[논문리뷰](VAE) : Auto-Encoding Variational Bayes
variational 잡기술, encoding에다가 noise를 섞어서 decoder에 넣어주는 것이다!
input과 output의 차이값을 최소화 하는 것 -> reconstruction error를 최소화 하는 것.
기본적으로는 cross entropy를 loss function으로 가짐.
(output으로 나오는 값이 베르누이를 따른다고 가정하고 있기 때문)
두 번째 loss function으로는 encoder를 통과한 값이 항상 normal distribution을 따라야하기 때문에 그렇게 만들기 위해서 KL divergence식을 쓰는데 encoder를 통과하는 확률이 정규분포를 따를 수 있도록 최적화를 해야함
->KL divergence가 최소가 되도록
그리고 이것을 식으로 나타낸 term이 regularization term.
optimization으로는 reparameterization term
BP가 가능하도록 평균이 0이고 표준편차가 1인 표준정규분포에서 sampling한 다음에 샘플링한 그것을 표준편차에 곱해주고 뮤에다가 더해주면 그게 새로운 샘플링 값이 됩니다.
(정리)
먼저 VAE의 구조를 보면 학습데이터를 압축하는 encoder와 압축된 정보를 담고 있는 latent variable, 그리고 이 값을 바탕으로 학습데이터와 비슷한 데이터를 만드는 역할을 수행하는 decoder로 나뉩니다. 그리고 학습과정은 다음과 같은데, 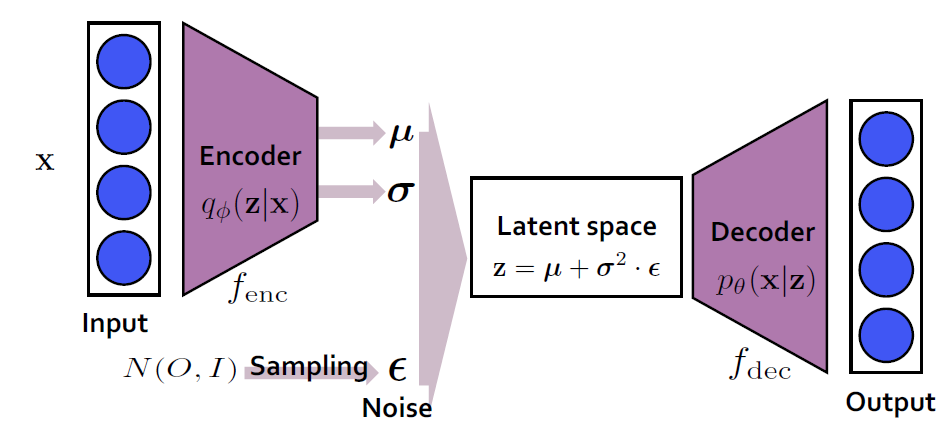
x가 가우시안 인코더로 들어가면, 뮤와 시그마를 output으로 뱉습니다. 여기서 z를 샘플링을 하는데 샘플링을 하는 것 자체는 미분이 불가하여 back propagation이 불가능합니다. 그렇기에 Reparameterization trick을 사용하여 표준정규분포에서 샘플링을 한 후에, 샘플링 한 값에 시그마를 곱해주고 뮤를 더해서 z를 만들어줍니다. 이렇게 만들어진 z가 (베르누이 or 가우시안) 디코더를 통과하게 됩니다.
베르누이를 따르는 디코더라면, p값이 나오게 되고(베르누이에서는 파라미터 값이 확률 p),
그렇게 되면 두 가지로 나뉘는 loss ft에서 Reconstruction error는 Cross entropy식이 되며, Regularization 식은 가우시안 인코더를 따르는 q가 normal distribution을 따르게 만드는 KL divergence를 쓰기 때문에 아래와 같은 식이 완성됩니다.
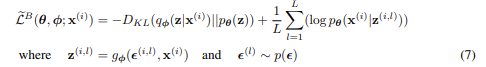
출처)
https://www.youtube.com/watch?v=GbCAwVVKaHY
https://velog.io/@lee9843/VAE-Auto-Encoding-Variational-Bayes-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
https://process-mining.tistory.com/161
https://www.youtube.com/watch?v=oas0GfmkQKs
https://di-bigdata-study.tistory.com/4
https://aigong.tistory.com/367
