
task-id를 알고있거나, 리허설 버퍼를 통해 과거 테스크 데이터 샘플을 사용하는 일반적인 방법이 아닌 NLP의 prompt-based learning + prompt tuning를 착안하여 최초로 continual learning에 적용한 case,
여느 SOTA들 보다 높은 성능치를 보이며, catastrophic forgetting을 최소화하는 것으로 보여짐.
Learning to Prompt for Continual Learning
Abstract
- non-staitonary data distributions에서 catastrophic forgetting은 핵심 challenge임
- 일반적으로 rehearsal buffer 또는 task id를 사용하여 지식을 검색하고 catastrophic forgetting을 해결
- 논문에서는 learns to dynamically prompt (L2P)를 제시
- 다른 task들에 대해 순차적으로 학습
- 메모리 공간에서 유지되는 학습 가능한 작은 parameter
- rehersal buffer 없이도 비슷한 결과를 달성
1. Introduction
-
독립적이고 동일하게 분산된 (i.i.d) 데이터에 대해 continual learning은 다른 task에 비정형 데이터 분포에 대해 순차적으로 단일 모델을 학습함
- 이러면 현재의 데이터에 대해 overfit되고 catastrohphic forgetting 문제 발생
—> 이전에 훈련된 데이터의 성능이 저하됨

리허설 버퍼로 기반으로 모델 전체 또는 일부 가중치를 순차적으로 조정하는 기존 방법과 비교하여, prompt pool을 학습하여 모델에 조건부로 지시하기에 리허설 버퍼가 필요 없음
L2P는 인스턴스 별로 pool을 자동으로 선택하고 업데이트 하기 때문에 task id 필요 없음 -
continual learning의 주요 작업은 모델 가중치의 전체 또는 일부에 대해, 데이터 분포가 변함에 따라 과거 지식을 보존하는 것
- 많은 method들이 좋은 성능들을 달성했지만 여전히 해결해야 할 주요 제한 사항이 있음
- Complementary Learning Systems(CLS) 이론에 따른 많은 방법들은 리허설 버퍼에 의존 적임
—> 버퍼 크기가 작을 수록 성능이 크게 저하되며, 데이터 프라이버시 문제로 리허설 버퍼가 허용되지 않는 경우들도 있음
- reherarsal buffer: 과거 task 데이터를 저장하고, 현재 task 학습 때 이를 같이 학습하여 catastrophic forgetting을 최소화 함 - test time에 task id를 아는 것은 실제 사용에 어려움이 있음
- test time에 task id를 가정하여 forgetting 문제를 우회함
- Complementary Learning Systems(CLS) 이론에 따른 많은 방법들은 리허설 버퍼에 의존 적임
- 이런 limitation들은 다음 두 가지를 제기 함
- Whether the form of episodic memory can go beyond buffering past data to more intelligent and succinct episodic memory system?
- NLP의 prompt-based learning을 통해 모델 가중치를 직접 조정하는 것부터 작업 재정의를 조건부로 수행하도록 모델에 지시하는 prompt 설계에 이르기 까지, downstream 작업을 학습 함
- prompt는 일반적인 pretrained frozen model의 fine-tuning보다 task별 지식을 더 효과적이게 encdoing함
- NLP의 prompt-based learning을 통해 모델 가중치를 직접 조정하는 것부터 작업 재정의를 조건부로 수행하도록 모델에 지시하는 prompt 설계에 이르기 까지, downstream 작업을 학습 함
- How to automatically select relevant knowledge component for arbitrary sample without knowing its task identity?
- 해당 문제를 해결하기에는 불명확함
- Whether the form of episodic memory can go beyond buffering past data to more intelligent and succinct episodic memory system?
