[논문 리뷰]Learning to Learn Single Domain Generalization
우리는 학습시킬 수 있는 도메인은 하나인 반면, 여러 개의 새로운 도메인에서 잘 동작하는 모델을 만들고자 하는 model generalization에서 발생할 수 있는 Out-of-Distribution을 해결하고자 adversarial domain augmentation 방법을 이용합니다. 그리고 더 빠르고 바람직한 domain augmentation을 위해 meta-learning 기법과 Wassertein Auto-Encoder(WAE)를 이용합니다. 논문에서는 각각을 나누어 설명해주고 있는데 간단히 설명하면 adversarial domain augementation, 여기서의 목표는 소스 도메인으로부터 여러 개의 augmented 도메인을 만드는 것이다.그리고 만들어진 이 도메인은 모델이 보지 못한 타겟 도메인과 유사하게 만들어져야 합니다. Loss함수는 다음과 같으며 
Ltask는 분류 손실 (cross-entropy),Lconst는 소스 도메인과 증강된 도메인 간의 차이를 제한하는 제약 조건 (Wasserstein distance 사용).Lrelax는 증강된 도메인의 이질성을 더 크게 하기 위한 이완 조건.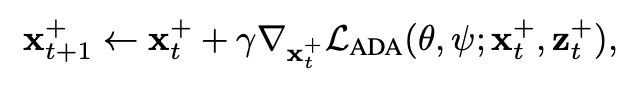
증강된 도메인 x+는 다음과 같이 생성됩니다.
(γ는 학습률)
소스 도메인과 증강된 도메인 간의 차이를 크게 만들어 일반화 성능을 향상시키기 위해, Wasserstein Auto-Encoder (WAE)를 사용하여 제약 조건을 이완합니다. 이로 인해 증강된 도메인이 소스 도메인과 더 멀리 떨어지게 됩니다.
WAE는 데이터를 임베딩 공간에서 재구성하여 소스 도메인의 분포를 학습합니다. 이를 바탕으로 증강된 도메인을 더 크게 이동시키도록 만듭니다.V(x+)는 증강된 데이터의 재구성값입니다.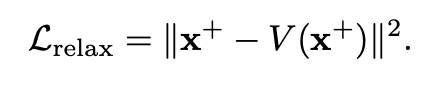
메타 학습 방식을 적용하여 소스 도메인과 증강된 도메인에서의 학습을 효율적으로 조직화합니다. 이 방식을 통해 소스 도메인에서 훈련하고, 증강된 도메인에서 테스트하여 모델이 다양한 도메인에서 잘 일반화할 수 있도록 합니다.
Meta-Train:
소스 도메인 S에서 모델을 학습합니다. 모델의 파라미터는 다음과 같이 업데이트됩니다Meta-Test:
증강된 도메인
𝑆+에서 모델을 테스트합니다.
Meta-Update:
메타 학습을 통해 소스 도메인과 증강된 도메인의 손실을 모두 반영하여 파라미터를 업데이트합니다:
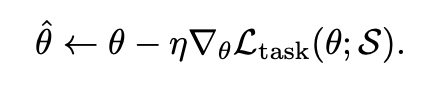
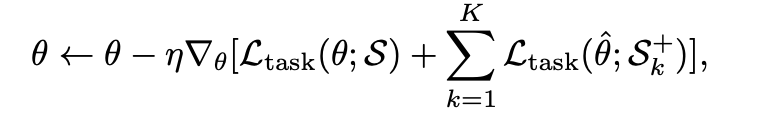
정리하자면 Adversarial Training으로 소스 도메인과 증강된 도메인을 생성하고,
WAE를 사용해 도메인 간 이질성을 증가시키며,
Meta-Learning으로 소스 도메인과 증강된 도메인에서의 학습과 테스트를 효율적으로 조정하여 일반화 성능을 높이는 것입니다.
정리) 이 논문은 기존의 여러 도메인에서 학습하는 방식과 달리, 단일 도메인 학습에서 발생하는 어려움인 Single Domain Generalization 문제를 해결하기 위해 Meta-Learning based Adversarial Domain Augmentation,M-ADA방식을 제안합니다.단일 도메인에서 학습된 모델이 여러 미지의 도메인에서도 잘 일반화되도록 하는 것을 목표로 합니다.이를 위해 Adversarial Domain Augmentation을 사용해 소스 도메인에서 생성된 가상의 도메인들로 모델을 훈련합니다. 또한, Wasserstein Auto-Encoder (WAE)를 사용해 원본 도메인과 가상 도메인 사이의 분포 차이를 최소화 하였습니다.
