(수정 및 추가필요)
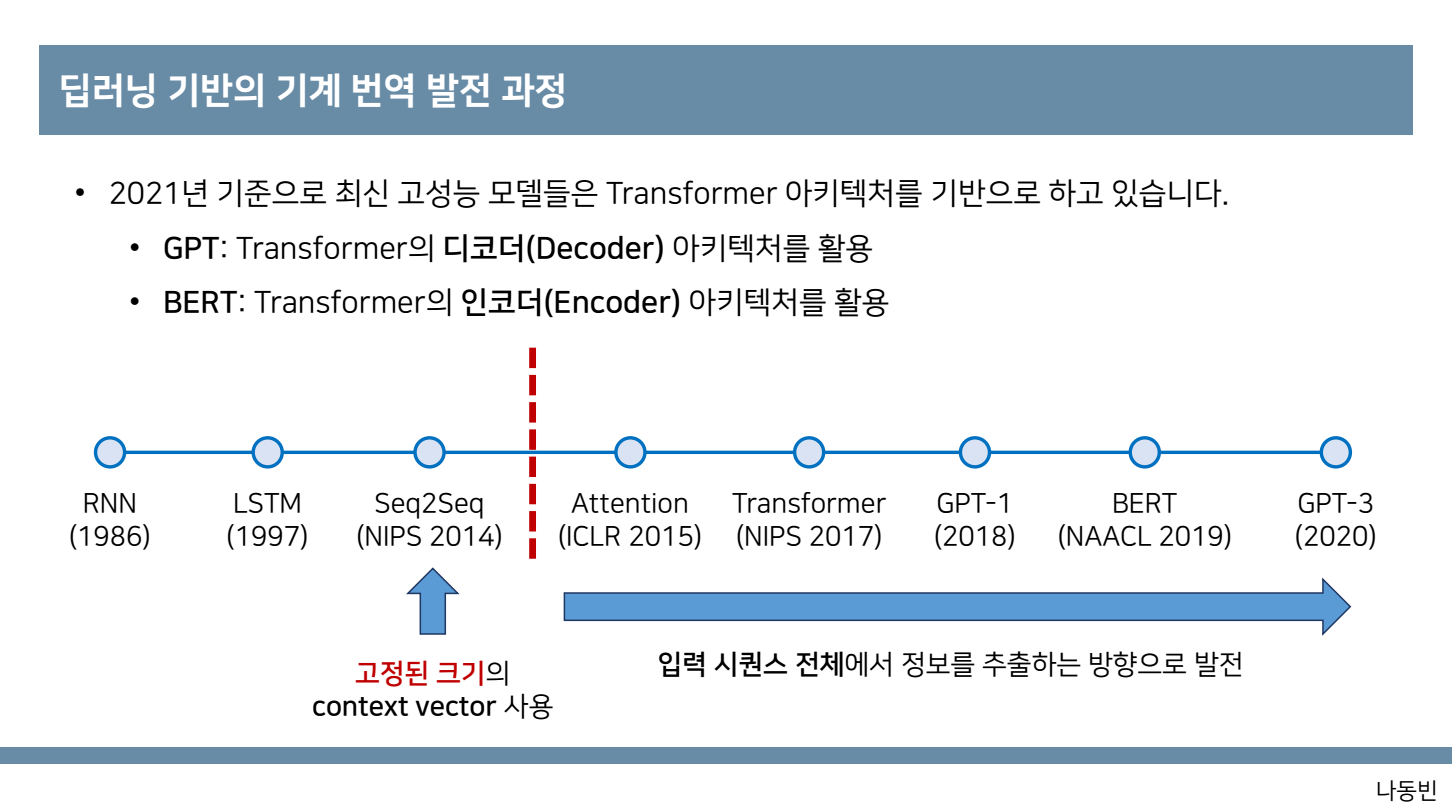
RNN,LSTM Seq2Seq와 같은 경우 까지는 고정된 크기의 context vector를 사용 Attention개념이 나오고 부터는 입력 시퀀스 전체에서 정보를 추출하는 방향으로 발전하였습니다.
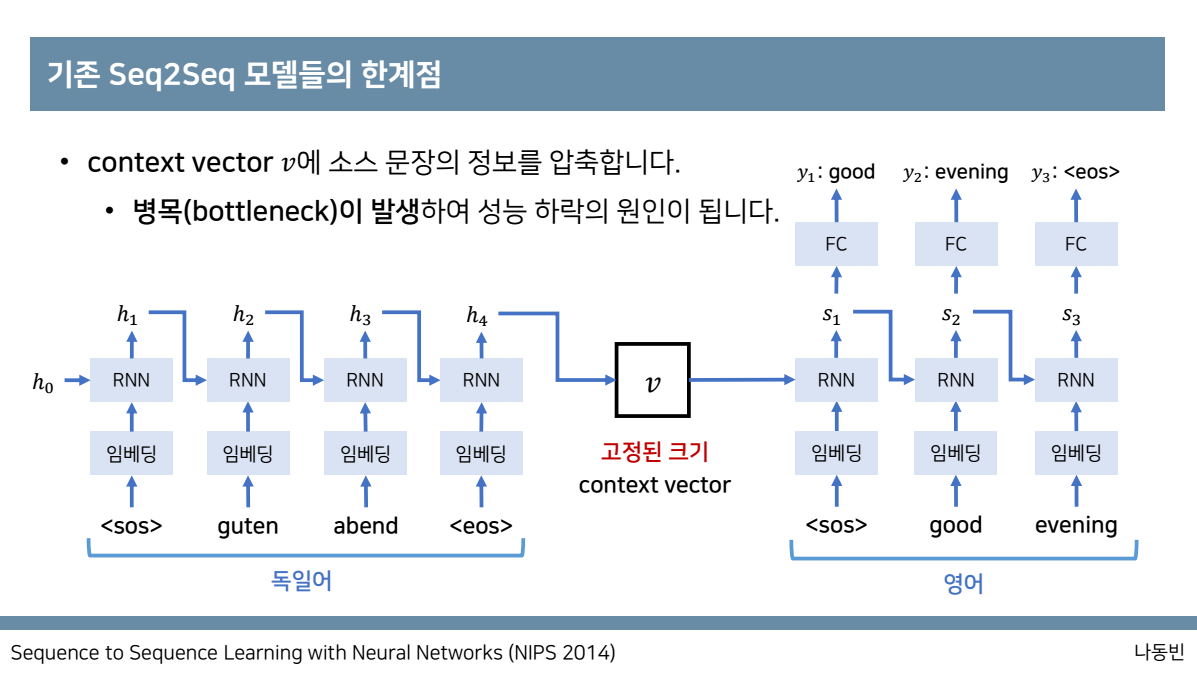
기존 seq2seq와 같은 모델들의 한계점은 고정된 크기의 context vector v에 소스 문장의 정보를 압축하면서 병목현상이 발생하여 성능 하락의 원인이 됩니다.
t시점의 출력되는 값이 이전시점인 t-1의 출력값을 반영하여서 출력하므로 마지막 state의 hidden state값은 앞선 문장의 모든 정보를 함축하고 있는 것을 의미합니다.
