의사결정나무(Decision Tree)
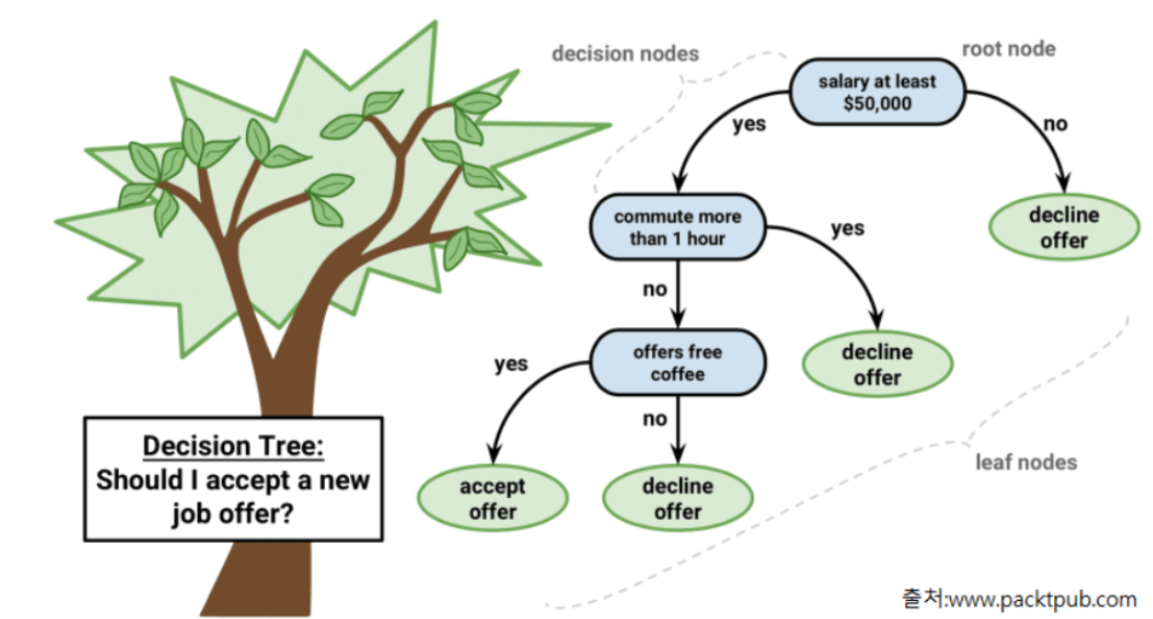
개요
- 데이터를 잘 분류할 수 있는 질문을 던져 가며 대상을 좁혀가는 '스무고개'와 비슷한 형식의 알고리즘.
- 추론결과을 위해 분기해 나가는 구조가 Tree 구조와 같기 때문에 Decision Tree 라고 한다.
- 노드안의 원소들의 불순도 최대한 감소하는 방향(최대한 한 class의 값들만 있는 상태)으로 조건을 만들어 학습을 진행한다.
- 하위노드는 yes/no 두 개로 분기 된다.
- 분기 기준
- 분류: 가장 불순도를 낮출수 있는 조건을 찾아 분기한다.
- 회귀: 가장 오차가 적은 조건을 찾아 분기 한다.
- 머신러닝 모델들 중 몇 안되는 White box 모델로 추론 결과에 대한 해석이 가능하다.
- 과대적합(Overfitting)이 발생하기 쉽다.
- 앙상블기반 알고리즘인 랜덤 포레스트와 많은 부스팅(Boosting)기반 앙상블 모델들의 기반 알고리즘으로 사용된다.
순도(purity)/불순도(impurity)
- 서로 다른 종류의 값들이 섞여 있는 비율
- 한 종류(class)의 값이 많을 수록 순도가 높고 불순도는 낮다.
용어
- Root Node : 시작 node
- Decision Node (Intermediate Node): 중간 node
- Leaf Node(Terminal Node) : 마지막 단계(트리의 끝)에 있는 노드로 최종결과를 가진다.
과대적합(Overfitting) 문제
- 모든 데이터셋이 모두 잘 분류 되어 불순도가 0이 될때 까지 분기해 나간다.
