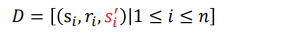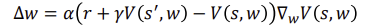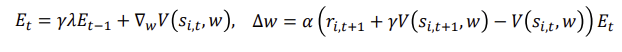20) RL3:Tabular Q learning
————————preview——————————
Q-learning은 agent가 주어딘 상태에서 행동을 취했을 경우 받을 수 있는 보상의 기댓값을 예측하는 큐-함수(Q-function)를 사용하여 최적화된 정책을 학습하는 강화 학습 기법입니다. 즉, 큐-러닝은 여러 실험(episode)을 반복하여 최적의 정책을 학습합니다.
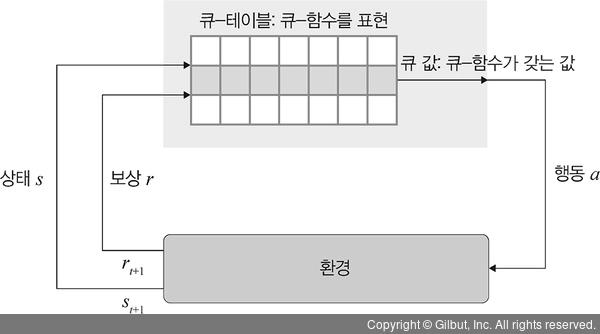
보상을 최대화할 수 있는 행동을 수행하려면 활용과 탐험 사이의 균형이 필요합니다.
탐험은 매 실험에서 각 상태마다 수행하는 랜덤한 선택의 행동을 의미하며 활용은 현재까지 경험 중 현 상태에서 가장 푀대의 보상을 받을 수 있는 행동을 하는 것입니다.
—————————————————————
On-policy vs off-policy
learning을 control하는 것에 대해서 optimal한 value를 찾기 위해서는 optimal하지 않은 방식을 선택하기도 한다.
on-policy
가지고 있는 policy에 대해서만 선택
off-policy
현재 사용하지 않는 polilcy에 대해서 선택
behavior policy를 suboptimal한 것을 하고 evaluate는 동일하게 진행한다.
off-policy->
잘된 agent를 통해 배운다.
기존에 쌓아놓은 경험을 통해 배우는 것을 활용할 수도 있음
policy여러개를 통해 배울 수 있다.
Importance sampling
P에서 뽑고 싶은데 못 뽑을 때 Q에서 대신 뽑을 수 있음.
with MC일때는 끝까지 갈 수 밖에 없음. variance가 계속 늘어남.
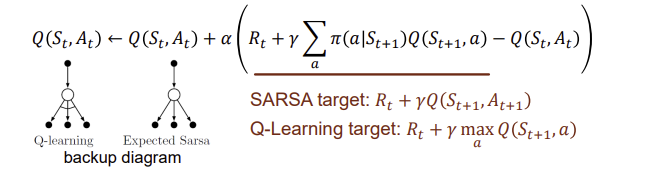
Q-Learning: Off-Policy TD Control
target에 대해서만 진행. variance가 MC보다 더 off-policy적용 후 수렴하게 만들기가 더 쉽다.
단점
중요도 표본 추출의 가장 큰 단점은 분산입니다. 가중치가 큰 몇 개의 나쁜 표본은 추정량을 급격히 떨어뜨릴 수 있습니다.
두 번째 단점은 두 밀도를 모두 정규화해야 한다는 것이며, 이는 종종 다루기 어렵습니다.
앞에서 존재하는 drawbacks들을 극복하는 방법으로 고안된 q-learning. state에대해 action이 들어갈때 off-policy,,value값은 state에 대한 값들, q값은 action에 대한 값이므로 behavior policy 𝝁 is e.g. 𝜺-greedy,target policy 𝝅 is greedy하게 합니다.
Q-Learning Algorithm Flowchart
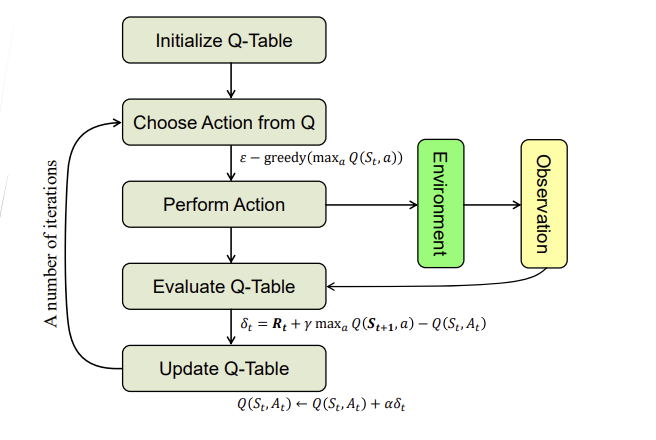
q-table을 먼저 만들고,어떤 state에서 어떤 action을 하면~ 에 대한 값들...,Q로 부터 action을 선택하는 방법은 epsilon-greedy하게 한 후, action을 perform합니다. 그리고 environment에서 observation하는 과정을 통해 Q-table을 evaluate합니다. 그리고 이후에 그림 안의 식을 통해 Q-table을 update합니다. 그리고 update된 Qtable을 통해 다시 action을 선택하는 과정을 반복합니다.
