[논문 리뷰]ACTIVE LEARNING FOR CONVOLUTIONAL NEURAL NETWORKS: A CORE-SET APPROACH
Active learning에 CNN모델을 통해 batch sampling적용.
Uncertainty or optimization based가 아닌 discrete optimization based방법
Active learning을 core-set selection problem으로 정의하고, k-Center greedy를 활용하여 core-set을 선택.
unlabeled data로 부터 몇개의 data point를 선택할 것 인가? Query(budget),CNN algorithm이 learning algorithm:A ,s:가지고 있는 label이 달린 dataset을 의미

n은 label이 안달려있는 데이터 셋까지를 의미.

정리)
Active learning을 core-set selection problem으로 정의하고, k-Center greedy를 활용하여 core-set을 선택하는 방법을 취한것으로
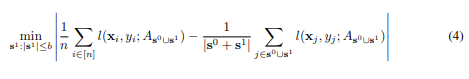
모델의 Future Expected Loss는 다음 식과 같이 분리시킬 수 있는데 generalization error + training error + core-set loss로 이루어져있는데 generalization error는 이미 CNN 모델이 일반화가 잘 된다는 것으로 Future Expected Loss 중 Generalization Error와 Training Error를 0으로 가정할 수 있고 이러한 가정 덕분에 Future Expected loss는 core-set loss만 해결하면 됩니다.따라서 core-set loss를 재정의하면 다음과 같은 식으로 변환이 되며 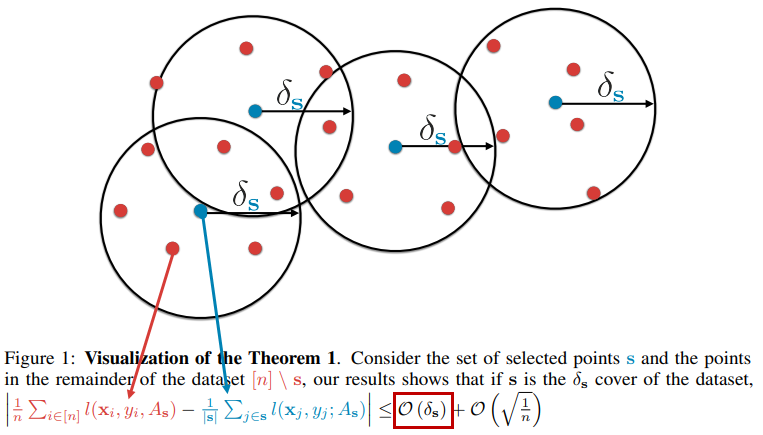
Subset에서의 모델 성능과 전체 데이터 셋에서의 성능 차이를 최소화하는 문제가 됩니다.

그에 대해서 구하는 방법으로 앞서 말한 것 처럼 k-Center greedy를 활용하여 core-set을 선택하는 방법을 사용하였는데 빨간 색 점과 같은 데이터를 모두 cover할 수 있는 가장 작은 거리 델타s를 갖는 K개의 점을 찾는 것으로
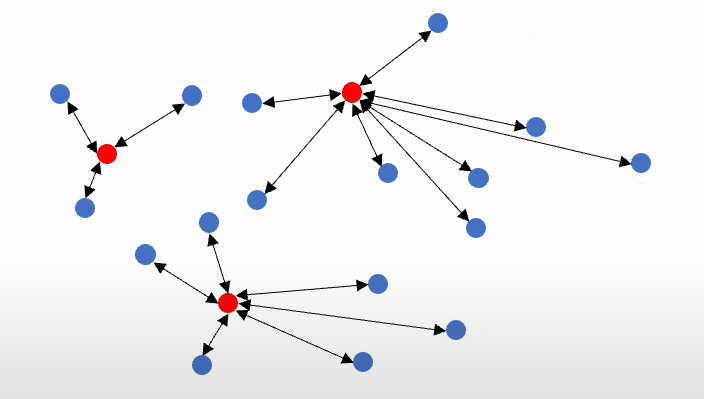
input으로는 각 데이터 포인트 xi와 label이 달려있는 초기 데이터셋 so, 그리고 몇개를 뽑을건지에 대한 query즉 budget b가 들어갑니다. labeled datapoint인 xi와 unlabled datapoint인 xj간의 거리가 작은 unlabled datapoint들을 먼저 찾아주고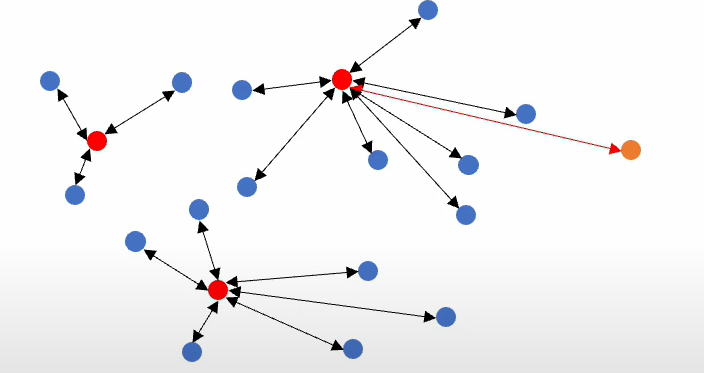
그중에서 가장 거리가 큰애를 선택하는 과정으로 반복을해서 데이터 셋에 추가를 시켜줍니다.
그리고 추가로 언급한 알고리즘으로 좀 더 outlier에 견고하게 고안한 알고리즘은 다음과 같은데

앞선 k-center-greedy로 계산된 결과를 가져와서 lb,lower bound와 ub,upper bound를 만들어 주고, 이 lb와 ub가 동일해 질때까지 feasiblity를 고려를 해서 update를 수행을 해줍니다.
출처) https://www.youtube.com/watch?v=m3TlBL4lzR4
https://kmhana.tistory.com/6