위와 같은 Recurrent model들은 모든 데이터를 한꺼번에 처리하는 것이 아니라 sequence position t에 따라 순차적으로 입력에 넣어주어야 합니다.
따라서 이러한 한계는 긴 sequence 길이를 가지는 데이터를 처리해야 할 때, memory와 computation에서 많은 부담이 생기게 된다.
따라서 성능이 저하되는 것을 알 수 있습니다.
즉 정리하자면 하나의 context vector가 소스문장의 모든 정보를 가지고 있어야 하므로 성능이 저하됩니다.
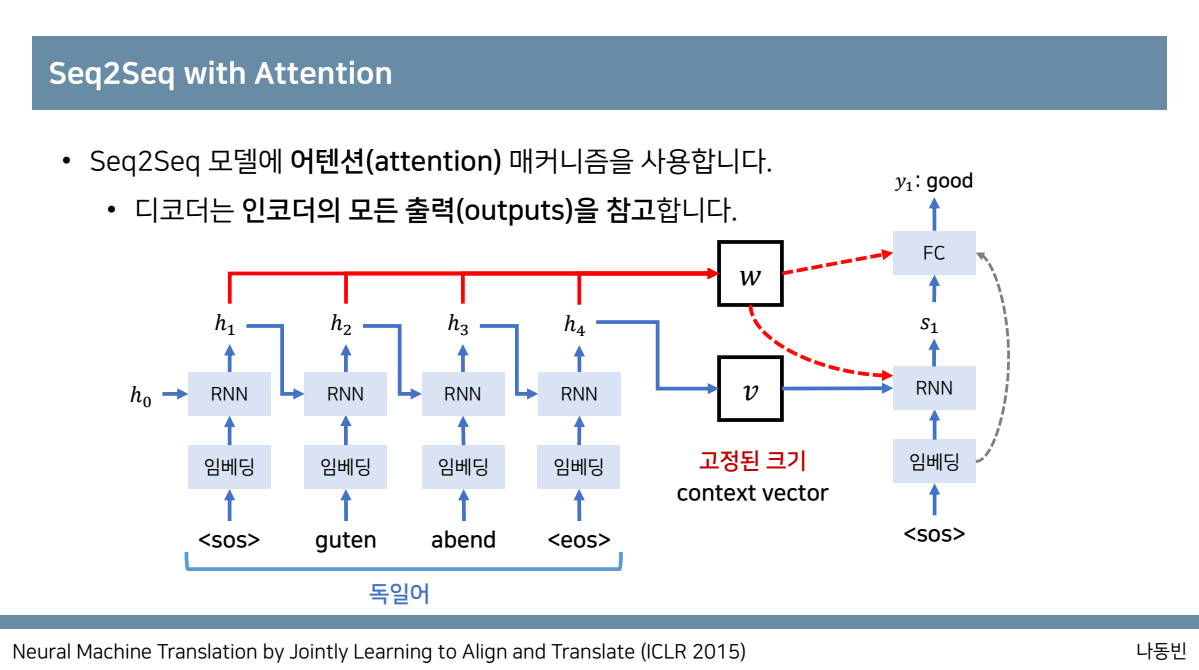
이에 대한 해결방안으로 매번 소스 문장에서의 출력 전부를 입력으로 받으면 어떨까라고 제시하는데
gpu가 많은 메모리와 빠른 병렬 처리를 지원하기때문에 위와 같은 해결방안이 가능한 것을 알 수 있다.

중간 개념으로 seq2seq with attention을 보면 디코더는 인코더의 모든 출력을 참고하는데 출력단어가 갱신 될때마다
인코데에서 있었던 모든 출력 단어들을 참고하는 것을 알 수 있습니다.
즉 디코더는 매번 인코더의 모든 출력 중에서 어떤 정보가 중요한지를 계산하는데 이때 에너지 값과 가중치 값을 고려할 수 있는데
식은 다음 그림과 같고 에너지값은 디코더에서 매번 출력단어를 만들 때마다 모든 j즉,인코더의 모든 출력들을 고려하는 것이고
si-1은 디코더에서 이전 t-1시점에서의 hidden state를 의미한다고 볼 수 있습니다.
에너지 값을 통해 인코더의 어떤 출력값과 가장 많은 연관성을 갖고 있는지를 알 수 있습니다.
그리고 이 에너지값에 softmax를 취해서 상대적인 확률값을 구합니다. 이 값이 가중치가 되고
따라서 연관성에 대해서 비율값으로 처리가 된 것을 알 수 있습니다.