SARSA Algorithm vs Q-Learning Algorithm
SARSA는 on-policy,Q-learninig은 off-policy, on-policy두가지 다 가능.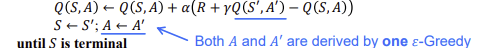
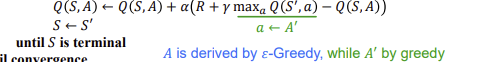
Expected SARSA
The Performance of TD Control Methods
sarsa는 안정적인 선택을 하는 경우가 크다. q-learning이 좀 더 exploration을 하는 경우.
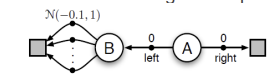
Double Q-Learning
궁극적으로 가면 왼쪽으로 가면 -0.1로 더 손해인 상황인데 왼쪽으로 가는 경우. greedy라는 것 때문에 따라서 이러한 경우를 방지하기 위해 double q-learning이라는 방법을 사용.
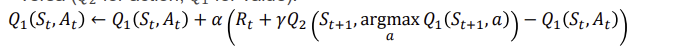
Double Q Algorithm
q1과 q2양쪽에서 최대가 나오는 값을 사용해서 둘중하나 선택하는 방식으로
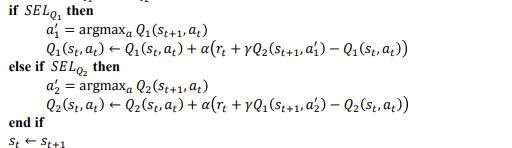
table이 2개인 경우를 의미.
Large-Scale Reinforcement Learning
state가 너무 많으면 table도 너무 크고 이러한 경우 생기는 문제들.state자체가 continuous하면 table이 만들어지지 않는데 이러한 문제가 생기는 경우에는 function approximation을 사용.
Which Function Approximator?
value함수를 weight개념이 있는 함수를 만들 수 있음.
parameter update.이러한 개념을 사용하려면 non stationary data를 다룰 수 있어야함.
Value Fn Approx. by Stochastic Gradient Descent
cost함수를 통해 gradient descent(grobal minimum을 향해서 간다.)를 사용해서 function approx.를 진행.원래는 expectation인데 그렇게 안하고 sample을 많이넣어서 궁극적으로 진행되는 방식 deep nn와 같은 방식과 비슷함.
Linear Value Function Approximation
Incremental Prediction Algorithm
차근 차근 쫒아가는 방식. 처음부터 알고 있지 않으니,
Action-Value Function Approximation
function approx.에서 예측한값과 같아지도록 policy evaluation을 진행, epsilon-greedy policy improvement를 통해 policy improvement를 진행.
Incremental Control Algorithms

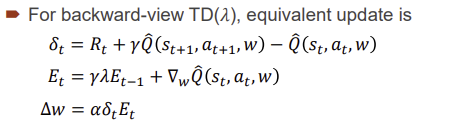
Incremental Reinforcement Learning, But?
RL에는 진정한 값을 제공하는 감독자가 없으며 보상만 제공합니다.
이에 따라 발생하는 문제들,
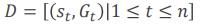

보다 풍부한 RL 알고리즘 범위를 산출하는 2가지 주요 패턴필요
1. Experience-Replay : 데이터가 도착하면 저장 후 재사용
2. Batch RL: 전체 데이터 배치에 대한 값 fn을 직접 학습합니다더 많은 데이터를 활용하는 방법? Batch 방법을 쓴다.
Batch MC Prediction
묶어서 사용. 묶어서 평균값을 이용하는 것.
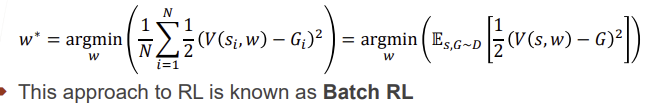
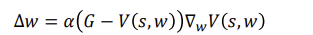
Batch TD Prediction