[논문 리뷰] An overview of multi-task learning in deep neural networks
deep neural network를 사용한 MTL에 대해 전반적으로 설명하고
2절에서는 다양한 관점에서 MTL에 동기를 부여할 것이며, 3절에서는 딥러닝에서 MTL에 가장 많이 사용되는 두가지 방법을 소개할 것이다. 4절에서는 MTL이 실제로 작동하는 이유를 할께 설명하는 매커니즘이고 5절에서는 MTL문헌에 대해 논의하는 몇가지 context를 제공할 것이며 6절에서는 deep neural network에서 MTL에 대해 최근에 제안된 더 강력한 방법을 소개할 것입니다. 마지막으로 일반적으로 사용되는 보조 작업 유형에 대해 이야기하고 7절에서는 MTL에 좋은 보조 작업을 만드는 것이 무엇인지 논의합니다.
머신러닝 작업 시: 하나의 모델 훈련 / 복수의 모델 훈련 후 앙상블 → 이후 fine tuning
어지간하면 위 방법으로 목표 성능 도달 가능하지만 해당 모델의 도움이 되었을 수도 있는 연관된 데이터 활용 어려움
문제 해결 위해 Multi Task Learning (MTL) 연구됨
처음 배운 유의미한 기술을 활용하여 이후 더 복잡한 기술을 연마할 때 사용합니다.
우리는 MTL을 유도적인 전이(inductive transfer)의 형태로 볼 수 있습니다.
- Two MTL methods for Deep Learning
3.1 Hard Parameter Sharing for Multi-Task Learning in Deep Neural Networks.
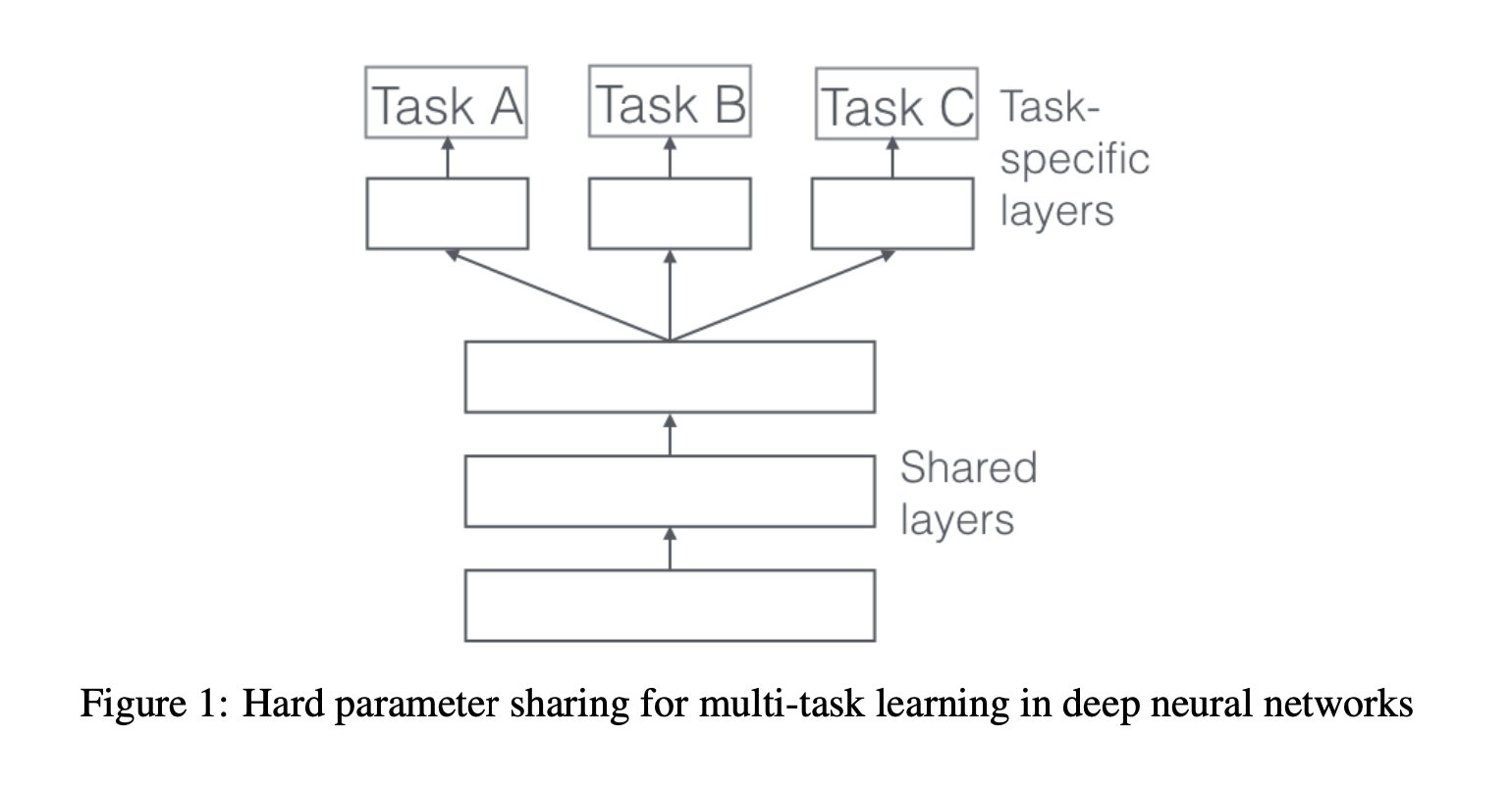
해당 방법은 MTL에서 가장 많이 사용되는 방법입니다.
