[논문리뷰] ASFormer: Transformer for Action Segmentation
Transformer를 action segmentation task에 맞게 변형시킨 모델이라고 볼 수 있습니다. 기존 Transformer의 문제점을 크게 3가지 제시하여서 이에 대한 해결방안을 언급하며 논문을 전개해 나가고 있습니다.
abstract에서 말하는 ASFormer의 특징점으로는 (i) We explicitly bring in the local connectivity inductive priors because of the high locality of features. (features의 high locality로 인해 local connectivity inductive bias를 가져올 수 있습니다. 이는 action segmentation taks에서 적은 학습 데이터를 가지고 적절한 target function을 학습시킬 수 있다는 특징이 있습니다.)
(ii) We apply a pre-defined hierarchical representation pattern that efficiently handles long input sequences.(pre-defined hierarchical representation pattern을 적용할 수 있습니다. 따라서 긴 input sequences를 효율적으로 다룰 수 있습니다.)
(iii) We carefully design the decoder to refine the initial predictions from the encoder.(인코더로부터 initial predictions를 수정할 수 있는 디코더를 디자인했습니다.)
정리) 기존 vanilla transformer를 action segmentation task에 적용했을 때 생기는 주요 문제점 3가지와 이에 대한 해결방안을 들어 모델을 소개하였습니다. 3가지 이외에도 experiments에서 알 수 있는 몇가지 추가적인 변경사항을 들어 모델을 소개하겠습니다.
기존 vanilla transformer의 문제점은 다음과 같은 것들이 있는데 차례로 보면
1. Due to the small size of training sets, the lack of inductive biases of the vanilla Transformer becomes the bottleneck of applying it to action segmentation problem. (training sets의 작은 사이즈로 인해 inductive biases의 부족현상을 초래했고 따라서 action segmentation의 병목현상이 발생하였습니다.) 이에 대한 해결방안으로 . We bring in such strong inductive priors by applying
additional temporal convolutions in each layer(각 레이어에 추가적인 temporal convoluions를 적용하여서 강한 inductive priors를 가져왔습니다.)
2. Due to the deficit of self-attention for the long input video, the Transformer is hard to form an effective representation.(긴 입력 비디오에 대한 self-attention의 부족으로 transformer는 효과적인 표현을 형성하기 어렵습니다.이 말의 즉슨 비디오의 길이로 인해 의미있는 locations에 집중하도록 하는 적절한 weigths 학습이 힘들다는 것입니다.)이에 대한 해결방안으로 we constraint each self-attention layer with a pre-defined hierarchical representation pattern, (pre-defined hierarchical representation pattern을 각 self-attention layer들에 적용한다. 이는 low-level self-attention layer들을 local relation에 먼저 집중하도록 한 후, 점진적으로 high-level layer들 쪽으로 넓히는 것입니다.)
