[논문 리뷰]Unsupervised Domain Adaptation by Backpropagation
모델을 학습할때 훈련 데이터인 소스 도메인에서만 성능이 좋고 실제적용 데이터인 타겟 도메인에서는 성능이 나쁠때가 많은데 이러한 source(학습) 도메인과 target 도메인 차이를 줄여서 target domain에 대한 성능을 높이고자 할 때 필요한 것이 Domain Adaptation입니다. 본논문은 Unsupervised Domain Adaptation으로 주요 목표는 라벨이 없는 타겟 도메인의 데이터를 사용할 수 있으면서도, 소스 도메인의 라벨이 있는 데이터로 훈련된 모델을 효과적으로 적용하는 것입니다.
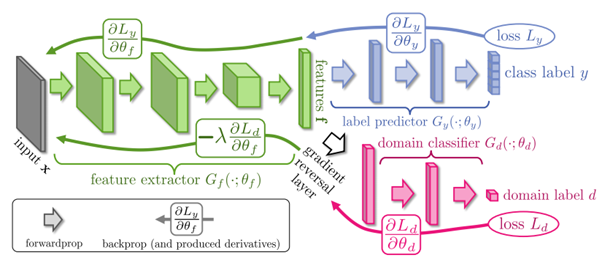
모델의 구조는 다음과 같습니다.
feature extractor는 초록색 부분에 해당하며 이미지 데이터의 feature mapping을 수행합니다.
label predictor는 파랑색 부분에 해당하며 소스 도메인에서 학습된 라벨을 예측하는 역할을 합니다.
domain classifier는 핑크색 부분에 해당하며 이미지가 Source domain에서 왔는지, Target domain에서 왔는지 구별하도록 학습합니다.
또한 Gradient Reversal Layer라는 간단한 구조를 도입하여 역전파 과정에서 domain classifier의 gradient를 반전시켜서 특징공간에서 도메인 차이를 줄일 수 있도록 하였습니다. 데이터의 흐름을 설명하여 모델의 구조를 추가적으로 설명하면 입력 데이터 𝑥는 먼저 feature extractor 를 통해 저차원 특징 벡터 𝑓로 변환됩니다. (이 특징벡터 f는 소스 도메인과 타겟 도메인 모두에서 학습되며 두 도메인에서 domain invariance합니다.) 소스 도메인의 라벨
𝑦를 예측하기 위해, 추출된 특징 𝑓는 label predictor에 의해 라벨 yhat로 변환됩니다.
도메인 loss Ld는 소스 및 타겟 도메인의 도메인 분류 오차를 나타내며, 이를 최소화하여 두 도메인의 특징 분포를 구분합니다.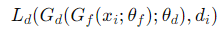
이때 di가 0이면 소스도메인 1이면 타겟도메인 입니다.또한 이 과정에서 GRL은 정방향에서는 입력을 그대로 전달하지만 역방향에서는 그래디언트를 반전시켜 domain classifier와 feature extractor간의 학습을 반대로 만듭니다. 이는 또한 도메인 간 차이를 최소화 하는 방향으로 학습되도록 유도합니다.
그리고 object function에서 모델의 전체 목표는 label prediction loss Ly를 최소화하면서 domain classifier loss Ld를 최대화하도록 하여 라벨 예측성능은 유지하되 domain invariance하도록 합니다. 아래 식은 위에것은 정방향일때의 object함수이고 아래 것은 역방향시 −λI가 곱해진 함수 입니다.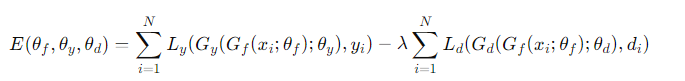
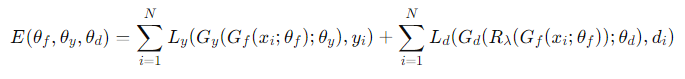
출처)https://benlee73.tistory.com/37
https://zooyeonii.tistory.com/21
https://hsgalaxy.tistory.com/entry/Unsupervised-Domain-Adaptation-by-Backpropagation-GRL-%EB%A6%AC%EB%B7%B0https://dhpark1212.tistory.com/entry/Unsupervised-Domain-Adaptation-by-Backpropagationin-ICML15