적용법도 단순합니다. 모든 Task에 동일한 은닉층을 공유합니다.
이때, 각 Task별로 별도의 Task-Specific Layer도 유지합니다.
Hard Parameter Sharing은 과적합의 위험을 크게 줄여줍니다.
사실, 동시에 수행되는 Task가 많아질수록 과적합의 위험은 줄어듭니다.
모든 Task를 만족하는 representation을 Capture하는 것이 매우 어렵기 때문입니다.
3.2 Soft Parameter sharing for Multi-Task Learning in Deep Neural Networks
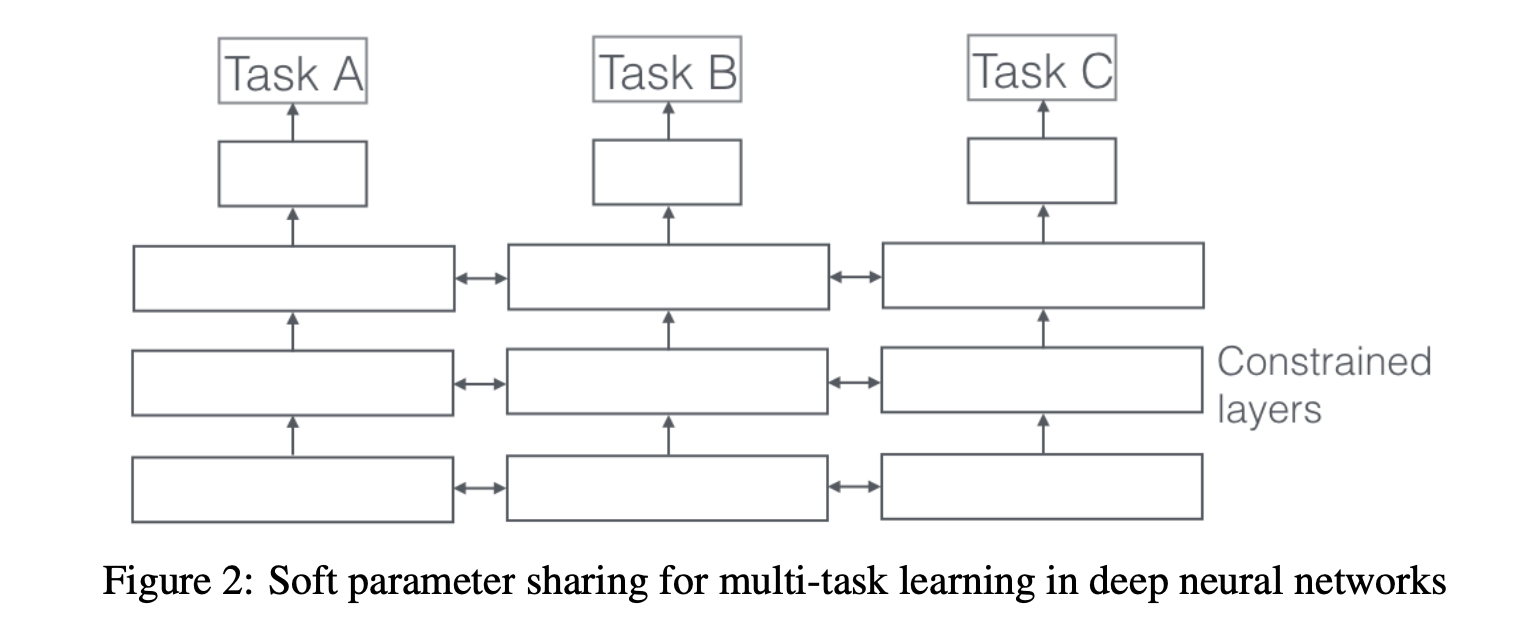
각 Task마다 각자의 모델과 그에 해당하는 Parameter를 보유하고 있습니다.
각각의 레이어 비슷해질 수 있도록 L2 Distance를 사용.