3. The original encoder-decoder architecture of the Transformer does not meet the refinement demand of action segmentation task. (기존 transformer의 encoder-decoder구조는 action segmenetation task의 refinement의 요구사항을 충족하지 못합니다.) 이에 대한 해결방안으로는 we propose a new design of the
decoder,The cross-attention mechanism in the decoder allows every position in the encoder to attend over all positions in the refinement process.(디코더에 cross-attention 구조를 넣습니다. 이는 인코더의 모든 포지션이 refinement 과정에 들어가도록 합니다.) 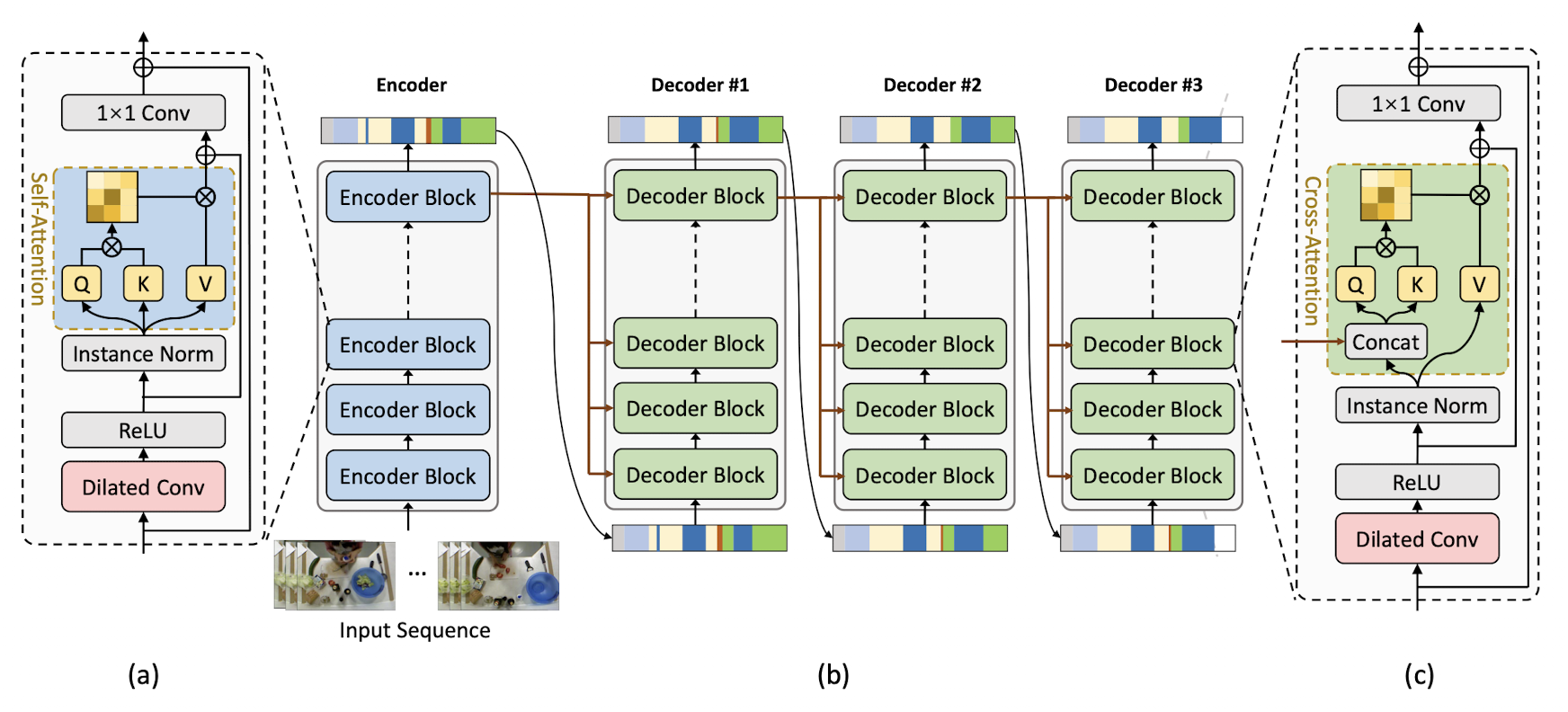
전체적인 ASFormer의 구조를 보면 다음 그림과 같습니다. (b)의 그림이 전체 구조로 인코더에서 video sequences를 받고 intial predictions를 내보냅니다. 이때 인코더는 Dilated convolution을 진행 한 뒤 pre-defined hierachical representation patterns가 적용된 self attention layer를 지나게 됩니다. 그리고 디코더에서 prediction을 input으로 받고 Dilated convolution을 진행 한 뒤 cross attention을 진행하게 됩니다.추가로 실험에서 성능과 효율성을 고려하여서 position encoding을 사용하지 않았다는 것과 multi-head attention을 적용하지 않았다는 특징이 있습니다.
출처) https://velog.io/@bo-lim/ASFormer-%EB%85%BC%EB%AC%B8-%EC%A0%95%EB%A6%AC-Action-Segmentation
https://arxiv.org/pdf/2110.08568