- Root에서 부터 하위 노드가 많이 만들어 질 수록 모델이 복잡해져 과대적합이 발생할 수 있다.
- 과대적합을 막기 위해서는 적당한 시점에 하위노드가 더이상 생성되지 않도록 해야 한다.
- 하위 노드가 더이상 생성되지 않도록 하는 것을 가지치기(Pruning) 라고 한다.
하이퍼파라미터
- max_depth
- 트리의 최대 깊이(질문 단계)를 정의
- 기본값: None - 깊이 제한 없이 완벽히 분할 될때 까지 분기한다.
- 분류: 불순도가 0이 될때 까지, 회귀: MSE가 0이 될 때 까지
- max_leaf_nodes
- Leaf Node 개수 제한한다.
- 기본값: None - 제한없다.
- ex) max_leaf_nodes=10 -> 전체 Tree의 leaf node가 최대 10개를 넘을 수 없다.
- min_samples_leaf
- Leaf Node가 가져야 하는 최소한의 sample (데이터) 수를 지정한다.
- 개수를 지정할 수 도있고(정수), 전체 샘플대비 비율로 지정(0.0 ~ 0.5 실수)할 수 있다.
- ex: min_sample_leaf=5 -> 모든 leaf node는 최소한 5개 데이터를 가져야한다. 그래서 5개가 되면 더이상 분기하지 않는다.
- 기본값: 1 -> 제한이 없다.
- max_features
- 분기 할 때마다 지정한 개수의 Feature(특성)만 사용한다.
- 다음 값 중 선택한다.
- None(기본값): 전체 Feature를 다 사용한다.
- 정수: 개수를 지정한다.
- 0 ~ 1 사이 실수: 전체 개수 대비 비율
- "sqrt": 전체 특성개수의 제곱근 개수만큼만 사용한다.
- "log2": 만큼만 사용한다.
- Feature 가 25개일 경우
- 'sqrt' 는 이므로 5개 Feature를 사용
- 'log2' 는 이므로 5개 특성 사용
- min_samples_split
- 분할 하기 위해서 필요한 최소 샘플 수를 정의. 정의한 개수보다 더 적은 샘플을 가진 노드는 더이상 분기 되지 않는다.
- 기본값: 2
- ex) min_samples_split=10 -> sample 수가 10 미만인 노드는 더이상 분기되지 않는다.
- criterion
- 각 노드의 분기 여부를 결정하는 값을 계산하는 방식을 정의한다. (계산 결과가 0이 되면 분기하지 않는다.)
- 분류
- "gini"(기본값), "entropy"
- 회귀
- "squared_error"(기본값), "absolute_error", "friedman_mse", "poisson"
Feature(컬럼) 중요도 조회
- featureimportances 속성
- 모델을 학습 결과를 기반으로 각 Feature 별 중요도를 반환
- 전처리 단계에서 input data 에서 중요한 feature들을 선택할 때 decision tree를 이용한다.
Wine Dataset을 이용한 color 분류
- https://archive.ics.uci.edu/ml/datasets/Wine+Quality
- features
- 와인 화학성분들
- fixed acidity : 고정 산도
- volatile acidity : 휘발성 산도
- citric acid : 시트르산
- residual sugar : 잔류 당분
- chlorides : 염화물
- free sulfur dioxide : 자유 이산화황
- total sulfur dioxide : 총 이산화황
- density : 밀도
- pH : 수소 이온 농도
- sulphates : 황산염
- alcohol : 알콜
- quality: 와인 등급 (A>B>C)
- 와인 화학성분들
- target - color
- 0: white, 1: red
import pandas as pd wine = pd.read_csv("data/wine.csv") wine.shape(6497, 13)
데이터셋 분리 및 전처리
전처리
- 범주형 타입인 quality에 대해 Label Encoding 처리
- DecisionTree 계열 모델
- 범주형: Label Encoding, 연속형: Feature Scaling을 하지 않는다.
- 선형계열 모델(예측시 모든 Feature들을 한 연산에 넣어 예측하는 모델)
- 범주형: One Hot Encoding, 연속형: Feature Scaling을 한다.