4. Why does MTL work?
4.1 Implicit data augmentation
4.2 Attention Focusing
4.3 Eavesdropping
4.4 Representation Bias
4.5 Regularization
-
MTL in non-neural models
5.1 Block-Sparse Regularization
5.2 Learning Task Relationships -
Recent work on MTL for Deep Learning
6.1 Deep Relationship Network
6.2 Fully-Adaptive Feature Sharing
6.3 Cross-stitch Networks
6.4 Low supervision
6.5 A Joint Many-Task model
6.6 Weighting losses with uncertainty
6.7 Tensor factorisation for MTL
6.8 Sluice Networks
6.9 What should I share in my model? -
Auxiliary tasks
7.1 Related Task
7.2 Adversarial
7.3 Hints
7.4 Focusing Attention
7.5 Quantization smoothing
7.6 Predicting Inputs
7.7 Using the future to predict the present
7.8 Representation learning
7.9 What auxiliary tasks are helpful?
ref) https://velog.io/@hyominsta/An-Overview-of-Multi-Task-Learning-in-Deep-Neural-Networks-%EB%85%BC%EB%AC%B8-%EA%B3%B5%EB%B6%80
https://velog.io/@sksmslhy/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-An-overview-of-multi-task-learning-in-deep-neural-networks
정리) 머신러닝에서는 원래 하나의 모델을 훈련하거나 복수의 모델을 훈련한 후 앙상블, 그리고 파인튜닝을 거치는데 이 방법으로 한계가 존재한다거나 해당 모델의 도움이 되었을 수도 있는 연관된 데이터 활용 어려워 문제 해결 위해 Multi Task Learning (MTL) 연구되었습니다. MTL은 유의미한 기술을 활용하여 이후 더 복잡한 기술을 연마할 때 사용할 수 있다는 motivation을 가지며 inductive transfer의 형태로도 볼 수 있습니다. 딥러닝에서 MTL에 가장 많이 사용되는 두가지 방법은 Hard Parameter Sharing(모든 Task에 동일한 은닉층을 공유합니다.
이때, 각 Task별로 별도의 Task-Specific Layer도 유지합니다.,모든 Task를 만족하는 representation을 Capture하는 것이 매우 어렵기 때문에 Task가 많아질수록 과적합의 위험은 줄어듭니다.) 과 Soft Parameter sharing 방식(각 Task마다 각자의 모델과 그에 해당하는 Parameter를 보유하고 있습니다.
각각의 레이어 비슷해질 수 있도록 L2 Distance를 사용.)이 있으며 각각 그림에서 보이는 것과 같은 방식이 있습니다. 그간 hard parameter sharing을 주로 사용했었지만 공유할 항목을 학습하는 learning what to share 하는 방식이 최근에는 유망하다고 보여지고 있다고 논문에서는 언급하며 6절에서 case마다 적용 될 수 있는 여러 방법들을 언급했습니다. 이 외에 논문에서 설명하는 MTL에 대해서는 MTL이 실제로 작동하는 이유(Implicit data augmentation, Attention Focusing,Eavasdropping...)와 Linear Model, Kernel Model, Bayesian Model에 대한 MTL,MTL에 좋은 보조 작업을 만드는 것이 무엇인지에 대해서도 언급했습니다.즉 해당 논문에서는 MTL의 역사와 동기 및 최근의 deep learning을 위한 MTL 연구를 검토했습니다.
"An Overview of Multi-Task Learning in Deep Neural Networks" 논문의 주요 기여는 다음과 같습니다:
멀티 태스크 러닝(MTL) 방법론 정리: 논문은 딥 러닝에서 MTL을 구현하는 두 가지 주요 방법인 하드 파라미터 공유(hard parameter sharing)와 소프트 파라미터 공유(soft parameter sharing)에 대해 자세히 설명합니다. 이를 통해 각 방법의 장단점을 이해할 수 있도록 돕습니다 (ar5iv) (DeepAI).
MTL의 이론적 배경 제공: 논문은 MTL의 역사적 배경과 최근 발전된 내용을 포괄적으로 다룹니다. 이는 독자들이 MTL의 발전 과정을 이해하고, 현재의 기술 동향을 파악하는 데 도움을 줍니다 (ar5iv) (Papers with Code).
작업 관계 학습 방법 소개: 논문은 작업 간 관계를 학습하는 다양한 방법을 소개합니다. 예를 들어, 작업 간 클러스터링을 통해 관련 작업들 간의 정보를 효율적으로 공유하는 방법과, 그룹 라소(group lasso)와 같은 규제 기법을 활용하는 방법 등이 포함됩니다 (ar5iv).
실제 적용을 위한 가이드라인 제공: MTL을 실제 문제에 적용할 때 유용한 가이드라인을 제공합니다. 특히, 보조 작업(auxiliary tasks)을 선택하는 기준과 MTL의 장점 및 단점에 대해 논의합니다 (DeepAI).
이 논문은 딥 뉴럴 네트워크에서의 MTL을 이해하고 적용하는 데 있어 중요한 참고자료가 될 수 있습니다. 자세한 내용은 이 링크에서 확인할 수 있습니다.
