-
개요 (Abstract)
이 논문에서는 Panoptic Segmentation (PS)라는 새로운 과제를 제안하고 연구합니다. PS는 일반적으로 분리된 두 과제인 Semantic Segmentation(각 픽셀에 클래스 레이블 할당)과 Instance Segmentation(각 객체 인스턴스를 탐지하고 분할)을 통합합니다. 제안된 과제는 실제 환경에서 중요한 단계인 일관되고 풍부한 장면 세분화를 생성해야 합니다. 이를 위해, 모든 클래스(물건과 사물)의 성능을 해석 가능하고 통합된 방식으로 포착하는 새로운 Panoptic Quality (PQ) 메트릭을 제안합니다. 제안된 메트릭을 사용하여 기존 데이터셋에서 인간과 기계의 PS 성능을 엄격히 연구하여 흥미로운 통찰을 제공합니다. -
서론 (Introduction)
초기 컴퓨터 비전 연구에서는 Things(사람, 동물, 도구와 같은 셀 수 있는 객체)에 주로 집중했습니다. 반면, Stuff(잔디, 하늘, 도로와 같은 비정형의 유사한 질감이나 물질 영역)의 중요성을 강조하는 연구도 있었습니다. 이러한 구분은 시각 인식 과제와 이를 위한 특수 알고리즘 개발에 반영되어 여전히 지속되고 있습니다.
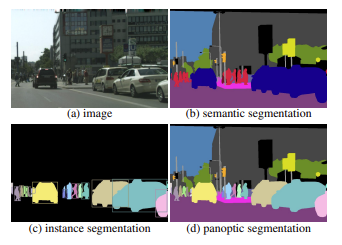
Semantic Segmentation: 비정형이고 셀 수 없는 Stuff를 픽셀 단위로 클래스 레이블을 할당하는 작업.
Instance Segmentation: 셀 수 있는 Things를 탐지하고 각 인스턴스를 분할하는 작업.
PS는 위의 두 가지 과제를 통합하여 이미지 세분화에 대한 보다 통합된 접근을 추구합니다.
- Panoptic Quality (PQ) 메트릭
PQ는 PS 성능을 평가하기 위해 제안된 새로운 메트릭입니다.
이 메트릭은 물건과 사물을 포함한 모든 클래스의 성능을 통합하여 측정합니다. - 연구 결과
세 가지 기존 데이터셋을 사용하여 인간과 기계의 PS 성능을 비교 연구했습니다.
이를 통해 PS 과제에 대한 흥미로운 통찰을 제공하고, 커뮤니티가 이미지 세분화에 대한 보다 통합된 시각을 가지도록 장려합니다.
결론
이 논문은 PS를 통해 이미지 세분화의 새로운 방향을 제시하고, 이를 평가하기 위한 PQ 메트릭을 도입하여 기존의 데이터셋에서 성능을 분석함으로써 새로운 연구의 가능성을 열었습니다.
한줄정리>
컴퓨처 비전에서 Things는 사람, 동물, 도구와 같은 셀 수 있는 객체이고 이와 같은 things를 탐지하고 인스턴스를 분할 하는 작업은 instance segmentation이고, stuff는 잔디, 하늘, 도로와 같은 비정형의 유사한 질감이나 물질 영역인데 이를 픽셀 단위로 클래스 레이블을 할당하는 작업을 Semantic Segmentation이 하게되는데 이를 통합하여 image segmentation에 대해 보다 통합된 접근을 할 수 있도록 하는 것입니다.
이때 PQ는 PS 성능을 평가하기 위해 제안된 새로운 메트릭으로
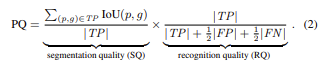
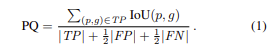
이때 RQ는 F1 score와 같은 개념으로 confusion matrix에서 precision과 recall을 조화평균으로 구한 값으로 점수가 높을 수록 모델의 분류 성능이 뛰어나다는 것을 의미합니다. 또한 SQ는 matched된 segments들의 평균IoU를 의미합니다. 그리고 이와 같은 panoptic segmentation을 저자들은 stuff와 things의 dual한 특징을 다루는 end-to-end모델을 고안해내는 것과 overlapping segments를 가질 수 없다는 특징을 통해서 NMS와 같은 ‘reasoning’한 form이
vision에서의 혁신을 가져오기를 바란다고 언급하였습니다.
출처)https://deep-learning-study.tistory.com/861
https://velog.io/@babydeveloper/InstancePanoptic-segmentation