- 이를 위해 해당 논문에서 Learning to Prompt for Continual Learning(L2P) 제안
- pre-trained model은 건들지 않는 대신에, prompt를 학습하여 model이 동적으로 해당 task를 해결하도록 함
- prompts는 key-value 공유 메모리 공간에 구조화 되며, 인스턴스 input feature 기준으로 동적으로 task와 관계있는 subset을 lookup
- supevised loss와 함께 최적화 되어 공유 prompts는 지식 전달을 위해 공유 지식을 encoding하고, 비공유 prompts는 task-specific 지식을 encode하여 모델의 가소성을 보존함
- 공유, 비공유 지식을 명시적으로 분리하여 최적화 중에 작업별 지식 간의 간섭을 크게 줄여 리허설 버퍼 없이 catastrophic forgetting을 최소화 함
- instance-wise query 메카니즘을 통해 task id 또는 boundaries를 알아야할 필요성을 제거 함
- 많은 method들이 좋은 성능들을 달성했지만 여전히 해결해야 할 주요 제한 사항이 있음
-
L2P 요약
- 매개변수화된 “명령”으로 pre-trained model을 순차적으로 학습하는 prompt based continual learning 제안
- class- and domain- incremental 그리고 task에 영향을 받지 않는 setting으로 여러 benchmark에 대한 실험, 이전의 SOTA보다 높은 성능 보임, 리허설 버퍼 사용안해도 경쟁력 있는 결과
- continual learning에 prompting 방식을 첫 번째로 도입
2. Related Work
- Continual learning은 3가지 주요 범주가 있음
- Regularization-based methods
- 이전 taks에 대해 중요한 parameters는 learning rate에 제한을 주어, 모델의 가소성을 제한함으로써, forgetting 문제는 어느정도 해결하지만, 데이터가 복잡해질 경우 성능달성에 어려움 있음
- Rehearsal-based methods
- 이전 task의 샘플을 보관하고 현재 task 학습 시 이 샘플로 구성된 데이터 버퍼를 통해 같이 학습하여 forgetting 문제를 해결하지만, 버퍼 크기가 작을 수록 성능이 떨어지고, 데이터 프라이버시가 있는 경우 적용할 수 없음
- 최근 추가 knowledge distillation 패널티를 통합하거나, self-supervised learning기술을 활용하여 개선
- Architecture-based methods
- 각 task에 대한 component 분리를 목표로 함
- 특정 task compoent를 통해, 네트워크를 확장하거나, 작업별 하위 네트워크에 집중 하기 위해 test time에서 task id가 필요함
- 이 문제를 위회하기 위해 task id를 유추하거나 리허설 버퍼를 추가하는데, 이는 많은 매개변수를 필요로 함