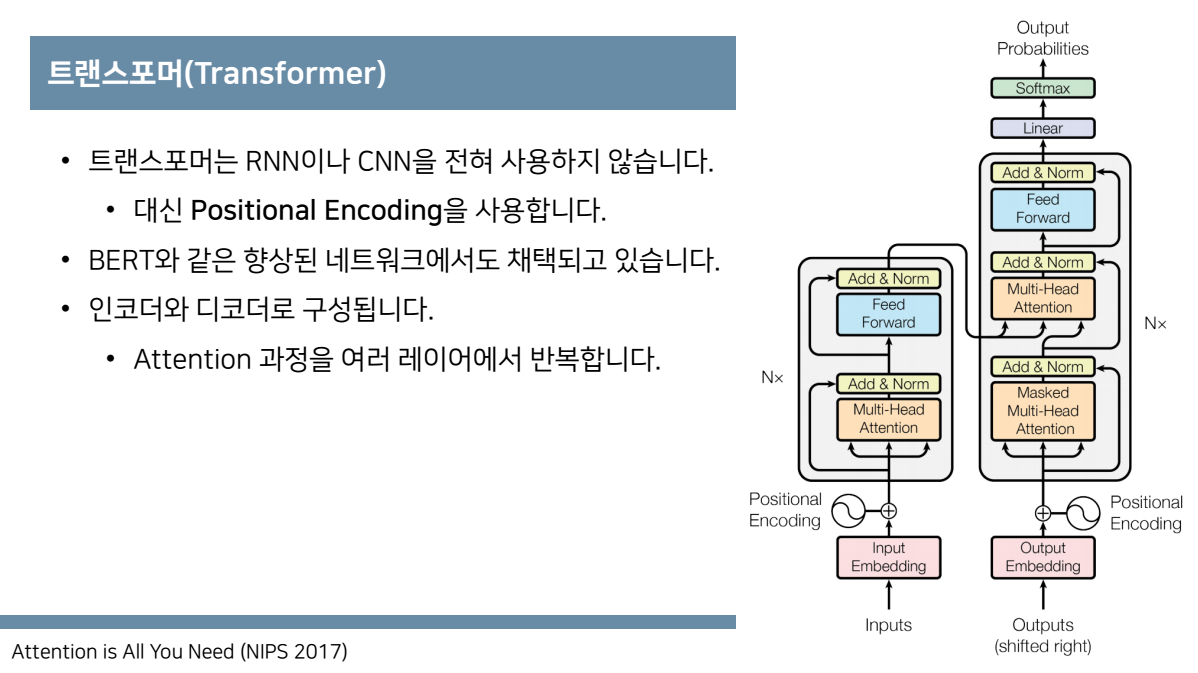
트랜스포머는 rnn이나 cnn을 전혀 필요로 하지 않습니다. attention기법만 사용합니다.
대신 positional encoding을 사용합니다.(단어들의 상대적인 위치, 순서에 대한 정보를 제공)
그리고 이러한 positional encoding은 향후 BERT나 GPT에서 채택되어 사용되며
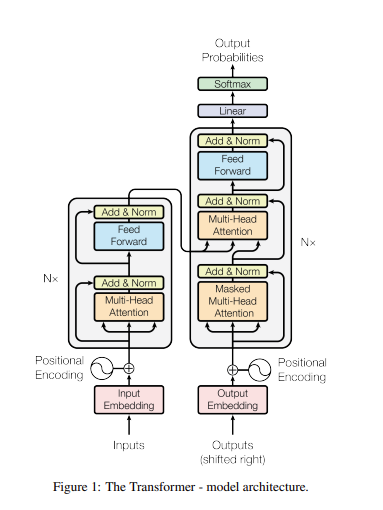
인코더와 디코더로 구성되어 있어서 그림과 같이Nx 즉 attention과정을 N번 여러 레이어에서 반복하는 것을 알 수 있습니다.
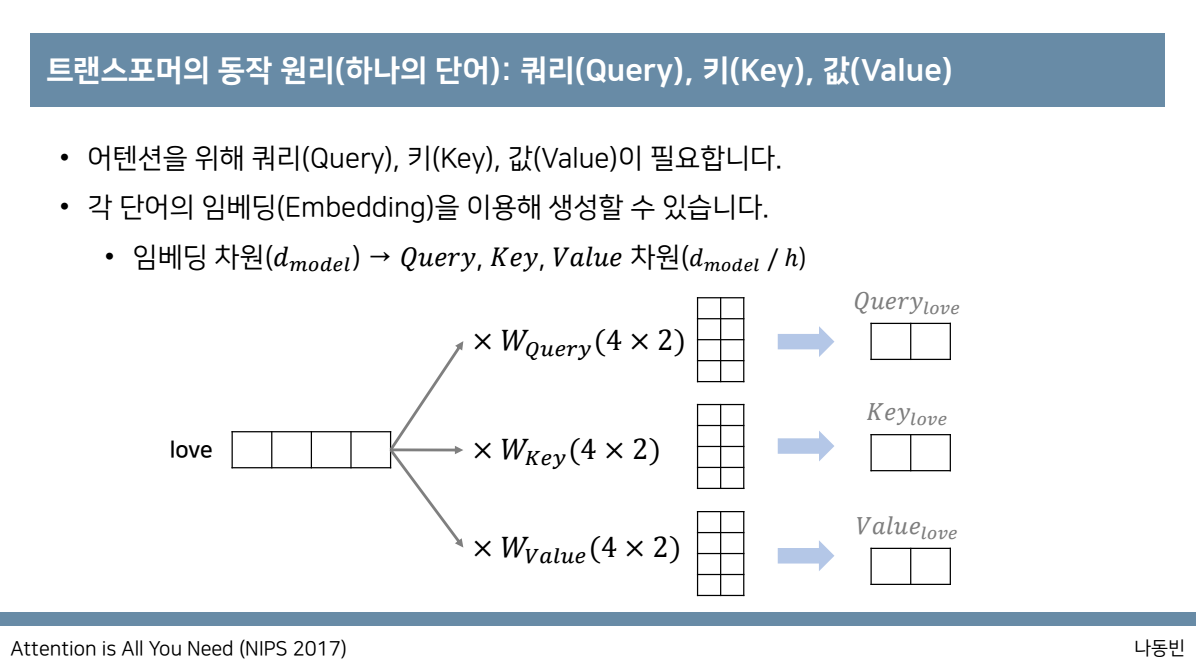
행에 대해서는 각 단어 그리고 열에 대해서는 embedding dimension으로 된 matrix를 두고 사용합니다. 본 논문에서는 이 값을 512로 설정하였습니다.
자동으로 순서정보가 있는 RNN과 다르게 transformer에서는 rnn을 사용하지 않기 때문에 이와 같은 순서 정보 즉 위치정보를 포함하는 과정이 별도로 필요하고
그 과정이 바로 positional encoding입니다. input embedding matrix와 같은 크기를 갖는 positional encoding된 matrix를 element-wise로 더해주는 과정을 필요로 합니다.
이 과정 후에는 Multi-head Attention을 진행합니다. 인코더 부분에서의 attention은 self attention으로 각 단어끼리의 연관성을 구하는 과정을 거칩니다.
