[논문리뷰] Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
An Overview of Multi-Task Learning in Deep Neural Networks 논문에서 언급했던 method 중 Weighting losses with uncertainty을 보면 sharing 구조를 학습하는 대신 각 task의 불확실성 고려하여 orthogonal한 독립적인 approach를 가짐
task 독립적인 불확실성을 가지고 gaussian likelihood를 최대화하는 multi task loss func를 통해 각 task의 weight를 조정한다고 설명을 했었다.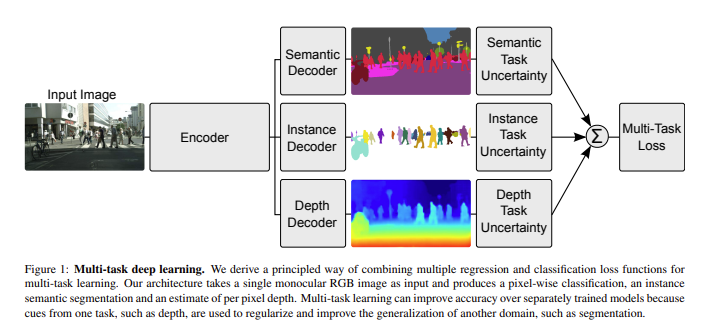
따라서 이 method에 대해서 간단하게 설명하고 "Multi-Task Learning Using Uncertainty to Weigh Losses
for Scene Geometry and Semantics"논문에서 언급하는 contribution을 언급하자면 다음과 같이 설명할 수 있다.
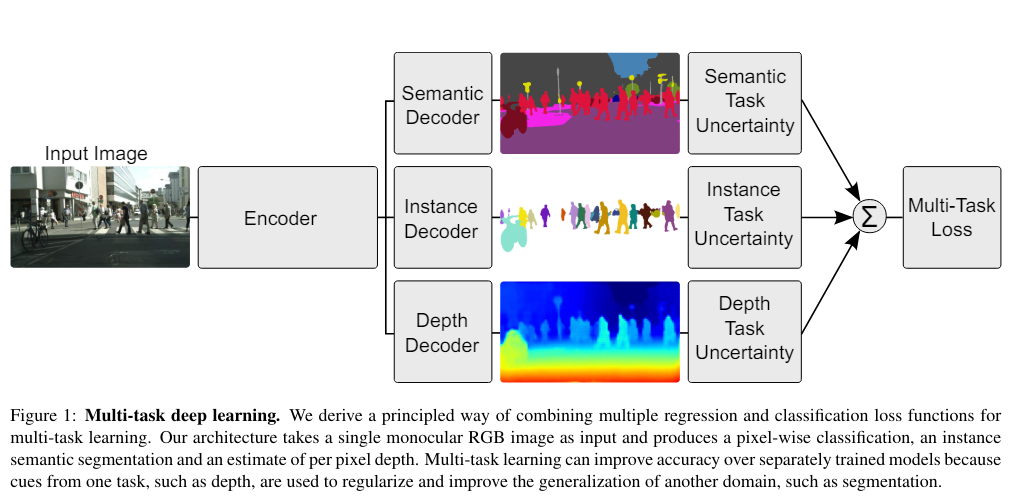
그림에서 보이는 것과 같이 multi-task learning 시 loss는 여러 task에 대한 sum으로 주게 된다. 이때 loss를 주는 비율을 보통 사용하는 것처럼 hyper-parameter로 주는 것과 다르게 이 논문에서는 Uncertainty를 사용하여 weight를 learning하게 해 줄 수 있는 방법을 제시했다.
각 loss의 sum을 똑같은 비율로 넣어서 학습할 수도 있겠지만 다르게 해서 넣을 수도 있다. 비율에 대한 개수가 그러면 hyper-parameter가 task 개수만큼 많아지므로 좋지 않다. 그래서 논문은 uncertainty를 사용하여 각 task loss의 weight를 주려한다. 이때 언급하는 Uncertainty는 Aleatoric Uncertainty (Data Uncertainty) : 데이터에 내재되어 있는 에러에 대한 불확실성. (ex. sensor noise, motion noise 등) 이고 이는( Epistemic Uncertainty (Model Uncertainty) : 모델에 내재되어 있는 에러에 대한 불확실성과 다른 카테고리 인것을 알 수 있다.
Aleatoric Uncertainty를 예를 들어 설명하면 동전던지기나 가위바위보와 같이 데이터가 아무리 주어져도 예측하기 림든것들을 말하는데 이 또한 2개로 나눌 수 있는 것이
1) Data-dependent or Heteroscedastic uncertainty
2) Task-dependent or Homoscedastic uncertainty
첫 번째 uncertainty는 원래 알고 있던 개념을 그대로 따라 input data의 noise에 반응하고 model output으로 예측할 수 있는 값이다.
두 번째 uncertainty는 입력 데이터의 noise에 영향을 받지 않고 각 task 별로 다른 값을 가지게 되는 값이다. 그러므로 이 논문은 두 번째 uncertainty를 이용한다.
두 번째 uncertainty는 model output으로 predict 할 수 있는 값은 아니고 따로 learnable parameter로 두어 update 한다. mse를 사용하고 output distribution이 gaussian일 경우 식은 다음과 같다.
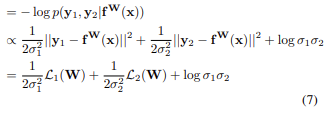
σ1,σ2σ1,σ2\sigma{1}, \sigma{2}가 각 task별 uncertainty를 나타내는 learnable parameter이고 전체 loss를 minimize 할 때 함께 update 된다. 위의 loss 식은 본래 aleatoric uncertainty를 loss로 줄 때 식과 같다. 각 uncertainty가 크면 해당 task loss는 update에 영향을 덜 끼치게 된다 (12σ212σ2\frac {1} {2\sigma^{2}}이 L(W)에 곱해지므로). 한편 σσ\sigma가 무작정 커져서 Loss가 작아지는 것을 원하진 않으므로 뒤에 regularization term으로 logσlogσlog\sigma가 더해지게 된다.