- DecisionTree 계열 모델
# X, y X = wine.drop(columns='color').values y = wine['color'].valuestrain/test set 분리
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, stratify=y, random_state=0)## quality LabelEncoding. 범주형 변수를 숫자형으로 변환. from sklearn.preprocessing import LabelEncoder le = LabelEncoder() le.fit(['A', 'B', 'C']) X_train[:, -1] = le.transform(X_train[:, -1]) # 마지막 열(color)를 레이블 인코딩하여 변환 X_test[:, -1] = le.transform(X_test[:, -1])DecisionTreeClassifier 생성 ,학습, 검증
from sklearn.tree import DecisionTreeClassifier tree = DecisionTreeClassifier(random_state=0) tree.fit(X_train, y_train)print("Depth 조회:", tree.get_depth()) print("Leaf nodes의 개수:", tree.get_n_leaves())Depth 조회: 13
Leaf nodes의 개수: 55from metrics import print_binary_classification_metrics print_binary_classification_metrics( y_train, tree.predict(X_train), tree.predict_proba(X_train)[:, 1], "Train set 평가결과" )Train set 평가결과
정확도: 0.9997947454844006
재현율: 1.0
정밀도: 0.9991666666666666
F1 점수: 0.9995831596498541
Average Precision: 0.9999986099527384
ROC-AUC Score: 0.9999997729299327print_binary_classification_metrics( y_test, tree.predict(X_test), tree.predict_proba(X_test)[:, 1], "Test set 평가결과" )Test set 평가결과
정확도: 0.9858461538461538
재현율: 0.965
정밀도: 0.9772151898734177
F1 점수: 0.9710691823899371
Average Precision: 0.9516280428432327
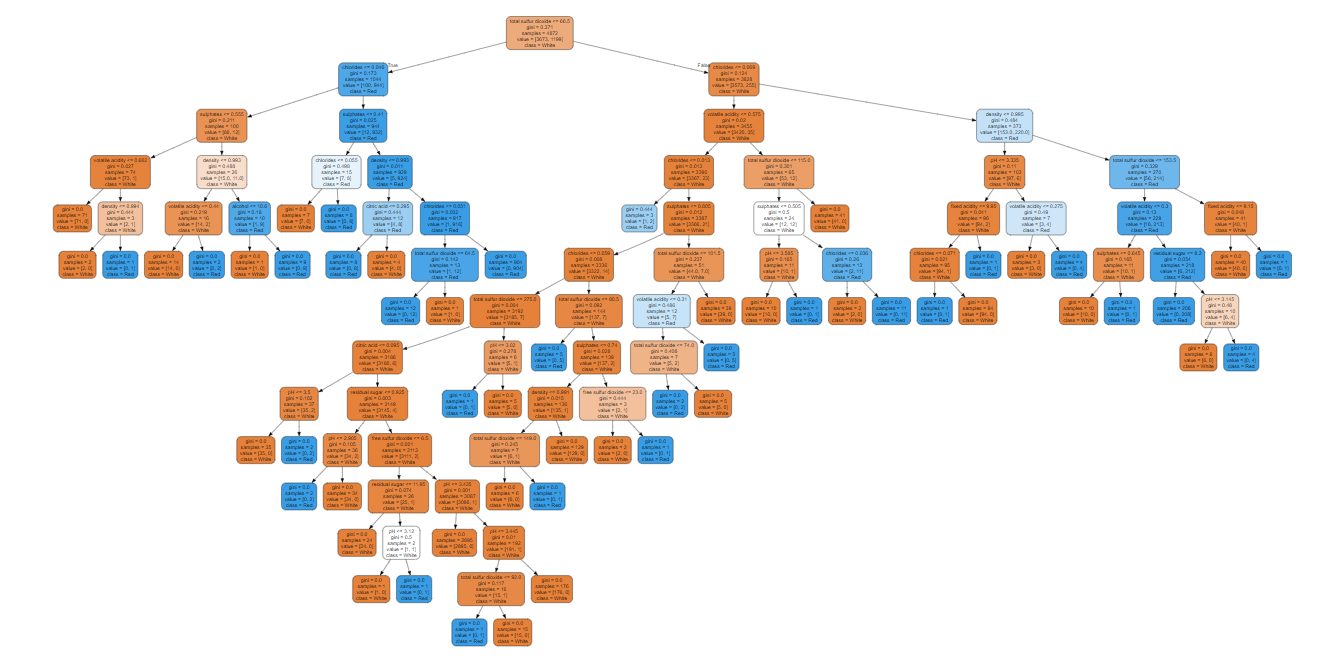
ROC-AUC Score: 0.9788265306122449Graphviz를 이용해 tree구조 시각화