- 특정 task compoent를 통해, 네트워크를 확장하거나, 작업별 하위 네트워크에 집중 하기 위해 test time에서 task id가 필요함
- 각 task에 대한 component 분리를 목표로 함
- Regularization-based methods
- 최근 주요 연구들 중 CTN, DualNet 또한 test time에서의 task id를 필요로 하고, 리허설 버퍼를 필요로 함
- prompt는 Adpater, LoRa보다 적은 parameter를 필요로 하고 prompting의 주요 idea는 전이 학습을 위해 설계되었음
3. Prerequistites
-
Continual learning protocols
순차적인 taks의 비정적 데이터로 모델을 학습하는 것
continual learning에 대한 3가지 시나리오가 정의되어 있음- task incremental learning
—> task가 바뀌는 상황에서의 continual learning으로 이진 클래스를 예시로 했을 때 각 task에서의 이진 class가 바뀌는 상황임(e.g. 토끼/고양이, 강아지/여우) - domain incremental learning
—> domain이 바뀌는 상황에서의 continual learning으로 이진 클래스를 예시로 했을 경우 이진 class는 같은데 도메인이 다른 경우(e.g. 만화속에서의 토끼/고양이, 실제 토끼/고양이) - class incremental learning
—> class가 바뀌는 상황에서의 continual learning(e.g. 토끼/고양이 —> 토끼/고양이/강아지/여우)
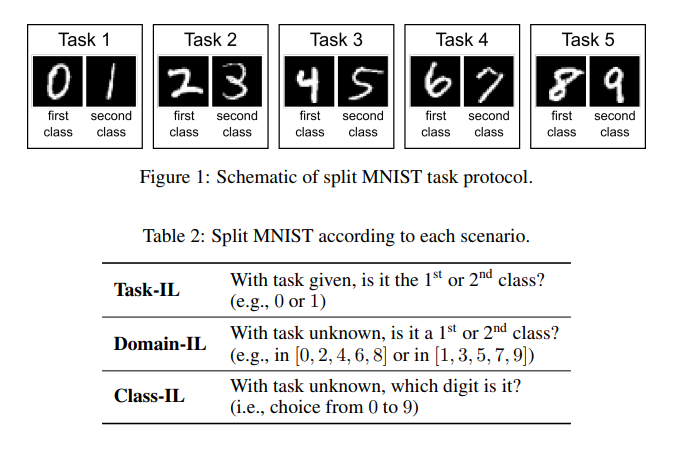
- task incremental learning
-
prompt-based learning and baseline
NLP에서 떠오르던 기술로, 기존 supervised fine-tuning과는 다르게, pre-trained model이 해당 작업을 조건부로 수행하도록 instruct하는 task-specific한 prompt functions을 설계하는 것임
The Power of Scale for Parameter-Efficient Prompt Tuning
The Power of Scale for Parameter-Efficient Prompt Tuning 리뷰- Prompt Tuning(PT)
- prompting은 일반적으로, 클래스 레이블 token Y 생성 중 조건에 맞게 일련의 토큰에 해당하는 입력 X에 일련의 토큰 P를 추가함으로써 수행되고,
모델 매개변수 θ를 고정한 채로 가능성을 극대화 함 - Prompt P가 θ에 의해 매개 변수화되는 제한을 제거하는 대신, prompt에는 업데이트할 수 있는 전용 parmeter 가 있음
- 에 대해 backpropagation하여 Y의 가능성을 최대화 하면서 만 update할 수 있음
