——————————preview——————————————
큐러닝은 agent가 취할 수 있는 상태 개수가 많은 경우 큐-테이블 구축에 한계가 있다는 점과
데이터 간 상관관계로 학습이 어렵다는 단점이 있는데
이와 같은 단점을 보완하고자 딥 큐-러닝(Deep Q-Learning)이 출현했습니다.
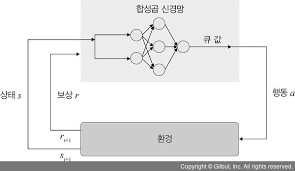
딥 큐러닝은 합성곱 신경망을 이용하여 큐 함수를 학습하는 강화 학습 기법입니다.
이때 합성곱층을 깊게 하여 훈련할 때, 큐 값의 정확도를 높이는 것을 목표로 하며
——————————————————————————————
Recall the Basic Notations
state->observation->action순으로 진행됩니다.
Imitaton learning
->supervised learning이며, data로부터 특정observation을 행했을 때 action을 하는 policy를 배울 수 있습니다.
Reward function
->RL으로 state와 action을 통해 얻는 reward를 통해 더 나은 것을 선택할 수 있습니다.
Planning Horizon
MC와TD가 존재하는데 finite horizon case: state-action marginal, 즉,state-action을 입력으로 해서 배울수 있습니다.(Trajectory)
임의의 trajectory에 대해 expectatino을 구합니다.
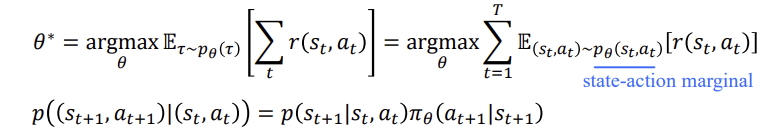
Infinite horizon case: statoinary distribution
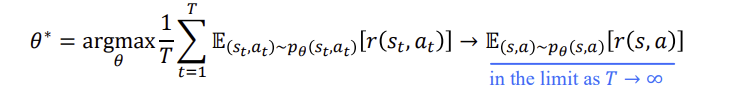
이때 위식에서 T를 inf로 보낼때 전체가 0이되는 것을 유추할 수 있습니다.p(st,at)가 stationary distribution으로 converge하는 것인가 하는 것은 state-actino transition T가 있을 때 stationary distribution 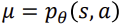 이 존재합니다.
이 존재합니다.
The Anatomy of a RL Algorithm
아래과정을 반복합니다.
1. generate samples (i.e., run the policy)
2. fit a model / estimate the return
3. improve the policy
근데 위의 과정이 자주 non-trival 하고 hard to parallelize하는데 이때 learning 에도 시간이 오래 걸립니다. Parameterized policy는 다음과 같은 과정을 거치는데 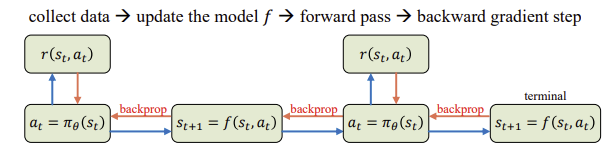
아래와 같은 특징 또한 있는데 오직 deterministic dynamics 혹은 policy만을 다룰 수 있다는 것과 continuous하기 떄문에 back propagation이 가능하며 이는 미분가능하며 continuous하다는 특징이 있습니다.
Baird's Counterexample
Baird's Counterexample Environment and Behavioral Policy
매개변수는 단순히 수렴에 실패하는 것이 아니라 양으로 발산합니다.
발진하는 문제점이 있습니다.
(임의의 MDP에 적용시킬 수 있으며 그 종류로는 다음과 같은 것들이 있습니다.)The deadly triad: Function Approcimation,Temporal Difference(수렴해야 하는데 발진함),off-policy 이러한 3가지 특징들 은 instability하게 한다.
The Deadly Triad
example이 엄한데로 가있을 때
다음 3가지를 결합할 때마다 발산의 위험이 발생합니다.
1.함수 근사치
2.Bootstrapping(반으로 쪼개서 발전시킬 가능성이 크다.)
3.off-policy learning(important sampling)
Q-러닝과 같이 해당 정책 때문이 아닌 데이터에서 정책에 대한 학습
Bootstrapping은 DP의 계산 효율성에 매우 중요하며 TD 방법의 데이터 효율성에도 매우 중요합니다.따라서 Bootstrapping은 필요합니다.
Could TD be the gradient of some?
서로 다른 weights에 대해 미분하고 그리고 그 J에 한번 더 미분합니다.
2차 도함수 행렬은 대칭이어야 하지만 그렇지 않습니다.->Conventional TD is not the gradient of anything. 그리고 그렇다면 TD를 off-policy로 합니다.
DQN to the Rescue
learning step을 stable하게합니다. 편중된 data는 쓰지 않으며 방법으로는 1)Experience replay. 즉,편중된 data가 아닌 distribution이 다 똑같습니다. 2)지난 samples모두 합한 뒤 그리고 iid를 도출하는방식 입니다. 이 방법은 Q-function의 update에 있어서 feedback loops를 사용함으로써 증폭을 방지하는 것입니다. 3)TD-error를 고정함으로써 error range가 너무 커지지 않도록 즉, 수렴하도록 clipping하는 것입니다.