from sklearn.tree import export_graphviz from graphviz import Source graph = Source( export_graphviz( tree, feature_names=wine.columns[:-1], class_names=['White', 'Red'], filled=True, rounded=True ) ) graph
export_graphviz( tree, feature_names=wine.columns[:-1], class_names=['White', 'Red'], filled=True, rounded=True, out_file="wine_tree_model.dot" # 소스코드를 파일로 저장. ) # 저장된 dot 파일을 image로 변환 - CLI명령어. !dot -Tpng wine_tree_model.dot -o wine_tree_model.png
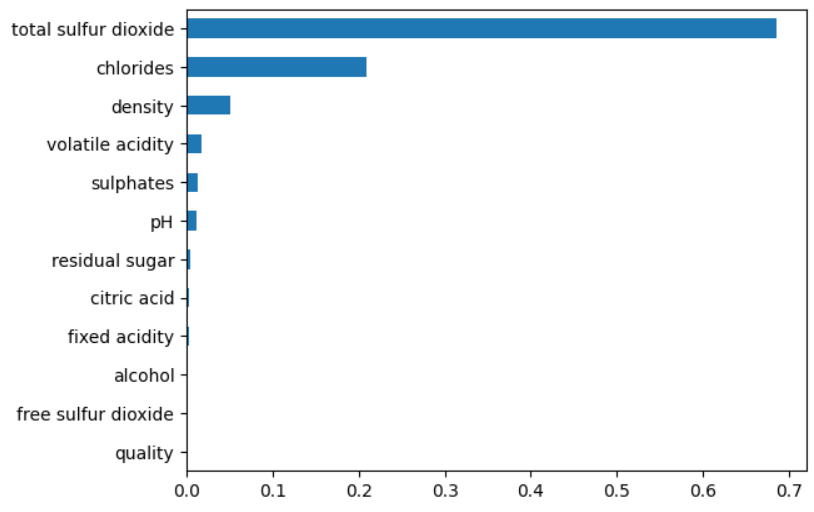
Feature 중요도 조회
- 데이터 전처리 단계에서 추론에 전혀 도움이 안되는 Feature들을 찾아낼 때 사용할 수 있다.
### fit() 뒤에 feature 중요도 조회 fi = tree.feature_importances_ fiarray([0.00215273, 0.0170795 , 0.00306507, 0.00443252, 0.20950343,
0.00077958, 0.68631811, 0.05093937, 0.01158388, 0.01314941,
0.00099639, 0. ])import pandas as pd pd.Series(fi, index=wine.columns[:-1]).sort_values(ascending=False)total sulfur dioxide 0.686318
chlorides 0.209503
density 0.050939
volatile acidity 0.017080
sulphates 0.013149
pH 0.011584
residual sugar 0.004433
citric acid 0.003065
fixed acidity 0.002153
alcohol 0.000996
free sulfur dioxide 0.000780
quality 0.000000
dtype: float64pd.Series(fi, index=wine.columns[:-1]).sort_values().plot(kind='barh');
RandomizedSearchCV 적용
- 가지치기(모델 복잡도 관련 규제) 파라미터 찾기
- max_depth, max_leaf_nodes, min_samples_leaf 최적의 조합을 GridSearch를 이용해 찾아본다.(accuracy기준)
- bestestimator 를 이용해서 feature 중요도를 조회한다.
- bestestimator를 이용해 graphviz로 구조를 확인한다.