- prompting은 일반적으로, 클래스 레이블 token Y 생성 중 조건에 맞게 일련의 토큰에 해당하는 입력 X에 일련의 토큰 P를 추가함으로써 수행되고,
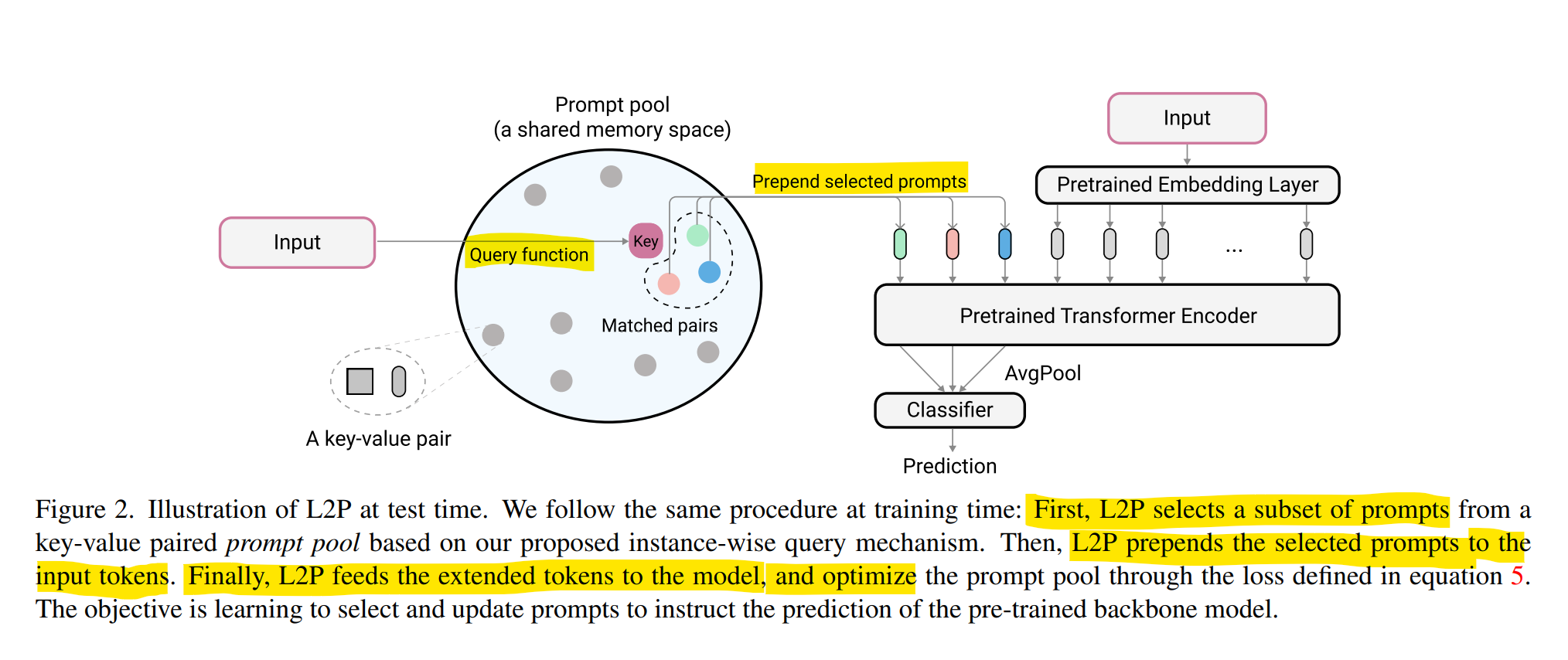

Prompt Tuning을 통해 backbone은 고정하고, 학습 가능한 parameter Prompt embedding을 학습하도록 함
- Prompt Tuning(PT)

4. Learning to Prompt(L2P)
-
From prompt to prompt pool
- prompt pool 도입 동기는 3가지임
- test time에서 task id 알 수 없으면, task id를 통한 training은 불가능함
- task id를 알고 있다고 해도 유사한 작업 간에 가능한 지식 공유를 방지함
- 단일 공유 자극을 학습하는 원래 방법은 모든 작업에 대한 지식공유를 가능하게 하지만, 여전히 forgetting 이슈를 야기 함
- 이상적으로, 작업이 유사할 때는 지식을 공유하고, 다른 경우에는 지식을 분리하는 모델을 학습해야 함
-
모델에 대한 입력으로 유연하게 그룹화할 수 있는 인코딩된 지식을 저장하기 위한 prompt pool 사용

-
- prompt pool 도입 동기는 3가지임
-
Instance-wise prompt query
- 다른 input에 대해 동적으로 suitable한 prompts를 설정하기 위해 key-value query 전략을 설계 > 각 prompt를 학습 가능한 key에 대한 값으로 연결하는데, 이상적으로는 input instance가 query-key matching을 통해 스스로 prompts를 선택하는 것input x를 key와 동일한 차원으로 encoding하는 쿼리함수 q를 도입하고,
q는 서로 다른 작업에 대해 no learnable parameter로 지정함.
γ는 쿼리와 prompt key간의 일치 점수를 보는 함수.
최종적으로는 input x에 대한 query로 key를 구하고 이와 유사한 key를 찾고 이에 대한 prompts를 추출- 사전 task-id 정보가 있으면 학습 시 더 잘 학습되도록 도움을 줄 수 있음  -
Optimization objective for L2P
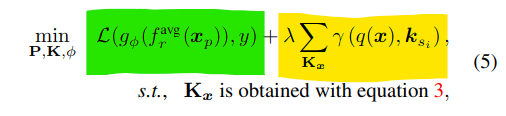
- end-to-end로 학습 손실 함수를 최소화하는데
- 위에서 고려했던 input을 key로 projection했을 때, 유사하게 matching되는 prompt를 value로 갖고있는 learnable한 key를 학습 —> 즉 유사한 input들은 어떤 특정 prompt와 연결되도록 학습
- 는 classifier, 는 분류 헤드 전의 평균, 는 로 는 학습 가능한 prompt embedding —> prompt와 x embedding은 concatenate되어서 최종 값을 prediciton하게되는데 이때 learnable한 prompt parameter를 PT관점에서 loss를 계산할듯?