아래 그림을 보며 흐름을 간단히 보면 소스 도메인에서 전달된 이미지들은 Task Model을 거쳐 임베딩 공간에서 특징 벡터 z로 변환됩니다. 이 과정에서 L_task는 분류와 같은 주어진 과제에 대한 손실을 계산하고, L_const는 모델의 일관성을 유지하는 제약을 추가합니다.WAE는 Distribution Divergence를 최소화하여 잠재 벡터 e가 원본 도메인과 비슷한 분포를 따르도록 학습되며, 동시에 L_relax는 최악의 도메인 간 차이를 줄이기 위해 사용됩니다.
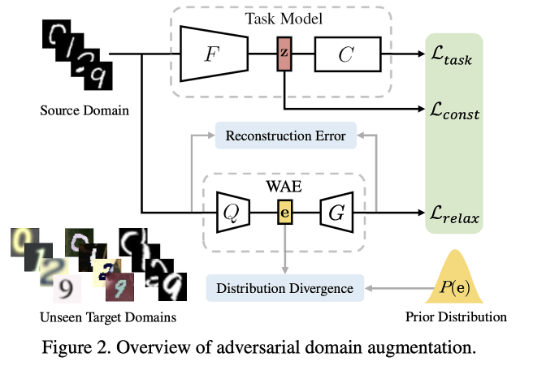
Source Domain (소스 도메인):
모델은 먼저 소스 도메인에서 데이터를 받아들입니다. 이는 일반적으로 모델이 학습에 사용하는 데이터입니다.
소스 도메인에서 이미지들이 Task Model로 전달됩니다. Task Model은 이미지 데이터를 특징 공간으로 변환하는 Feature Extractor(F)와 그 특징을 바탕으로 분류 작업을 수행하는 Classifier(C)로 구성됩니다.
Task Model (태스크 모델):
F는 입력 이미지를 받아 z라는 잠재 공간(latent space)으로 매핑합니다.
C는 이 잠재 공간의 특징을 기반으로 예측 작업을 수행하며, 이때 분류 작업을 위해 사용되는 손실 함수는 Ltask입니다.
동시에, Lconst라는 손실 함수가 적용되는데, 이는 Worst-Case 보장을 위한 제약 조건을 제공하며, 모델이 소스 도메인의 데이터에 대해 일정한 일반화 성능을 유지하도록 합니다.
Wasserstein Auto-Encoder (WAE):
WAE는 데이터 증강을 위한 중요한 구성 요소로, 소스 도메인의 특징을 잠재 공간으로 매핑하는 Encoder(Q)와 잠재 공간을 원래 이미지로 복원하는 Decoder(G)로 구성됩니다.
Q는 소스 도메인의 이미지를 e라는 잠재 변수로 매핑하고, G는 이 잠재 변수를 이용해 원본 이미지를 재구성합니다.
재구성 과정에서 발생하는 손실(차이)은 Reconstruction Error로 측정되며, 이로 인해 WAE가 적절하게 학습되도록 합니다.
Lrelax와 Distribution Divergence:
Lrelax는 소스 도메인과 가상 도메인(augmented domain) 간의 차이를 늘리도록 도와줍니다. 이는 더 큰 도메인 이동(domain transportation)을 가능하게 하여, 모델이 다양한 unseen target 도메인에 대해 더 잘 일반화할 수 있도록 유도합니다.
WAE는 입력 공간에서의 분포 차이를 줄이기 위해 Distribution Divergence를 계산하며, 이는 잠재 변수의 분포(P(e))와의 차이를 줄이기 위해 사용됩니다.
Unseen Target Domains:
위 과정들을 통해 학습된 Task Model과 WAE는 가상 도메인에서 나온 데이터를 통해 학습하며, 최종적으로 unseen target 도메인에서도 높은 일반화 성능을 발휘하도록 합니다.
결론적으로, 이 방법은 단일 도메인에서의 학습 데이터를 바탕으로 적대적 증강을 통해 가상 도메인을 생성하고, 다양한 unseen 도메인에 대해 모델이 잘 대응할 수 있도록 훈련하는 구조를 가집니다.
출처)https://benlee73.tistory.com/43
https://danden.tistory.com/100