RandomizedSearchCV 생성, 학습
from sklearn.model_selection import RandomizedSearchCV params = { "max_depth": range(1, 14), "max_leaf_nodes": range(10, 56), "min_samples_leaf": range(10, 1000, 50), "max_features": range(1, 13) } gs = RandomizedSearchCV( DecisionTreeClassifier(random_state=0), params, cv=5, n_jobs=-1, n_iter=60 ) gs.fit(X_train, y_train)결과확인
gs.best_params_{'min_samples_leaf': 10,
'max_leaf_nodes': 10,
'max_features': 12,
'max_depth': 9}gs.best_score_0.9811178855367768
best_model = gs.best_estimator_ fi = pd.Series(best_model.feature_importances_, index=wine.columns[:-1]).sort_values(ascending=False) fitotal sulfur dioxide 0.715779
chlorides 0.214657
density 0.052025
volatile acidity 0.009644
residual sugar 0.004070
sulphates 0.003825
fixed acidity 0.000000
citric acid 0.000000
free sulfur dioxide 0.000000
pH 0.000000
alcohol 0.000000
quality 0.000000
dtype: float64
회귀
- DecisionTreeRegressor 사용
import pandas as pd from sklearn.model_selection import train_test_split df = pd.read_csv("data/boston_hosing.csv") X = df.drop(columns='MEDV') y = df['MEDV'] X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0) X_train.shape, X_test.shape((379, 13), (127, 13))
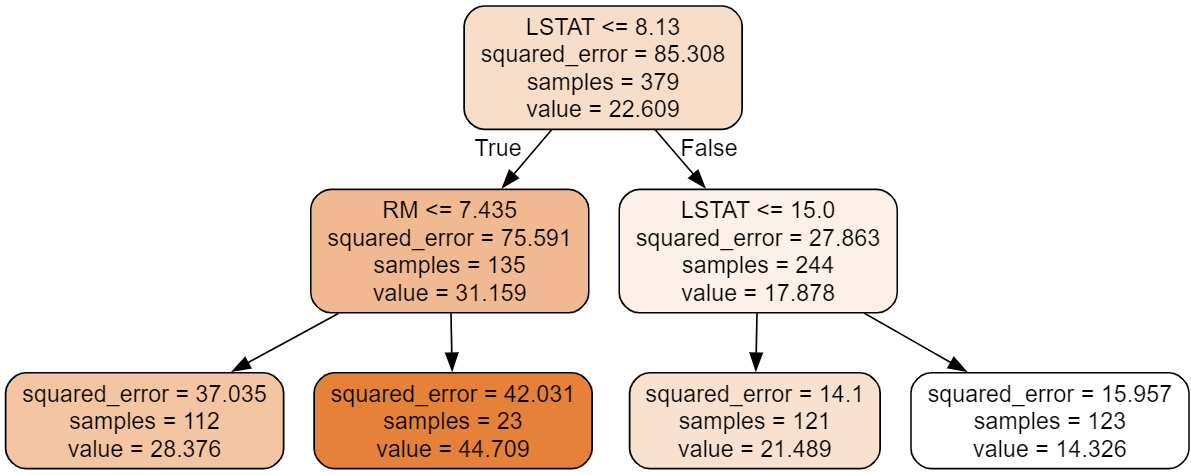
from sklearn.tree import DecisionTreeRegressor, export_graphviz from graphviz import Source from metrics import print_regression_metrics model = DecisionTreeRegressor(max_depth=2, random_state=0) model.fit(X_train, y_train)## 분기 구조를 시각화 graph = Source( export_graphviz( model, feature_names=X.columns, filled=True, rounded=True ) ) graph
LSTAT <= 8.13 # 노드를 분기하기 위한 질문 (오차가 가장 적게 나뉘도록 하는 질문) =============아래: 현재 노드의 상태================= squared_error = 85.308 # 현재 노드로 추론했을 때(value) 예상 오차(mean squared error) samples=379 # 현재노드의 데이터(sample) 개수 value = 22.609 # 현재노드로 추론했을때 결과값. (이 노드 y값들의 평균)print_regression_metrics(y_train, model.predict(X_train))MSE: 23.175292750947712
RMSE: 4.814072366608931
R Squared: 0.7283346372537175print_regression_metrics(y_test, model.predict(X_test))MSE: 33.32551599016633
RMSE: 5.772825650421666
R Squared: 0.5920940318375818
Ensemble(앙상블)
- 하나의 모델만을 학습시켜 사용하지 않고 여러 모델을 학습시켜 결합하는 방식으로 문제를 해결하는 방식
- 개별로 학습한 여러 모델을 조합해 과적합을 막고 일반화 성능을 향상시킬 수 있다.