식에 대해서 좀 더 설명하면 다음과 같습니다.

논문에서 언급하는 contribution은 다음과 같다.
1. a novel and principled multi-task loss to simultaneously learn various classification and regression losses
of varying quantities and units using homoscedastic
task uncertainty,
2. a unified architecture for semantic segmentation, instance segmentation and depth regression,
3. demonstrating the importance of loss weighting in
multi-task deep learning and how to obtain superior
performance compared to equivalent separately trained
models.
1. 동종 확률적 작업 불확실성을 사용하여 다양한 양과 단위의 다양한 분류 및 회귀 손실을 동시에 학습할 수 있는 새롭고 원칙적인 다중 작업 손실,
2. 의미론적 분할, 인스턴스 분할 및 깊이 회귀를 위한 통합 아키텍처,
3. 다중 작업 딥 러닝에서 손실 가중치의 중요성과 동등한 개별 학습 모델과 비교하여 우수한 성능을 얻는 방법을 입증합니다.
챗gpt가 알려준 contribution
Uncertainty-Weighted Loss Function: 이 논문은 multi-task learning에서 각 task의 중요도를 자동으로 조절할 수 있는 새로운 손실 함수(loss function)를 제안합니다. 이 손실 함수는 각 task의 불확실성(uncertainty)을 고려하여, 각 task의 손실에 가중치를 부여합니다. 이를 통해, task 간의 불균형 문제를 해결하고, 최적의 성능을 얻을 수 있습니다.
Joint Optimization for Scene Geometry and Semantics: 이 논문은 장면 기하(Scene Geometry)와 의미 정보(Semantics) 간의 joint learning을 수행합니다. 두 가지 task를 동시에 최적화함으로써, 하나의 모델에서 두 가지 task를 모두 잘 수행할 수 있는 모델을 개발하였습니다. 이를 통해, 장면 이해의 여러 측면을 동시에 학습할 수 있는 효율적인 방법을 제시합니다.
Practical Performance Improvement: 이 방법은 다양한 데이터셋에서 실제로 성능 향상을 보여줍니다. 특히, 기존의 multi-task learning 방법론들과 비교하여, 제안된 불확실성 가중 방법이 더 나은 결과를 제공한다는 것을 실험적으로 입증하였습니다.
General Applicability: 이 방법은 특정 task에 국한되지 않고, 다양한 multi-task learning 문제에 적용될 수 있는 일반적인 접근법으로 제안됩니다. 즉, 여러 task를 동시에 학습해야 하는 다양한 상황에서 적용 가능하다는 장점이 있습니다.
출처) https://simpling.tistory.com/40 [simpling:티스토리]
https://analytics4everything.tistory.com/281
정리)
아래의 이미지 또한 overview...paper에서 언급한 방법으로 한 이미지로부터 서로 다른 3가지의 테스크을 수행하고, 3테스크의 손실함수를 합하여 최적화하는 일반적인 방법론입니다. 당연히 하나의 task만을 사용하는 것 보다 더 높은 성능을 보이고 있습니다. 그런데 이때 각각의 task에 대해서 어떻게 가중치를 주어야 할까 하는 것에 대해 보통 이 가중치의 비율을 휴리스틱하게 여러번의 실험을 하면서 실험적으로 구하는데 이때 비용이 너무 많이 들어서 이를 해결하기 위해 MTL시에 가중치를 불확실성 기반으로 최적화 하는 방법을 제안하였습니다. 이때 말하는 불확실성에 대해서 보면 논문에서 언급하는 uncertainty는 Aleatoric uncertainty로 동전 던지기나 가위바위보 같이 데이터가 아무리 주어져도 예측하기 힘든 것들을 말하는데 이중에서도 data dependent한 heteroscedastic uncertainty가 있고, Task dependent한 homoscedastic uncertainty로 나눌 수 있는데 논문에서의 uncertainty는 두번째 경우로 입력 데이터의 noise에 영향을 받지 않고 각 task 별로 다른 값을 가지게 되는 값이며 model의 output으로 predict할 수 있는 값이 아니고 따로 learnable한 parameter를 두어 update하는 것이라고 부가적으로 설명할 수 있으며,
 논문에서 언급한 것 처럼 mse를 사용하고 output distribution이 gaussian일 경우의 method를 식과 함께 보면 다음과 같습니다.
논문에서 언급한 것 처럼 mse를 사용하고 output distribution이 gaussian일 경우의 method를 식과 함께 보면 다음과 같습니다.

Q.data dependent한 경우는 어떤 경우>
원래 알고 있던 개념을 그대로 따라 input data의 noise에 반응하고 model output으로 예측할 수 있는 값이다.
Q.experiments를 통해 알 수 있었던 점?
저자들이 grid search로 찾은 optimal weights보다 성능이 좋았던 것은 물론이고, 1:1:1의 비율로 준것 보다도 훨씬 성능이 좋았다.
Q.main contribution?
particularly in tasks related to scene geometry and semantics과 같은 uncertainty가 반영되는 task를 수행할때 즉, 멀티태스크 학습 설정에서 작업 불확실성을 활용하여 손실 함수를 자동으로 동적으로 가중하는 방법을 개발한 것입니다. 이 접근 방식은 모델이 다양한 복잡도와 노이즈 수준의 작업을 공동으로 학습하는 능력을 향상시킵니다.