그리고 성능 향상을 위해 resnet에서 사용했던 부분인 residual learning을 사용합니다. 즉 인코더에서는 어텐션과 정규화 과정을 반복하는 layer를 갖추고 있고,
또한 유의 할 점으로는 각 layer는 서로 다른 파라미터를 갖습니다.또한 입력되는 값과 출력되는 값의 dimension은 동일 합니다.
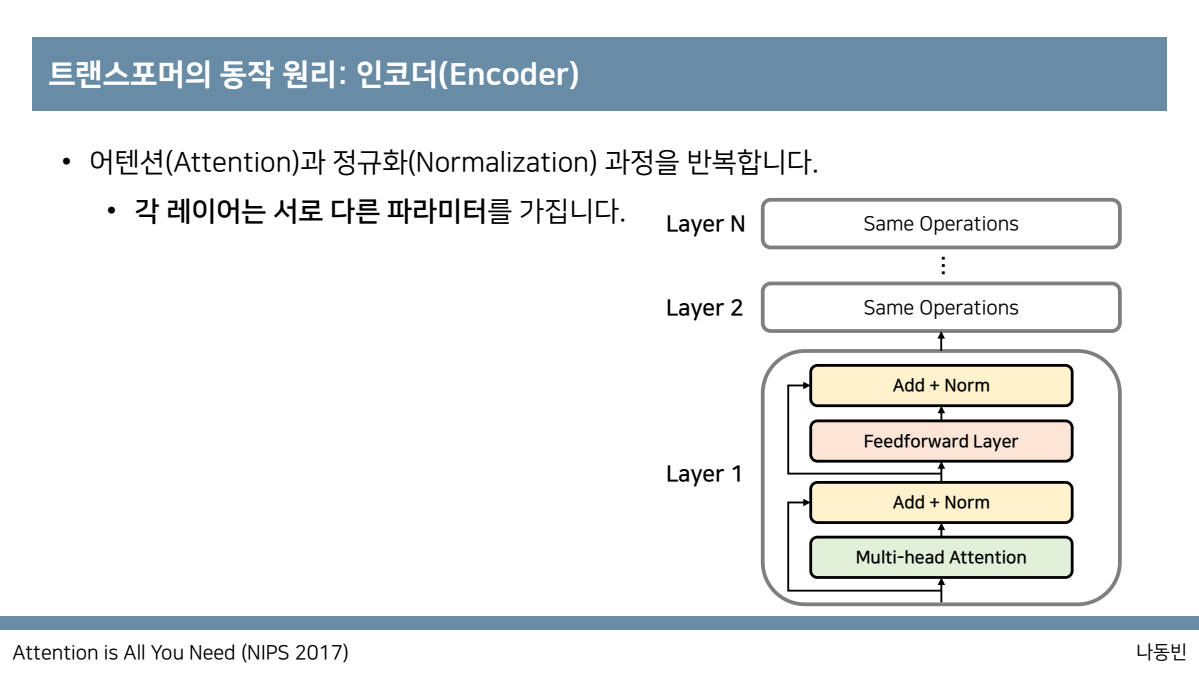
그리고 encoder의 가장 마지막 layer의 출력값은 decoder의 각 layer의 입력으로 들어가게 됩니다.
decoder에서는 2번의 attention을 진행하게 되는데 첫번째 attention과 같은 경우는 encoder에서의 self attention과 동일하게 각각의 단어끼리의 어떠한 가중치를
갖는지를 구하여서 연관성을 구하고 두번째 attention과 같은 경우에는 encoder의 대한 정보를 attention할 수 있게 만드는데 각각의 출력정보가 인코더의 출력정보를
받아와 사용할 수 있게 만듭니다. 이는 각각의 출력단어가 소스문장에서의 어떤 단어와 연관성이 있는지를 구해주는 것입니다.
그리고 이러한 두번째 attention을 encoder-decoder attention이라고 불리는데 예를 들어 설명하면 인코더의 입력정보는 I am a teacher이고,디코더의 입력정보는
나는 선생님이다. 이면 선생님이라는 출력정보의 값은 소스문장에서의 teacher와 가장 큰 연관성을 갖는 과정의 처리를 진행하는 것입니다.
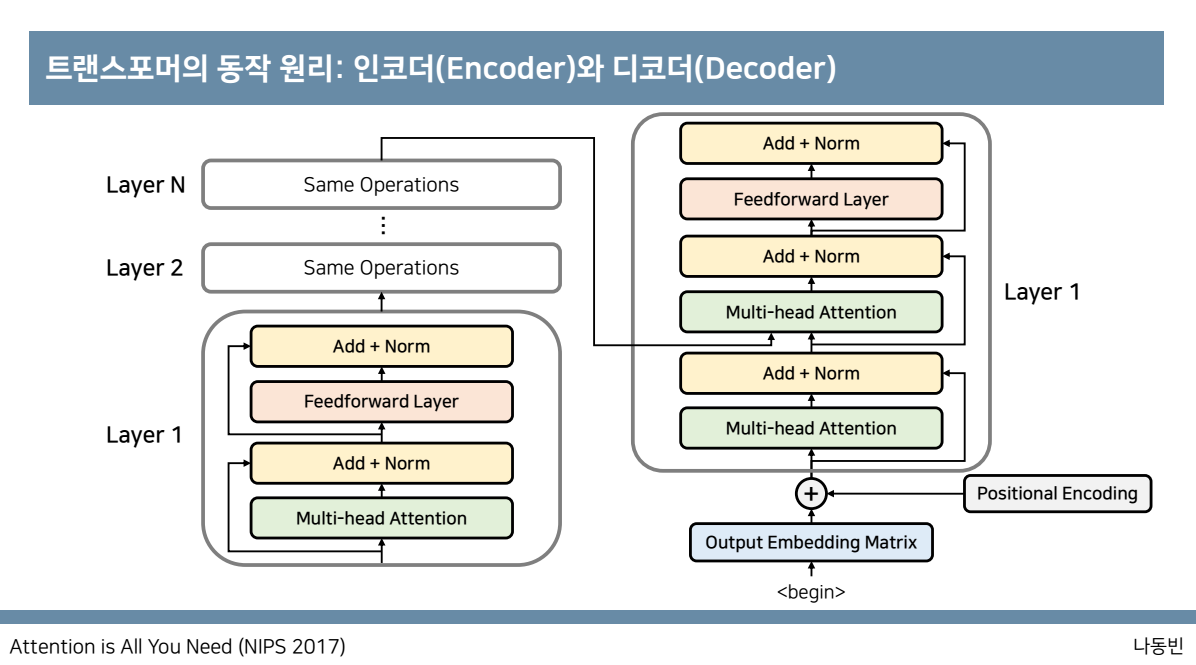
이러한 과정을 거치기 떄문에 트랜스포머에서는 마지막 인코더 레이어의 출력이 모든 디코더 레이어에 입력이 되는 것을 알 수 있으며
n_layer =4 일때의 예시는 다음과 같은 것을 알 수 있습니다.