- end-to-end로 학습 손실 함수를 최소화하는데

5. Experiments
1) task-id를 알 수 없는 class-incremental
2) 시간에 따라 변경되는 domain-incremental
3) task에 구애받지 않는 설정, task boundary는 불확실함
에 대해 SOTA와 비교,
- based on a pre-trained ViT-B/16
- 최신 SOTA 방법들, 리허설 기반 method들과의 비교
- Uppder-bound는 데이터를 전부 넣고 학습했을 때
- class-incremental
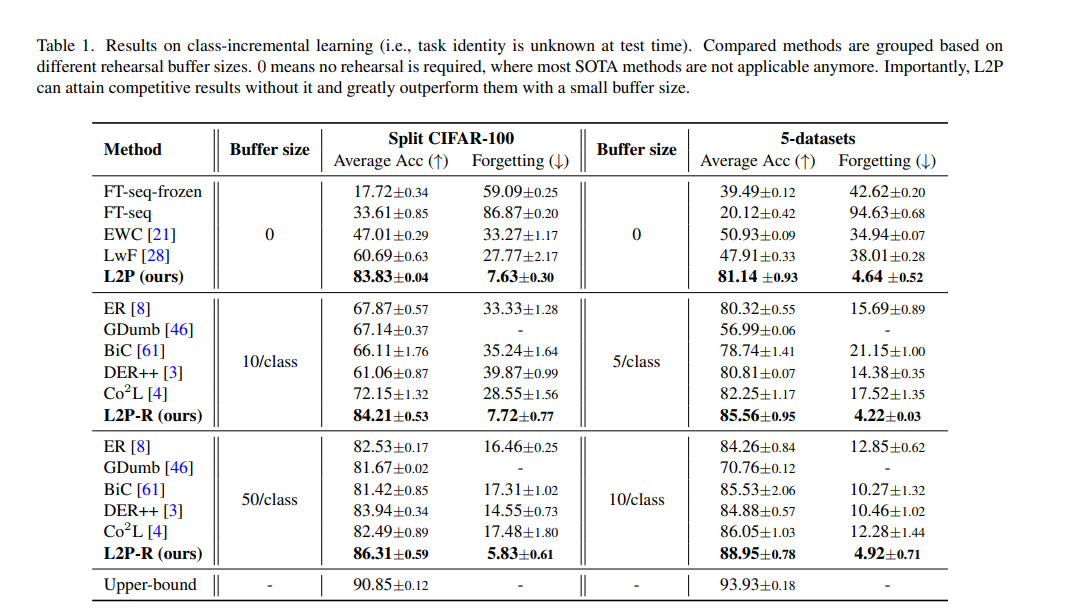
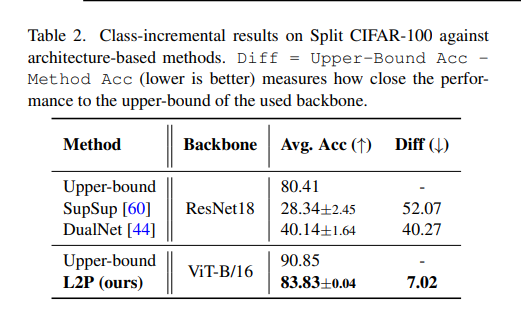
- domain-incremental
- L2P-R은 리허설 버퍼를 장착한 경우
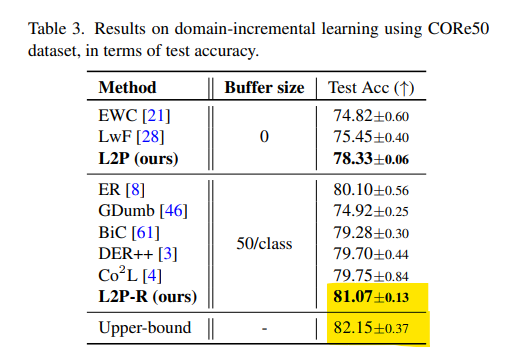
- L2P-R은 리허설 버퍼를 장착한 경우
6. Conclusion
prompt-based learning to continual learning을 통해,
catastrophic forgetting 문제를 성공적으로 완화하고,
class-, domain- incremental과 같은 여러 측면에서 이전 SOTA를 능가함
