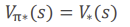18) RL1(Reinforce Learning)& Markov Decision Process
—————————————preview—————————————————
강화학습은 머신러닝/딥러닝의 한 종류로, 어떤 환경에서 어떤 행동을 했을 때
그것이 잘 된 행동인지 잘못된 행동인지를 판단하고 보상을주는 과정을 반복해서
스스로 학습하게 하는 분야 입니다. 다음과 같은 구조로 생긴 것을 알 수 있습니다.
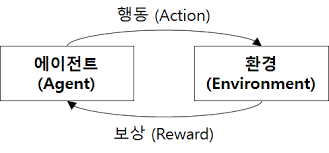
강화학습은 Markov Decision Process에 학습 개념을 추가한 것이라고 할 수 있는데
Markov Decision Process는 현재 상태에 대해서만 다음 상태가 되며, 현재 상태까지의 과정은 전혀 고려할 필요가 없습니다.
또한 이렇듯 변화 상태들이 체인처럼 엮여 있다고 하여 마르코프 체인이라고도 합니다.
———————————————————————————————————
What is reinforce learning?
The goal-> maximize the reward
state들은 feature vector로 described됩니다.
How reinforce learning is different?
1. Importance of time
2. Concept of delayed rewards
3. Interaction with environment
Main elements of RL
Reward signal: 특정한 state에 대해 이것이 얼마나 바람직한가 기준
Policy: state에 대한 action mapping
Value function: reward 함수가 얼마나 좋은지를 알려주는 value function (최종적인 reword의 기댓값)
model of the environment: model based learning
Model(Transition and reward)
Transition probability: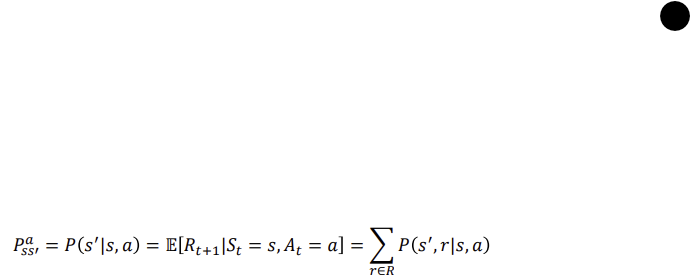
Reward function: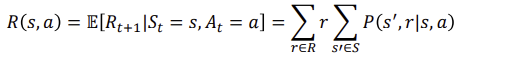
Policy and Value function
Policy: the agent’s behavior function
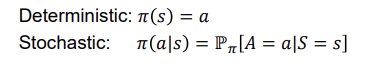
Value function: 미래 보상(reword)에 대한 예측에 의해 상태의 goodness와 s or a 에 대한 reward가 얼마나 큰지 측정
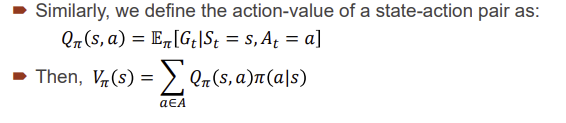
그리고 Q와 V사이의 advantage function은 다음과 같습니다. 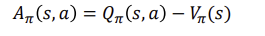
Gt : discounted reward의 total sum
Agent Types: Model-free vs Model-based
Model free 함수는 agent를 때에 따라가도록 value를 쫒아가서 reward를 예측하도록 합니다 즉, trial-and-error의 방식을 취해서 value함수를 update하도록 합니다.
Markov Process
markov chain이라고도 하며 현재 state에 대해 바로 이전 state만 관계가 있습니다. <S,P>로나타내며 이때 S는 finite set of states이고, P는 state transition probability입니다.
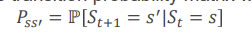
Markov Reward Process
Markov Process에 value개념이 추가된 것이며 <S,P,R,gamma>
주로 future reward에 대한 discount factor를 의미하며 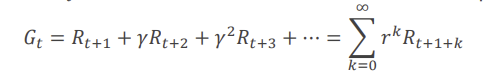
gamma가 0일 수록 근시안적인 선택을 하는 것을 알 수 있습니다.
Markov Decision Process
<S,A,P,R,gamma>
markov reward process에서 action개념이 추가된 것임을 알 수 있습니다.
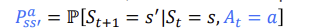
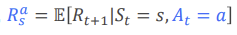
Bellman equation
강화학습의 목표에 따라 찾아진 policy를 우리는 optimal policy라고 부릅니다. 그리고 이때 추구하고자 하는 목표는 value func.의 참 값을 찾는 것이 아닌 최대의 reward를 얻는 policy를 찾는 것이며 이러한 optimal policy를 따르는 Bellman Eqn.이 바로 Bellman Optimality Equation입니다. 정리한 식은 다음과 같습니다.
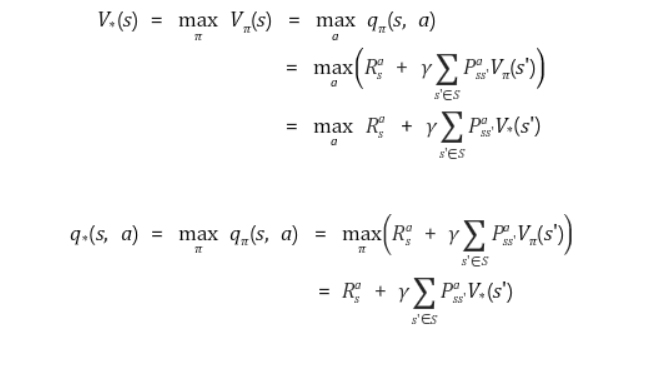
Optimal value function
the optimal state-value function V*(s) 는 모든 policies들 중 the maximum value function인 것을 알 수 있습니다.
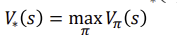
The optimal action-value function 𝑄∗(s)는 모든 policies들 중 the maximum action-value function인 것을 알 수 있습니다.
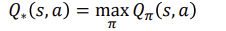
어떠한 markov decision process를 위해 모든 optimal policies는 각각의 optimal value function 및 optimal action-value function을 갖습니다.