[논문 리뷰] Task-Aware Variational Adversarial Active Learning
Method) active learning은 제한된 label budgett이 주어졌을 때, 라벨링 되지 않은 데이터로 부터 annotation할(labeling할 샘플을 선택) 샘플을 선택하는 것이고 contribution은 기존 VAAL보다 어렵고 영향력 있는 데이터 포인트 산출이 가능하고,
라벨링된 데이터와 라벨링되지 않은 데이터 분포를 모두 고려하여 task-agnostic VAAL을 변형하는 것,ranking loss prediction 이용, RankCGAN을 이용하여 VAAL에 normalize된 ranking loss정보를 임베딩.



정리)
TA-VAAL은 task-aware한 방식과 task-agnostic한 방식을 결합한것으로
TA-VAAL은 라벨링된 데이터와 라벨링되지 않은 데이터 분포를 모두 고려하여 task-agnostic VAAL을 변형한 것입니다. ranking loss prediction을 이용하는데, RankCGAN을 이용하여 VAAL에 normalize된 ranking loss정보를 임베딩해주는 과정을 거칩니다.
기존에 있던 VAAL모델과 비교했을 때 추가적으로 fine-grain된 상대적 rank정보를 포착하여 더 영향력 있고,정보량이 많은 데이터에 라벨링을 집중시킨다는 특징이 있습니다.
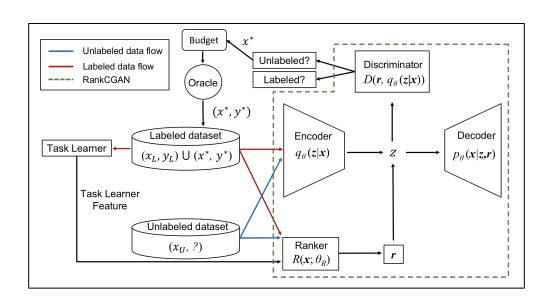
좀 더 자세히 보면 RankCGAN부분운 ranker와 encoder,decoder,discriminator의 부분을 보면 알 수 있듯이 ranker에서 loss의 상대적인 ranking을 예측하고 나온 normalized loss ranking information r을 VAAL의 decoder와 discrimiator로 전달해서 unlabel된 data pool로부터 샘플을 선택하게 됩니다.여기서 ranker를 통한 예측방법인 Ranker를 Learning loss의 LPM과 비교해서 보면 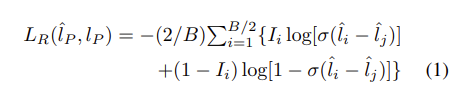 LPM에서는 정확한 loss값 즉, 절대적인 값을 예측하는 것에 초점을 맞춘것과 다르게 Ranker에서는 loss의 ranking을 예측하는 것,즉,상대적인 비교에 초점을 둔 것을 알 수 있습니다.
LPM에서는 정확한 loss값 즉, 절대적인 값을 예측하는 것에 초점을 맞춘것과 다르게 Ranker에서는 loss의 ranking을 예측하는 것,즉,상대적인 비교에 초점을 둔 것을 알 수 있습니다.
또한 TA-VAAL의 학습이 어떻게 이루어지는지를 보면

n=1일때 즉, epoch가 1일때는 labeled data rl과 unlabeled data ru가 uniform distribution로부터 랜덤하게 초기화 되고, n이 1이 아닐때 ranker를 통한 값을 update하며 Total loss를 계산합니다. 그리고 n이 0.8N보다 작거나 같을때는 Ltotal이라는 새로운 loss를 반영하여서 task learner 세타 t와 Ranker세타r이 업데이트 되고 0.8보다 클 때는 task learner와 ranker의 update를 skip하고, Lvae를 minimizing하는 계산을해서 VAE의 encoder를 update합니다. 그리고 Ld즉,discriminator loss를 minimizing해서 discriminator를 업데이트 합니다.그리고 학습이 끝나면 학습된 모델을 사용하여 레이블이 지정되지 않은 데이터 풀에서 레이블을 지정할 샘플을 선택합니다.