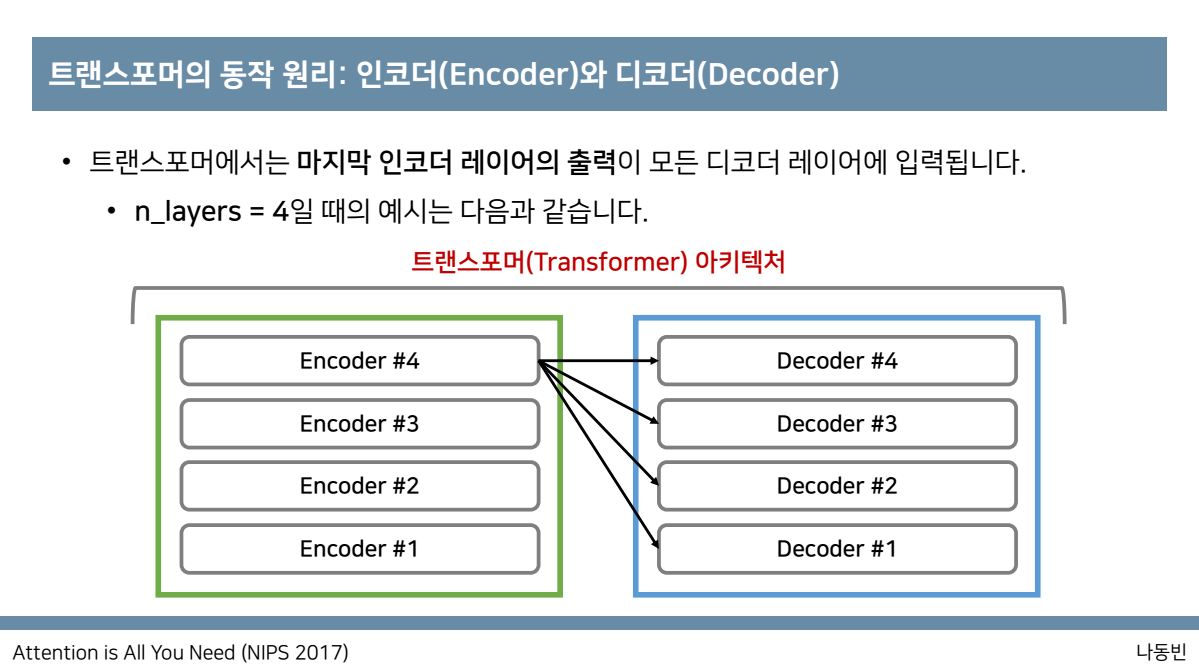
트랜스포머에서는 입력단어 자체가 한번에 입력이 되고 한번에 그에 대한 attention값을 구한다고 볼 수 있습니다.
즉, 다시말해 rnn과 사용했을 때와 다르게 위치에 대한 정보를 한꺼번에 넣어서 한번의 encoder를 거칠때마다 병렬적으로 출력값을 구해낼 수 있기 때문에
계산복잡도가 더 낮게 형성되는 것을 알 수 있습니다.
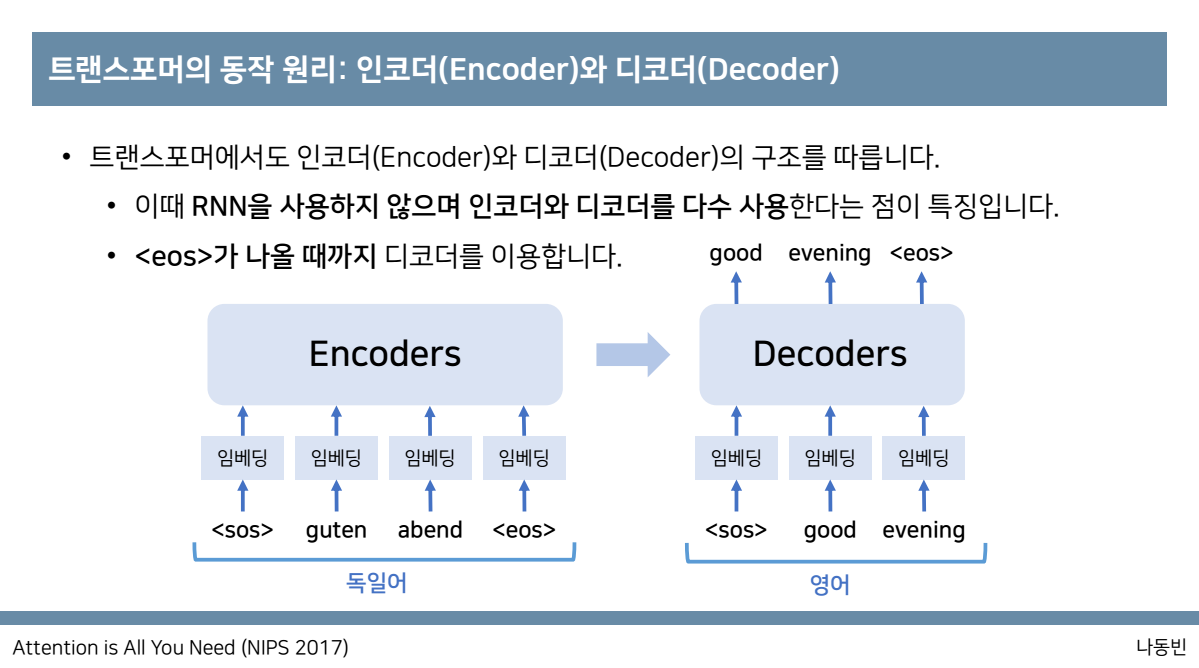
eos가 나올때까지 디코더를 사용합니다.