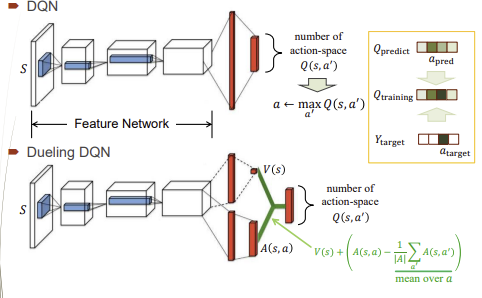
Deep Q-Learning Network (DQN)
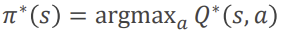
위 식에서 볼 수 있듯이 Q값이 최대가 되는 a를 구합니다.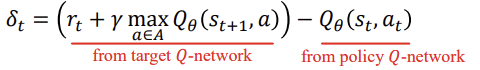
Q-update는 bellman equation을 통해 하며 loss function은 궁극적으로 0이되게 합니다.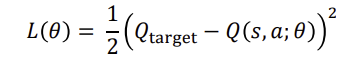
충분히 training될 때까지 안 바꾸며 모든 action에 대한 qㄱ밧을 다 줍니다. (마치 table처럼)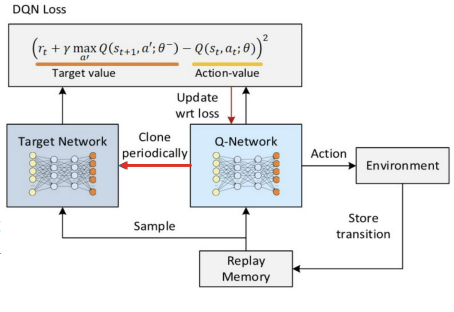
Experience Replay and Replay Memory
replay memory쓰는 주된 이유는 correlation없이 쓰고 싶어서 이며 replay memory에서 랜덤 샘플을 뽑으면 이 상관 관계가 끊어집니다
The DQN Control Algorithm
사람이 하는 game처럼 화면을 보고... state가 화면에 반영됩니다.
만들어진 weight를 target으로 copy합니다. policy를 target으로 copy합니다.
DQN in Atari
화면에서 state가 pixels s로 나타내고,4 frames으로 4가지 방향이 있으며, Q(s,a) for 18 joystick/button positions,score for that step
Double DQN
항상 max를 따라가므로 평균을 넘어가는 문제가 있습니다.Q network는 action을 하며 Target Q network->최종 답이 되는 값은 여기서 뽑습니다.
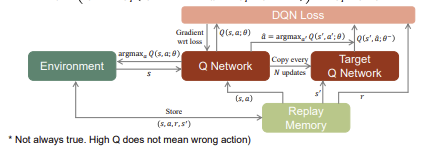
Q-Learning vs DQN vs DDQN
Q-Learning Target
Double Q-Learning Target
DQN Target Value
DDQN Target Value
위의 식을 각각 보면 다음과 같습니다.
Q-Learning Target :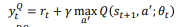
Double Q-Learning Target :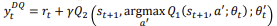
DQN Target Value :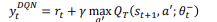
DDQN Target Value :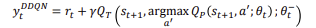
모든 action에 대한 Q값을 한꺼번에 내주고, 이 값들 중에 MAX를 뽑아서 처리합니다.
Prioritized Experience Replay (PER)
target이 되는 Q값, 오차가 큰것...
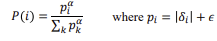
식에서 입실론은 우연히 되는 경우를 없애기 위해서 쓰이는 항이며
알파값은 TD error를 기반으로한 우선 순위를 지정한 것 입니다.
Improtance sampling은 distribution이 바뀌면서 원래 것과 다른 distribution, 자주 선택되더라도 과다 반영하기는 싫은 것을 반영한 것입니다.
Sampling and the SumTree Data Structure
PER Data Structure에서 Experience Array,SumTree 는 다음과 같이 볼 수 있습니다.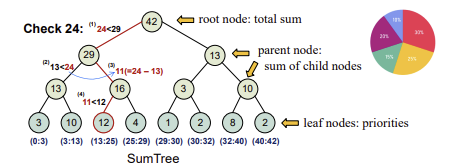
SumTree는 error값이 들어가 있는 list,array입니다.
DDQN with Prioritized Experience Replay
DQN->DDQN의 과정을 거치는 것으로 다음 그림의 pseudo code처럼 진행됩니다. 
Double Dueling Deep Q-Network

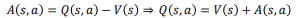
value는 먼 데 있는 것을 예측하는 것이며, advantage는 가까운것을 예측 및 강조하는 것입니다.
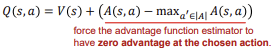
위 식에서 Advantage항을 0으로 보내는 것입니다.
Network Architecture
DQN과 Dueling DQN은 1개였던 filter를 2개로 나눠서 과정을 수행합니다.