- 개별 모델의 성능이 확보되지 않을 때 성능향상에 도움될 수 있다.
앙상블의 종류
1. 투표방식
- 여러개의 추정기(Estimator)가 낸 결과들을 투표를 통해 최종 결과를 내는 방식
- 종류
- Bagging - 같은 유형의 알고리즘들을 조합하되 각각 학습하는 데이터를 다르게 한다.
- Random Forest가 Bagging을 기반으로 한다.
- Voting - 서로 다른 종류의 알고리즘들을 결합한다.
- Bagging - 같은 유형의 알고리즘들을 조합하되 각각 학습하는 데이터를 다르게 한다.
2. 부스팅(Boosting)
- 약한 학습기(Weak Learner)들을 결합해서 보다 정확하고 강력한 학습기(Strong Learner)를 만든다.
- 각 약한 학습기들은 순서대로 일을 하며 뒤의 학습기들은 앞의 학습기가 찾지 못한 부분을 추가적으로 찾는다.
Random Forest (랜덤포레스트)
- Bagging 방식의 앙상블 모델
- Decision Tree를 기반으로 한다.
- 다수의 Decision Tree를 사용해서 성능을 올린 앙상블 알고리즘의 하나
- N개의 Decision Tree 생성하고 입력데이터를 각각 추론하게 한 뒤 가장 많이 나온 추론결과를 최종결과로 결정한다.
- 처리속도가 빠르며 성능도 높은 모델로 알려져 있다.
- Random: 학습할 때 Train dataset을 random하게 sampling한다.
- Forest: 여러개의 (Decision) Tree 모델들을 앙상블한다.
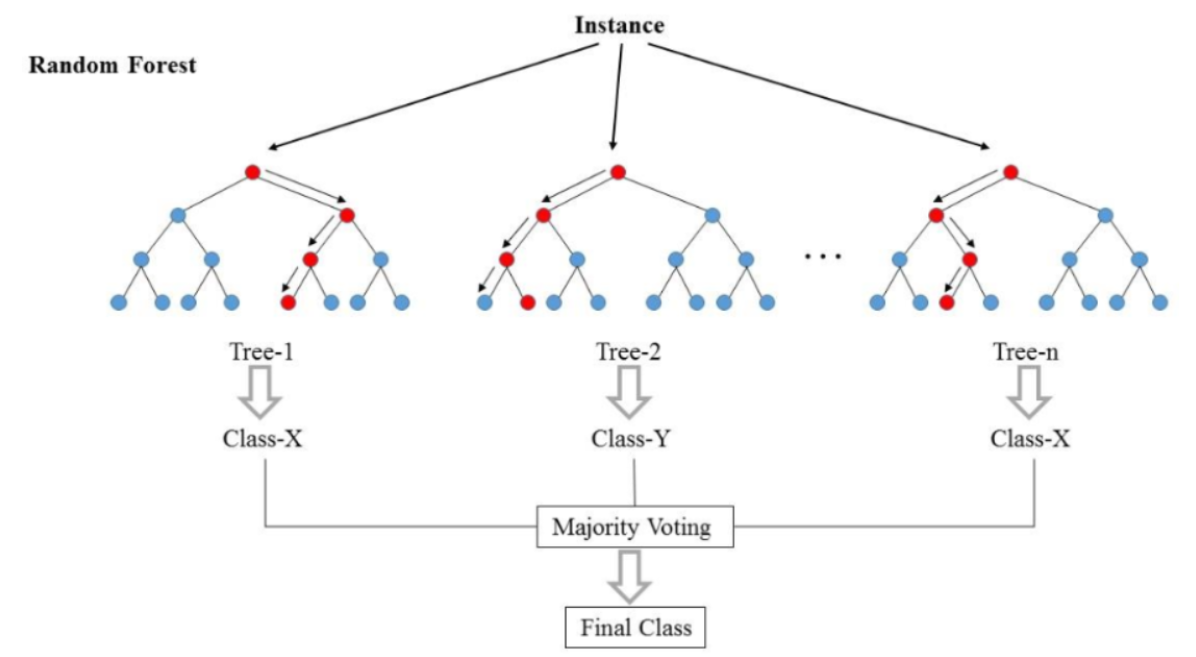
- 랜덤포레스트의 절차
- 객체 생성시 Decision Tree의 개수, Decision Tree에 대한 하이퍼파라미터들 등을 받아서 생성한다.