그렇다면 multi-head attention에 대해 알아보면 다음과 같습니다.
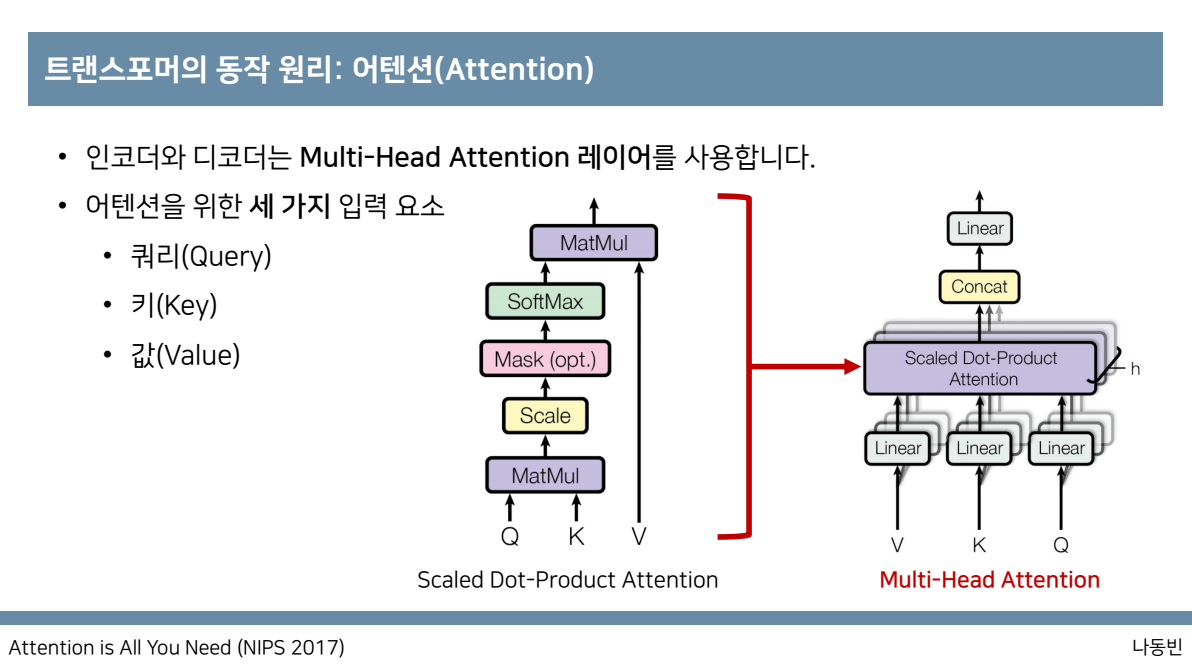
다음그림이 multi-head attention을 보여주는 그림과 같으며 scaled Dot Product attention을 확인 할 수 있는데
이러한 scaled Dot Product attention은 왼쪽그림과 같이 구성된 것을 알 수 있습니다. 이때 입력요소로 Q(query),K(key),V(value)와 같이 있는데
이때 Q는 물어보는 주체가 되고(I),K는 문장 전체의 각각의 단어(I,am,a,teacher) Q와 K사이의 행렬 곱 후 간단한 scaling을 해주고, 필요하다면 mask를 씌워준다음
softmax를 취해서 각각의 key중에서 어떤 단어와 가장 높은 연관성을 갖는지를 그 비율을 구할 수 있습니다.
그 값과 실제 value값을 곱해서 가중치가 적용된 value를 구할 수 있습니다.
또한 scaled Dot Product attention은 h개로 구분되는데 서로다른 value와 key quary로 구분될 수 있게 하는 것인데
이렇게 해주는 이유는 서로다른 h개의 attention concept를 학습하도록 만들어서 더욱더 구분된 다양한 특징들을 학습할 수 있도록 해주는 것입니다.
이때 h는 head의 개수이고 그리고 concat을 활용하여서 입력값과 출력값의 dimension이 같도록 해줍니다.
수식으로 표현하면 다음과 같습니다.
하나의 attention은 Q,K,V를 입력으로 받고 이떄 Query와 Key를 곱해서 각query에 대해서 각각의 Key에 대한 에너지 값을 구할 수 있겠고,
softmax를 통해 확률값으로 표현될 수 있도록 합니다. scale vector로는 rootdk즉 key dimension을 사용합니다. 이러한 scaling을 하는 이유는 softmax의 특성상
0주위에서는 gradient가 높게 형성되는것에 반해 값의 절댓값이 커지게 되면 gradient가 줄어들기 때문에 gradient vanishing문제를 피하고자 scaling을 진행하게 됩니다.
그리고 이값을 value값과 곱해서 실제 value값을 구할 수 있도록 합니다.
h개의 attention score를 구하고, 이를 concat하여서 output matrix와 곱해서 최종 output을 구할 수 있도록 합니다.

본논문에서는 임베딩차원이 512라고 하였고 만약 head가 8개라면 64개의 Q,K,V차원을 가질 수 있습니다.
