[논문리뷰]Generative Adversarial Nets
paper review
(서로 적대적인 관계를 가지고 있는 2개의 network를 동시에 학습하는 방향으로 하나의 생성모델을 학습할 수 있습니다. 이때 G는 원본데이터의 분포를 학습하게 되고,
D는 한 장의 이미지가 학습데이터인지 혹은 G로부터 만들어진 이미지인지 구별할 수 있도록 학습이 이루어집니다. 다시말해 G와 D는 일종의 min maxgame을 하는 것. 하나의 목적식이 있을 때 하나는 그식을 최대화 하고 다른 한식은 그 식을 최소화하도록 학습을 진행합니다.
다른 말로 하면 G는 속이려고 하고 D는 속지 않으려고 하는 방식으로 학습을 진행합니다.)
Deep generative models은 최대 가능성 추정 및 관련 전략에서 발생하는 많은 다루기 어려운 확률 계산을 근사화하는 어려움과 generative context에서 piecewise linear units의 이점을 활용하는 어려움으로 인해 어려움이 있었는데,( Deep generative models have had less
of an impact, due to the difficulty of approximating many intractable probabilistic computations that
arise in maximum likelihood estimation and related strategies, and due to difficulty of leveraging
the benefits of piecewise linear units in the generative context.) 이를 극복하는 새로운 생성 모델 추정 절차인 “adversarial nets” framework를 제안한 것으로 generative model은 위조지폐를 만드려고 노력하고 이를 들키지 않고 사용하는 위조범과 비슷하다고 생각되어질 수 있으며
discriminative model은 위조 지폐를 발견하려고 노력하는 경찰과 비슷하다고 논문에서는 설명하고 있었습니다.
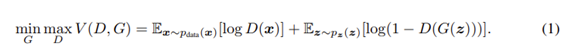
그리고 위의 식이 전체의 목적함수로 G는 이 식을 최소화 하고 D는 최대화 하도록 합니다.
2번의 학습을 거치는데 먼저 D에 대한 max를 수행하는 식을 보면 앞term의 D는 실제이미지인 x가 들어왔을 때 진짜로 판단할 수 있게 즉, Dofx가 1이 나올 수 있도록 하고, 뒤의 term에서 G가 생성해낸 이미지인 Gofz에 대해서는 가짜이미지로 판단 할 수 있게 즉, DofGofz에 대해서는 0이 나올 수 있게 합니다. 그리고 G에 대한 min를 수행하는 식을 보면 뒤의 term만 고려하면 되는데 G가 생성해낸 가짜이미지에 대해서 discriminator가 진짜라고 판단할 수 있게 합니다. 따라서 두 번째 term의 DofGofz가 1이 될 수 있도록 합니다.
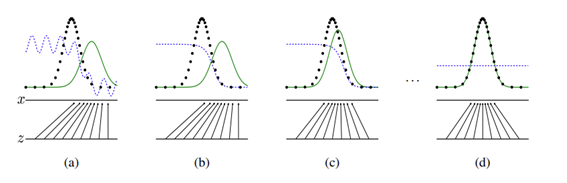
그리고 그림으로 설명했을때는 (a)그림에서 보이는 듯이 처음에는 생성자의 분포가 원본학습데이터의 분포를 잘 학습하지 못하기 때문에 구분된 그래프의 형태로 보여지고 discriminator는 잘 구분해내는 것을 볼 수 있고 (a)에서 (d)까지 이루어짐에 따라 학습이 잘 이루어진 (d)를 보면 생성자의 분포가 원본데이터의 분포를 잘 따라가는 것을 볼 수 있으며 discriminator와 같은 경우는 가짜이미지와 진짜이미지를 구분할 수 없기 때문에 아래 식에 의해 pg= pdata이므로 1/2로 수렴하는 것을 확인할 수 있었습니다.
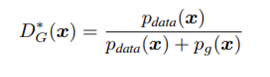
그리고 VAE에 비해 sharp하며 유사하지 않은 별개의 이미지들을 생성해낸다는 특징이 있습니다. 그리고 VAE는 smooth한것과 다르게 mode collapse가 일어나고 Unstable한 convergence가 발생한다고 볼 수 있습니다.