- 모든 DecisionTree들은 같은 구조를 가지게 한다.
- 학습시 모든 Decision Tree들이 서로 다른 데이터셋으로 학습하도록 Train dataset으로 부터 생성한 DecisionTree개수 만큼 sampling 한다.
- 부트스트랩 샘플링(중복을 허용하면서 랜덤하게 샘플링하는 방식)으로 데이터셋을 준비한다. (총데이터의 수는 원래 데이터셋과 동일 하지만 일부는 누락되고 일부는 중복된다.)
- Sampling된 데이터셋들은 전체 피처중 일부만 랜덤하게 가지게 한다.
- 각 트리별로 예측결과를 내고 분류의 경우 그 예측을 모아 다수결 투표로 클래스 결과를 낸다.
- 회귀의 경우는 예측 결과의 평균을 낸다.
- 객체 생성시 Decision Tree의 개수, Decision Tree에 대한 하이퍼파라미터들 등을 받아서 생성한다.
- 주요 하이퍼파라미터
- n_estimators
- DecisionTree 모델의 개수
- 학습할 시간과 메모리가 허용하는 범위에서 클수록 좋다.
- max_features
- 각 트리에서 선택할 feature의 개수
- 클수록 각 트리간의 feature 차이가 크고 작을 수록 차이가 적게 나게 된다.
- DecisionTree의 하이퍼파라미터들
- Tree의 최대 깊이, 가지를 치기 위한 최소 샘플 수 등 Decision Tree에서 과적합을 막기 위한 파라미터들을 랜덤 포레스트에 적용할 수 있다.
- n_estimators
와인 데이터셋 color 분류
train/test set 분리
import pandas as pd from sklearn.model_selection import train_test_split df = pd.read_csv('data/wine.csv') X = df.drop(columns=['color', 'quality']) y = df['color'] X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)RandomForestClassifier 생성, 학습, 검증
from sklearn.ensemble import RandomForestClassifier rfc = RandomForestClassifier( n_estimators=200, # DecisionTree 개수. (최소 200개) max_features=10, # 지정한 feature수 내에서 random하게 feature들을 선택. max_depth=5, # DecisionTree hyper parameter (모든 DT모델들은 동일한 형태.) random_state=0, n_jobs=-1, # 개별 DecisionTree 학습, 추론시 병렬 처리 (각 모델은 독립적으로 학습/추정한다.) )rfc.fit(X_train, y_train) # class 추정 pred_train = rfc.predict(X_train) pred_test = rfc.predict(X_test) # class 별 확률 pred_train_proba = rfc.predict_proba(X_train) pred_test_proba = rfc.predict_proba(X_test)from metrics import print_binary_classification_metrics print_binary_classification_metrics( y_train, pred_train, pred_train_proba[:, 0], "Train set 검증결과" ) print_binary_classification_metrics( y_test, pred_test, pred_test_proba[:, 1], "Test set" )Train set 검증결과
정확도: 0.9950738916256158
재현율: 0.9799833194328608
정밀도: 1.0
F1 점수: 0.9898904802021904
Average Precision: 0.15864233040170136
ROC-AUC Score: 0.001007509888333753
Test set
정확도: 0.9870769230769231
재현율: 0.9675
정밀도: 0.979746835443038
F1 점수: 0.9735849056603774
Average Precision: 0.9940479931929254
ROC-AUC Score: 0.9967744897959184Feature importance
fi = pd.Series(rfc.feature_importances_, index=X.columns).sort_values(ascending=False) fitotal sulfur dioxide 0.503064
chlorides 0.382871
volatile acidity 0.036238
density 0.026470
sulphates 0.016476
fixed acidity 0.011452
pH 0.009814
residual sugar 0.008413
citric acid 0.002299
alcohol 0.001950
free sulfur dioxide 0.000951
dtype: float64