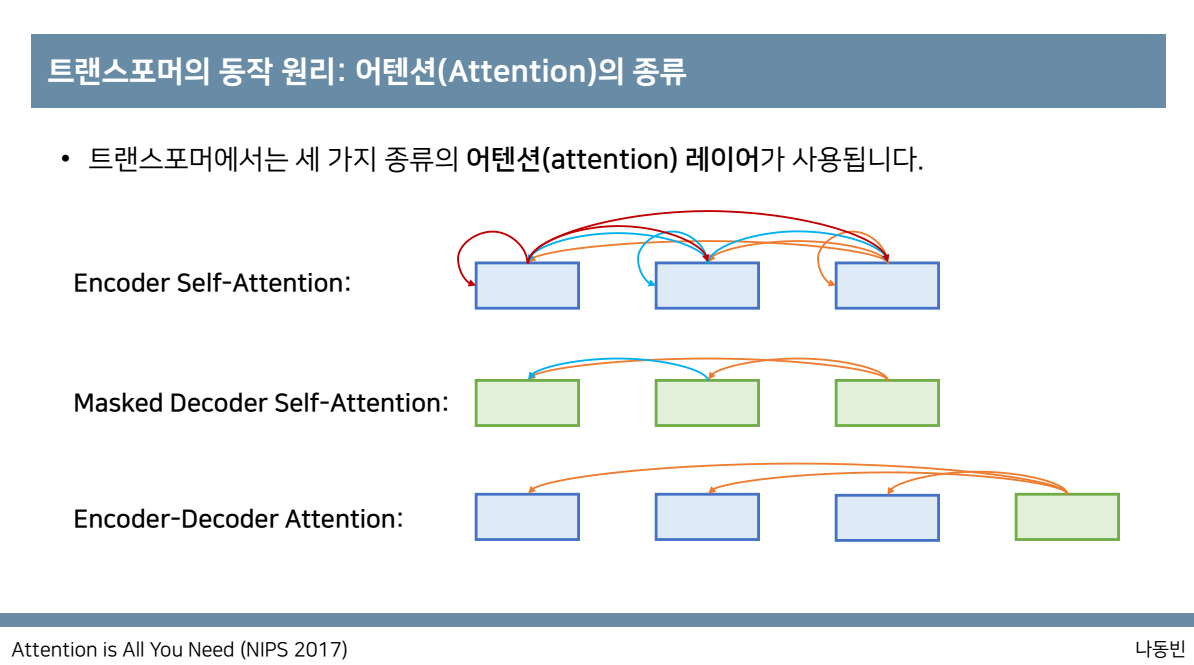
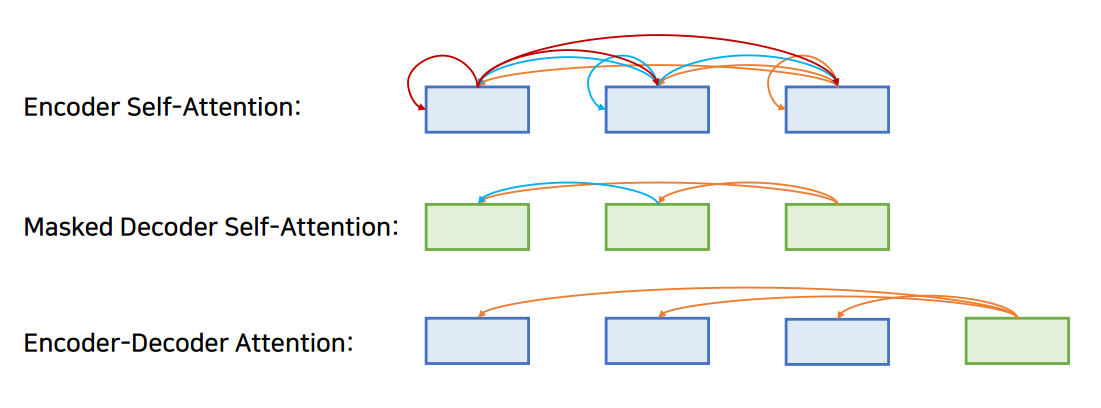
transformer에서 쓰이는 어텐션은 세가지 종류로
encoder self-attention:각 단어가 서로에게 어떠한 영향을 미치는지, masked decoder self attention:디코더 파트의 self attention은 앞쪽의 단어들만 참고할 수 있도록,
(cheating방지)encoder-decoder attention(decoder의 query,encoder의 key들)
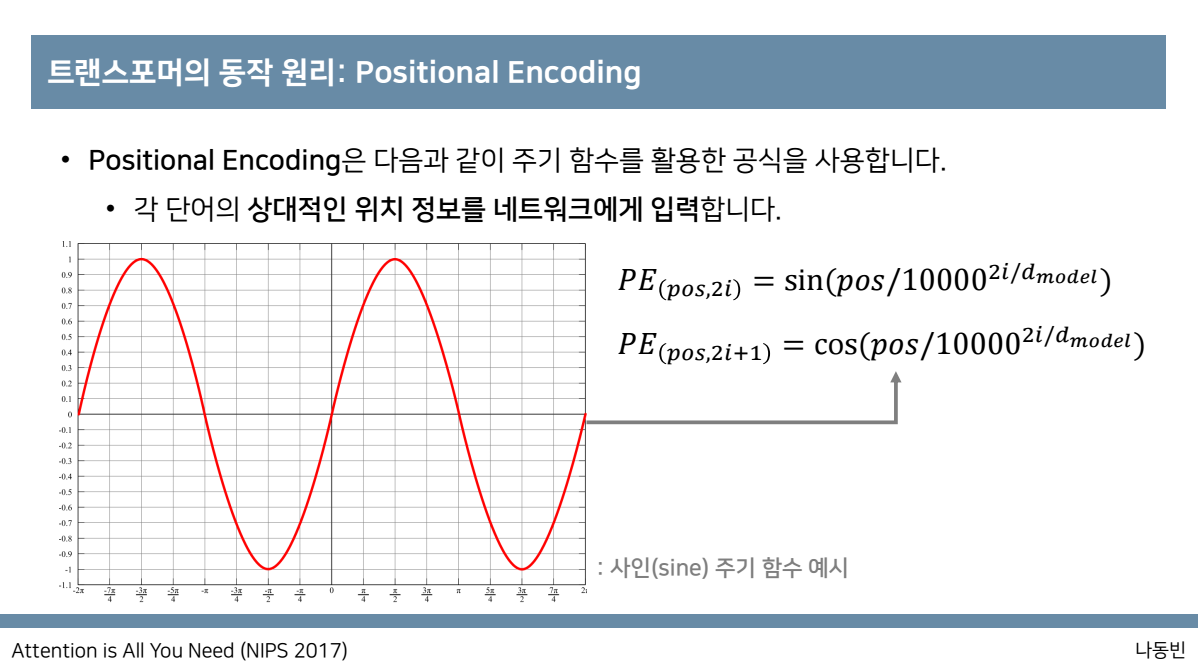
이때 positional encoding은 주기함수 sinusoidal을 이용해서 각 단어의 상대적인 위치 정보를 네트워크에게 입력하는데
이처럼 sinusoidal을 사용하는 이유는 모델이 training 중에 발생하는 것보다 더 긴 시퀀스 길이로 외삽할 수 있기 때문이며,
이때 pos는 단어의 번호 즉 position이고, i는 단어에 대한 각각의 embedding값의 위치 즉 dimension을 의미합니다.
