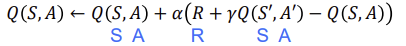Lab19) Bellman eq.
—————————————preview————————————————————
벨만 방정식에는 벨만 기대 방정식과 벨만 최적 방정식이 있는데
벨만 기대 방정식
가치함수는 단순히 어떤 상황에서 미래의 보상을 포함한 가치를 나타내는데
다음상태로 이동하려면 어떤 정책에 따라 행동해야 하는데, 이때 정책을 고려한 다음 상태로의 이동이 벨만 기대 방정식 입니다.
벨만 최적 방정식
강화학습에서 추구하고자 하는 목표는 최대의 보상을 얻는 정책을 찾는 것입니다. 즉, 최대의 보상을 얻기 위한 정책을 찾기 위해 가치 함수 값이 가장 큰 값을 찾습니다. 또한, 강화 학습에서 어떤 목표를 이루었을 때를 ‘최적’의 상태, 그리고 이러한 강화 학습 목표에 따라 찾은 정책을 최적화된 정책이라고 하며 이러한 최적화된 정책(optimal policy)을 따르는 벨만 방정식을 벨만 최적 방정식(bellman optimality equation)이라고 합니다.
——————————————————————————————————————
Notion of Solving Markov Decision process
앞선 포스팅에서 언급하였듯이 Markov Decision process는 곧 optimum value function찾기를 의미하며 Bellman equation을 만족하는 optimal policy를 찾습니다. prediction은 곧 evaluation이고 control은 곧 improvment입니다.
What is Dynamic Programming
Recursive하게 계산하는 방식으로 Subproblems의 합으로 원래 problem을 풉니다. 이는 곧 현재함수로 미래값을 예측하는데 적용되는 것을 알 수 있습니다.
DP에는 2가지 특성이 있는데
1) Optimal substructure : optimal solution은 subproblems로 분해가능하다.
2) Overlapping subproblems : recur 여러번
Markov decision process의 2가지 특성은
1) Bellman eq는 recursive decomposition을 푼다.
2) value function은 solutions 푼다.
Planning by Dynamic Programming
policy improvement is to planning in an MDP.
->for prediction(evaluation)
input: MDP and policy (pi),or MRP
output: value function
->for control(improvement)
input: MDP
output: optimal value function Vr and optimal policy(pi star)
Policy Improvement
->policy evaluation
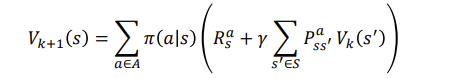
->improvement the policy(by greedy)
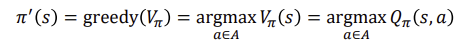
This improves the value from any state s over one step,
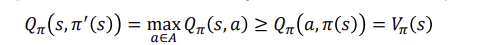
Generalized policy iteration하면 다음과 같이 말할수 있고, 그림으로 나타내면 다음과 같습니다.
Policy evaluation Estimate 𝑉 𝜋
Iterative policy evaluation
Policy improvement Generate 𝜋'>= 𝜋
Greedy policy improvement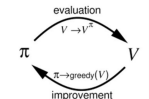
Model-free RL
Model-free prediction은 알려지지 않은 MDP의 vlaue function을 estimate하는 것이며 종류로는 다음과 같이 있습니다.

Model-free control은 알려지지 않은 MDP의 valud function을 optimize하는 것이며 종류로는 다음과 같이 있습니다.

MCvsTD
Monte-Carlo 즉, MC는 일단 랜덤하게 끝까지 진행한뒤(no bootstrapping), 끝까지 해서 나온 값들의 평균을 결과로 합니다.
Temporal-Difference 즉, TD는 이번 시도와 다음 시도 사이의 차이값을 이용해서 그 다음 시도를 진행합니다.(bootstrapping)
Monte-carlo policy evaluation
policy를 𝜋를 바탕으로 V𝜋를 learn하게 합니다. (V𝜋는 평균낸 값)
Incremental MC updates
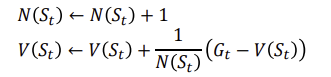
일반화된 식으로 정리하면 다음과 같습니다.
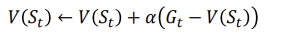
TD learning compared to MC
특정 policy 𝜋-> V𝜋 배우게 합니다.
Goal: policy 𝜋의 경험으로 부터 𝑉𝜋를 배우게 합니다.
MC의 방법으로는 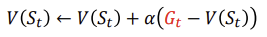
TD의 방법으로는
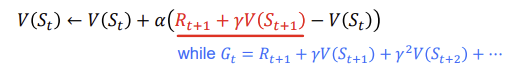
밑줄친 부분은 TD target에 해당하며 alpha()일 때 ()안의 식들은 TD error에 해당합니다.
Driving home example
예제의 plot된 그래프로 MC와 TD를 보면 다음과 같이 볼 수 있습니다.
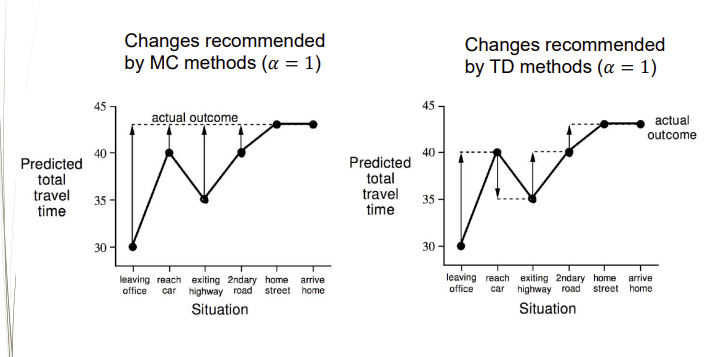
MC는 Terminal state기준 전 state와 계속 오차를 확인합니다.(끝나는 것 생각)
TD는 이전state의 상대적인 오차 확인, 계속 update 합니다.(끝나는 것 생각x)
MC와 TD 각각의 장점과 단점
MC는 terminal state까지 가야하며, high variance(단)와 low bias(장)한 특징과 Markov 특성 이용하지 않는다는 특징이 있습니다.(variance가 너무 커서 엉뚱한 곳으로 갈 수도 있습니다.)
TD(maximum likelihood) 바로바로 처리한다는 특징이 있으며, low variance(장)some
decent bias(단)특징이 있습니다. markov 특성이 이용되며 따라서, 초기값을 이용 하는데 방향이 반대일수도 있습니다.
Uses of Model-free control
딱히 model을 잡을 수 없을 때
Generalized policy iteration
Exploration vs Exploitation
agent에서는 둘다 사용할 수 있도록하며 서로 trade off관계인것을 알 수 있습니다.
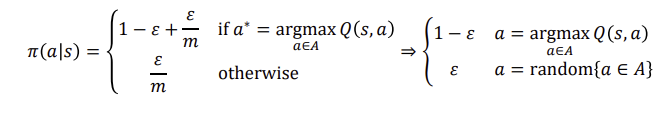
Epsilon-greedy policy improvement
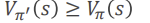
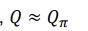
GLIE: 모든 state-action 쌍을 무한대로 explore하면 the policy는 greedy policy로 수렴한다.ㅋ

On policy TD learning
MC에비해 TD의 장점 Lower variance , Online , Incomplete sequences
So, use TD instead of MC in our control loop
Apply TD to Q(S,A), Use 𝜀-greedy policy improvement, Update every time-step
SARSA
SARSA(lamda)