[논문리뷰] Learning to Prompt for Continual Learning
Complementary Learning Systems(CLS) 이론에 따른 많은 방법들은 리허설 버퍼에 의존 적임(—> 버퍼 크기가 작을 수록 성능이 크게 저하되며, 데이터 프라이버시 문제로 리허설 버퍼가 허용되지 않는 경우들도 있음
- reherarsal buffer: 과거 task 데이터를 저장하고, 현재 task 학습 때 이를 같이 학습하여 catastrophic forgetting을 최소화 함),test time에 task id를 아는 것은 실제 사용에 어려움이 있음.(test time에 task id를 가정하여 forgetting 문제를 우회함)
이런 limitation들을 해결하기 위해 해당 논문에서 Learning to Prompt for Continual Learning(L2P) 제안
prompt pool을 학습하여 모델에 조건부로 지시하기에 리허설 버퍼가 필요 없음
L2P는 인스턴스 별로 pool을 자동으로 선택하고 업데이트 하기 때문에 task id 필요 없음
그리고 이러한 L2P는
공유, 비공유 지식을 명시적으로 분리하여 최적화 중에 작업별 지식 간의 간섭을 크게 줄여 리허설 버퍼 없이 catastrophic forgetting을 최소화 한다.
L2P의 procedure은 다음과 같다.
먼저, L2P는 제안된 인스턴스별 쿼리 메커니즘을 기반으로 key-value 쌍으로 구성된 프롬프트 풀에서 프롬프트 하위 집합을 선택합니다. 그런 다음 L2P는 선택된 프롬프트를 입력 토큰에 추가합니다. 마지막으로 L2P는 확장된 토큰을 모델에 공급하고 방정식 5에 정의된 loss을 통해 프롬프트 풀을 최적화합니다. (First, L2P selects a subset of prompts from a
key-value paired prompt pool based on our proposed instance-wise query mechanism. Then, L2P prepends the selected prompts to the
input tokens. Finally, L2P feeds the extended tokens to the model, and optimize the prompt pool through the loss defined in equation 5.)
위식에서의 첫 번째 term은 softmax cross-entropy이고 두 번째 term은 선택된 키를 해당 쿼리 피처에 더 가깝게 끌어 당기기 위한 surro-gate loss.( The first term is
the softmax cross-entropy loss, the second term is a surrogate loss to pull selected keys closer to corresponding query
features.)
prompt pool의 도입 동기는 3가지로 다음과 같습니다.
1. test time에서 task id 알 수 없으면, task id를 통한 training은 불가능함
2. task id를 알고 있다고 해도 유사한 작업 간에 가능한 지식 공유를 방지함
3. 단일 공유 자극을 학습하는 원래 방법은 모든 작업에 대한 지식공유를 가능하게 하지만, 여전히 forgetting 이슈를 야기 함
이상적으로, 작업이 유사할 때는 지식을 공유하고, 다른 경우에는 지식을 분리하는 모델을 학습해야 함
모델에 대한 입력으로 유연하게 그룹화할 수 있는 인코딩된 지식을 저장하기 위한 prompt pool 사용
정리)
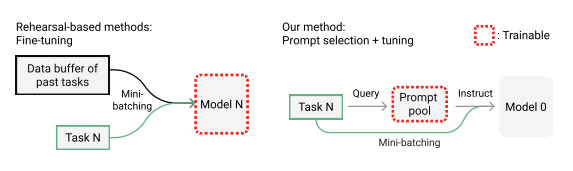
Continual learning에서 극복하고자 하는 문제는 catastropic forgetting문제인데 이를 해결하기 위해 Typical method는 주로 rehearsal buffer 혹은 known task identity에 의존하였다 그러나 rehearsal buffer는 버퍼 크기가 작을 수록 성능이 크게 저하된다는 점과 프라이버시 문제로 리허설 버퍼가 허용되지 않는 경우가 있다는 단점이 존재하고, known task identity는 실제 사용에 어려움이 있다는 단점이 있어 이를 보완하여 나온 개념이 L2P입니다.prompt pool을 학습하여 모델에 조건부로 지시하기에 리허설 버퍼가 필요 없고
L2P는 인스턴스 별로 pool을 자동으로 선택하고 업데이트 하기 때문에 task id 필요 없다는 장점이 있습니다.
그리고 이러한 L2P는
공유, 비공유 지식을 명시적으로 분리하여 최적화 중에 작업별 지식 간의 간섭을 크게 줄여 리허설 버퍼 없이 catastrophic forgetting을 최소화 합니다.
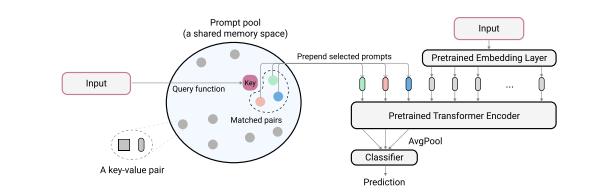
L2P의 procedure은 다음과 같습니다.먼저, L2P는 제안된 인스턴스별 쿼리 메커니즘을 기반으로 key-value 쌍으로 구성된 프롬프트 풀에서 프롬프트 하위 집합을 선택합니다. 그런 다음 L2P는 선택된 프롬프트를 입력 토큰에 추가합니다. 마지막으로 L2P는 확장된 토큰을 모델에 공급하고 방정식 5에 정의된 loss을 통해 프롬프트 풀을 최적화합니다.
이때 언급한 방정식은 다음과 같으며 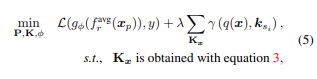 첫 번째 term은 softmax cross-entropy이고 두 번째 term은 선택된 키를 해당 쿼리 피처에 더 가깝게 끌어 당기기 위한 surro-gate loss입니다.
첫 번째 term은 softmax cross-entropy이고 두 번째 term은 선택된 키를 해당 쿼리 피처에 더 가깝게 끌어 당기기 위한 surro-gate loss입니다.


출처)https://velog.io/@smlim/Learning-to-Prompt-for-Continual-Learning-umvgxcx6