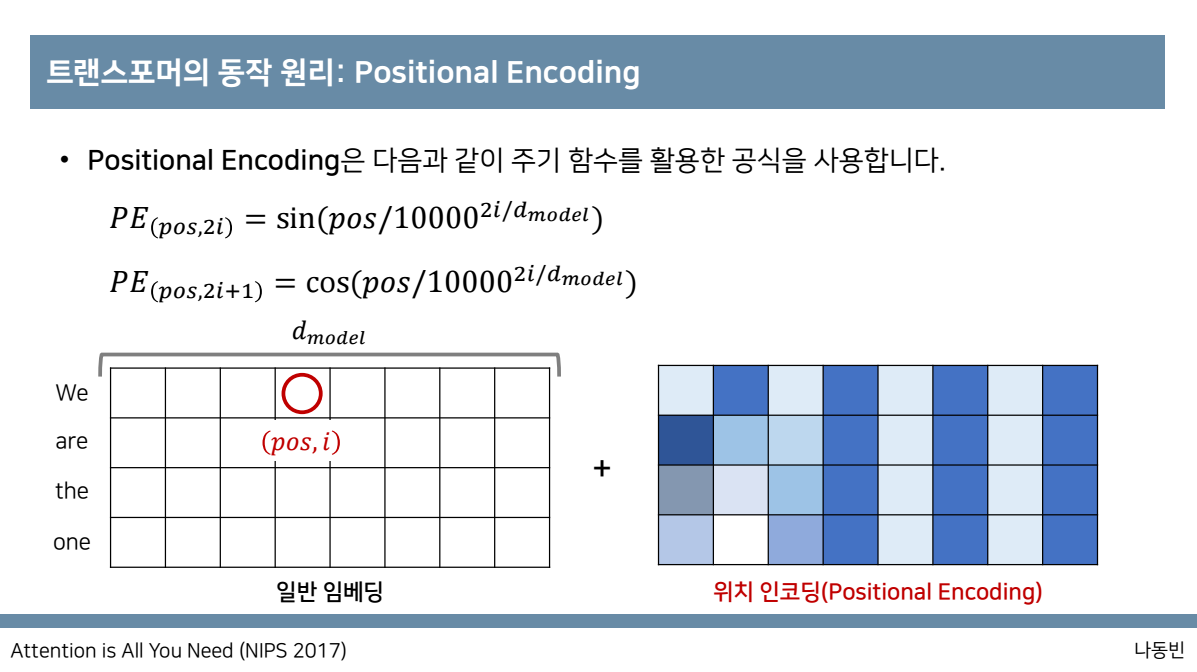
한줄정리>
RNN,LSTM Seq2Seq와 같은 경우 까지는 고정된 크기의 context vector를 사용하는데 이때 긴 sequence 길이를 가지는 데이터를 처리해야 할 때, memory와 computation에서 많은 부담이 생기고 병목현상으로 성능또한 떨어지는 문제를 갖는다.이때 해결방안으로 디코더에서 매번 소스 문장에서의 출력 전부를 입력으로 받는 attention기법을 사용하여서 성능을 올린 transformer를 고안하게 되는데 transformer는 rnn이나 cnn을 사용하지 않고 positional encoding을 사용한 attention기법만을 적용한 모델로 그림과 같은 구조를 갖습니다.
encoder에서는 encoder self-attention으로 다음 그림과 같이 각 단어가 서로에게 어떠한 영향을 미치는지를 반영하고, decoder에서의 첫 attention은 masked decoder self attention으로 앞쪽의 단어들만 참고할 수 있도록(cheating방지),decoder에서의 두번째 attention은 encoder-decoder attention는 decoder의 query와 encoder의 key들사이의 연관성을 구하는 과정을 거칩니다.
이때 연관성을 구하는 식은 다음과 같으며 multi-head attention의 구조는 다음과 같은 그림입니다.
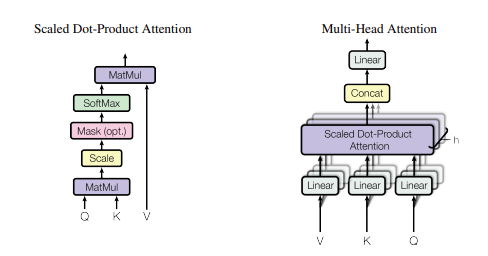
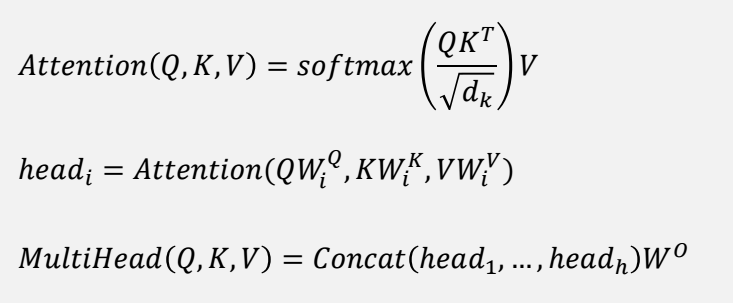
하나의 attention은 Q,K,V를 입력으로 받고 이때 Query와 Key를 곱해서 각query에 대해서 각각의 Key에 대한 에너지 값을 구하고, scaling후 softmax를 통해 확률값으로 표현될 수 있도록 합니다. 이후 vector와 곱하는 과정을 거칩니다.그리고 Output dimension에 맞도록 concat하는 과정을 거칩니다.
추가적으로 positional encoding은 sinusoidal을 사용합니다.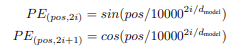
결과적으로 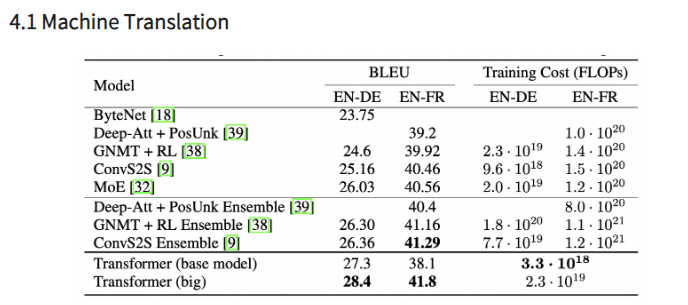
Transformer가 다른 모델들에 비해서 높은 성능을 가지면서 training cost 또한 낮은 것을 볼 수 있다.
reference>
https://www.youtube.com/watch?v=AA621UofTUA
https://aistudy9314.tistory.com/63
