[논문 리뷰]Learning Loss for Active Learning
정리)
Active learning은 원래의 Deep Learning은 매우 좋은 성능을 보이지만, 많은 Labeling 비용이 필요하다는 점을 바탕으로 전체 데이터셋중에서 중요한 데이터를 선별함으로써, 충분한 모델 경쟁력을 갖도록 한 것입니다.
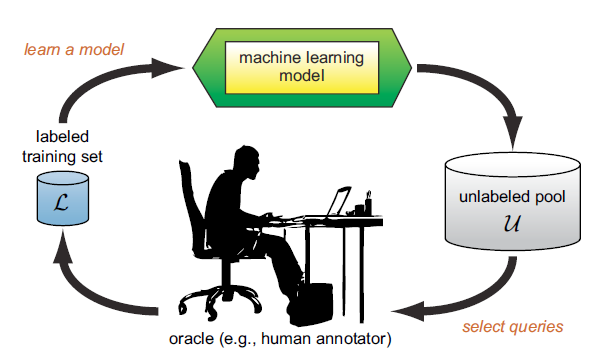
1. Learn a Model : 레이블링 된 데이터(L)를 활용하여, 모델 학습
-
Select Queries : 학습된 모델을 통해서, 레이블링 되지 않은 데이터(U)에서 선별
-
Human Annotator : 사람이 레이블링 - (Oracle 한 레이블링이라고 믿는다.. 아니기도 하지만...)
-
Training set : 새로 레이블링 된 데이터를 기존 dataset과 합친다.
-
목표 성능 도달까지 위에 과정(1~4)을 반복한다.
위와 같은 과정을 수행합니다.
그러면 Learning Loss for Active Learning은 무엇인지 보면
어떤 Task던지 어떤 Model 이던지, Loss를 통해서 학습하는데 이때 Loss를 예측(Prediction)할 수 있다면 Loss가 높은 데이터를 고르면 되지 않을까? 하는 생각으로 발전되어서 task-agnostic한 방법으로 Loss Prediction Module을 active learning에 부착하는 것을 제안하게 되었습니다.
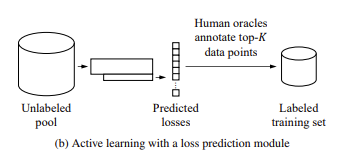
작은 박스가 Loss Prediction Module predicted loss를 sorting,top k개를 사람에게 보여주고 사람이 직접 annotation하고 그것을 labeled trainset으로 추가를 하게 하도록 하였습니다.이방법을 취하면 task에 dependent하지 않는다.
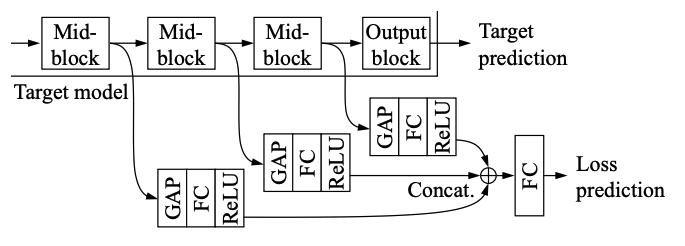
손실 예측 모듈은 대상 모델에 정의된 손실을 모방하는 방법을 배우기 때문에 작업에 구애받지 않는 active learning의 핵심입니다.
active learning을 위한 작업별 불확실성을 정의하는 엔지니어링 비용을 최소화하는 것을 목표로 합니다.
대상 모델의 mid-level block 사이에서 추출되는 입력으로 다층 피쳐 맵 h를 취합니다.
이러한 다중 연결을 통해 Loss Prediction Module은 Loss Prediction에 유용한 계층 간에 필요한 정보를 선택할 수 있다.
각 feature map은 GAP(Global Average Pooling layer) 계층과 FC(Fully-connected layer)을 통해 fixed dimension feature 벡터로 축소된다.
그 후 concat되고, fully-connected layer을 통과하여 예측 손실로 스칼라 값
lhat이 생성됩니다.
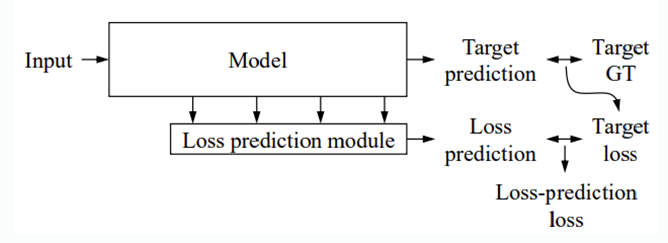
model에서 나오는 Target prediction과 labeled dataset에 존재하는 Target groundtruth를 이용하여서 Target loss를 구하고 여기다가 loss prediction moduel에서 loss의 prediction값이 나오게 되고 target loss를 학습하게 됩니다. 그리고 이 2개를 이용해서 loss-prediction하는 loss를 또 구하게 됩니다.그리고 최종적으로 Target loss와 Loss prediction loss를 합한 최종 loss를 가지고 multi task learning을 하면 됩니다. 이방법을 취하면 어떤 network나 어떤 task에도 적용할 수 있다는 장점이 있습니다.
(
MSEloss를 이용한 loss의 식이 효과가 없어서 ranking loss를 이용하여서 식을 재구성하였고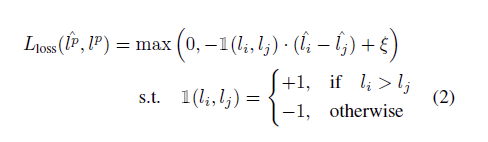
위 식과 같이 loss를 재구성하였고 최종 loss는 다음과 같습니다.
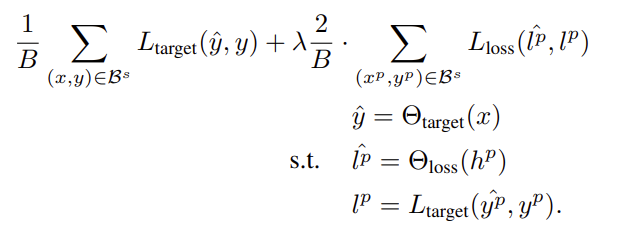
)
