature가 얼마나 부족한지, 트루클래스로 분류되기 ㅇ위해 필요한 feature의 양을 나타냅니다. entropy가 낮을수록 선형적으로 분류가 잘 된다고 생각하시면 됩니다.
basline을 사용하던, stylegna을 사용하던 항상w를 사용하여 interpolation하 ㄹ때가 disentangle이 보다 보장되어있다라고 생각할 수 있습니다. w가
latent space
 출처 :StyleGAN paper
출처 :StyleGAN paper
- A : PGGAN.
- B : PGGAN에서 interpolation method를 바꿔 bilinear up/down sampling, longer training, tuned hyperparameters해서 성능을 끌어올린 버전
- C : mapping network, AdaIN → the network no longer benefits from feeding the latent code into the first convolution layer.
- D : removing tranditional ipnut layer, 4x4x512 constant tensor input → AdaIN만으로도 스타일을 잘 전달할 수 있다.
- E : noise input(B block)
- F : mining regularization
결과를 보면 고화질의 퀄리티 높은 이미지가 생성되는 것을 확인할 수 있습니다. 논문에서 잘 생성된 결과 이미지를 sampling하기 위해서 truncation trick을 썻다고 나와있습니다.
Truncation trick
truncation trick이란? : GAN을 학습완료한 뒤, 학습된 분포에서 좀 더 잘 나온 이미지들을 sampling하는 trick입니다. 예를 들어 사람얼굴에 대한 데이터셋의 분포라면 사람 얼굴 이미지는 대부분 평균에 몰려있을 것이고, 평균에서 멀어질수록 사람 얼굴과는 거리가 먼 이상한 이미지 일 것입니다. GAN으로 학습된 분포 역시 target distribution에 맞춰 학습되었을 것이기 때문에, 학습된 분포의 평균에서 sampling하면 좋은 퀄리티의 이미지를 생성할 수 있을것입니다.
가능하면 density가 높은 곳에서 부터 뽑는 것이 퀄리티 좋은 이미지가 나올테니까, 하나의 latent vector가 latent space에서 중간에 가까운 값이 될 수 있도록 잘라내기(trucation)를 수행해서 결과를 얻도록 만드는 것입니다. 즉 의 중간값을 찾아서 그 중간값 주변에서 sampling하는 것입니다.
StyleGAN에서는 space에 맞추어져있지만, space에서 이미지를 바로 생성하는 다른 GAN에서는 에 적용할 수 있습니다.
ψ값dl 0에 가까울수록 평균이미지로 가는 것이고 ψ가 1이면 truncation을 하지 않은 것 입니다. ψ를 -값으로 한다면, ψ를 +값으로 하여 samlping한 이미지에서 나타나는 high-level attribute들의 (often) 반대로 나타나는 것을 확인할 수 있습니다.
안경,나이,머리길이 등 가끔 성별도 해당됩니다. 아주 재미있는 현상인것같네요
(퀄리티 좋은 이미지를 sampling하기 위한 trick이므로, metric으로 결과비교(FID)할 때에는 이 트릭사용하지 않습니다.)

안녕하세요! 상세한 설명 덕분에 이해하는데 도움이 많이 되었습니다 감사합니다 :) 포스팅을 보다가 문득 궁금한 점이 생겼는데, 포스팅 중간 즈음에 있는 내용인데요, content를 constant tensor로 설정을 하고 mapped tensor w가 style로 들어간다는 내용입니다.
여기서 content의 tensor를 상수값으로 어떻게 설정을 할 수 있는건지 잘 이해가 안갑니다. 예를들어, content 이미지는 일반 남성의 사진, style이미지에는 디즈니 픽사 애니메이션에 기반한 남성의 사진이라고 할 때, style과 content 이미지 모두의 latent z는 각 도메인(픽사,실제사진)에 기반한 학습된 상수값일까요??