[논문리뷰] DETR : End-to-End Object Detection with Transformer
학습 및 참고할 블로그> https://herbwood.tistory.com/26
몇줄 정리>
기존의 object detection 방법론은 가진 pre-defined anchor를 사용합니다. 따라서 이로 인해 예측한 bounding box와 ground truth의 관계가 many-to-one이 됩니다. 따라서 redundant한 예측을 제거하기 위해 NMS(Non Maximum Suppression)과 같은 post-processing 과정이 반드시 필요합니다.

DETR은 object detection을 set prediction task로 정의하여 prediction과 ground truth 사이의 일대일 matching을 수행했습니다.이를 통해 redundant prediction을 효과적으로 감소시켜 post-processing 과정이 없는 end-to-end 프레임워크를 제안하였습니다.

이 과정에서 encoder-decoder 구조의 Transformer를 활용함으로써 (입력 token 사이의 pairwise interaction과 global reasoning을 통해)준수한 성능을 보였습니다.
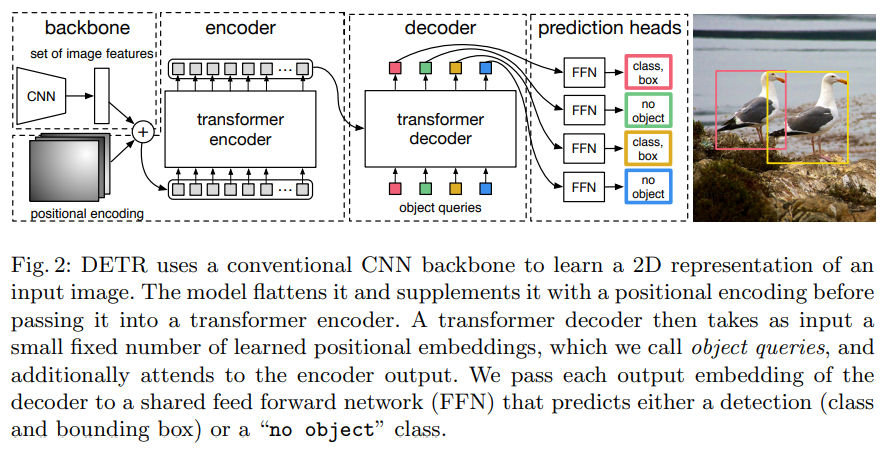
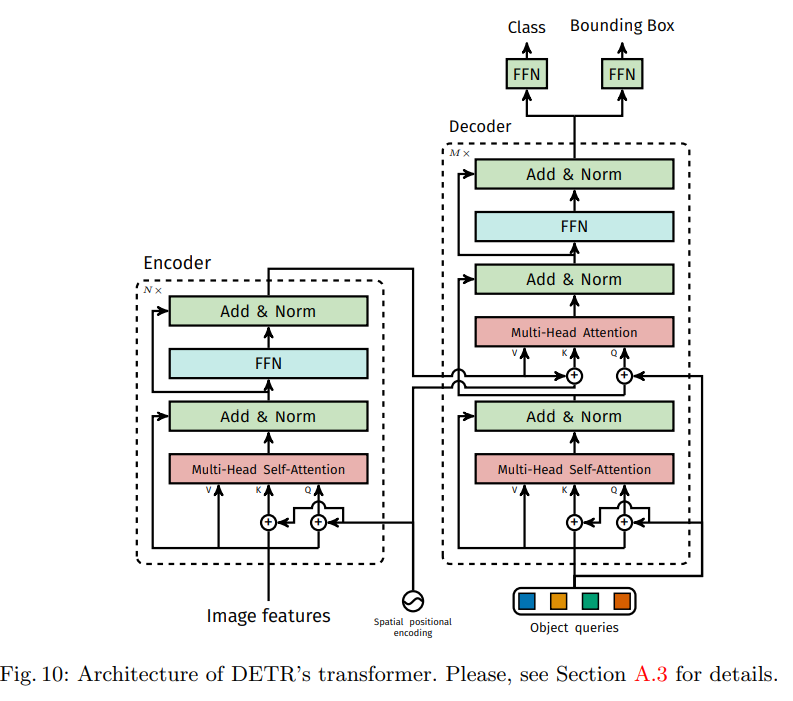
DETR은 1) CNN backbone 2) Transformer encoder와 decoder 3) FFN(Feed Forward Network)로 구성되어 있습니다. CNN backbone인 ResNet에 입력하여 feature map 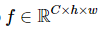
추출합니다.
각 encoder layer는 multi-head self-atttention module과 feed forward network(FFN)으로 구성되어 있으며 encoder layer 입력 전에 입력 embedding에 positional encoding을 더해줍니다.
기존 Transformer decoder는 (masking을 통해 다음 token을 예측하는) autoregressive 방법을 사용하는 반면, DETR의 decoder는 N개의 object에 대한 정보를 한번에 출력합니다. 또한 Decoder 또한 embedding으로 object queries라고 불리는 learnt positional encoding을 사용합니다.
FFN은 이미지에 대한 class label과 bounding box에 좌표(normalized center coordinate, width, height)를 예측합니다.
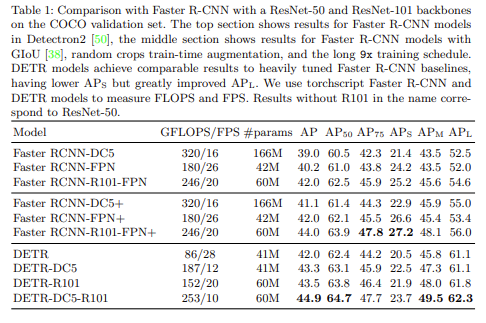
하지만 실험에서 볼 수 있듯이 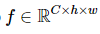
self-attention을 통한 global information(전역 정보)를 활용함으로써 크기가 큰 객체를 Faster R-CNN보다 훨씬 잘 포착하지만, 여러 크기의 anchor를 사용하지 않기 때문에 다양한 크기, 형태의 객체를 포착하지 못하며 크기가 작은 객체에 대해서는 잘 포착하지 못하는 것을 확인 할수 있었습니다. 또한 하나의 예측 bounding box를 ground truth에 matching하기 때문에 converge하는데 훨씬 긴 학습시간을 필요로 합니다. 그럼에도 불구하고, 본 논문에서 제안한 DETR은 Faster R-CNN과 비슷한 성능을 보이면서도 post-processing을 필요하지 않아 end-to-end로 학습이 가능하다는 점에서 큰 의의를 가진다고 할 수 있습니다.
