K-최근접 이웃 (K-Nearest Neighbors, KNN)
- 분류(Classification)와 회귀(Regression) 를 모두 지원한다.
- 예측하려는 데이터와 Train set 데이터들 간의 거리를 측정해 가장 가까운 K개의 데이터셋의 레이블을 참조해 추론한다.
- 학습시 단순히 Train set 데이터들을 저장만 하며 예측 할 때 거리를 계산한다.
- 학습은 빠르지만 예측시 시간이 많이 걸린다.
추론 알고리즘
분류
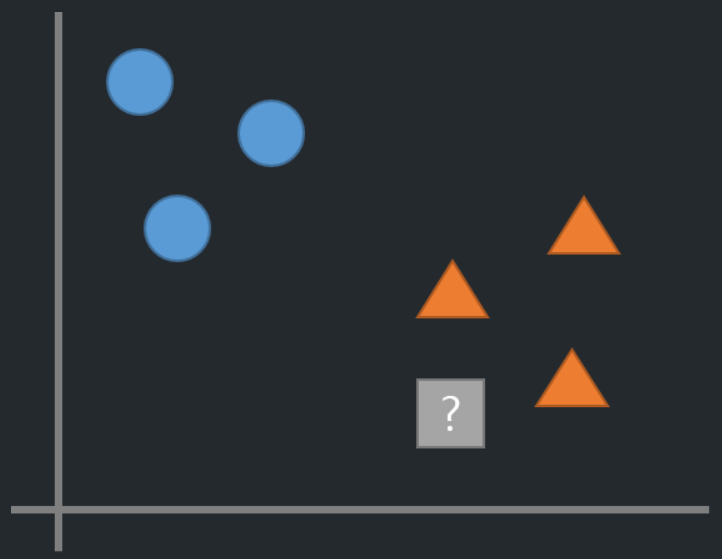
- K-NN에서 K는 새로운 데이터포인트를 분류할때 확인할 데이터 포인트의 개수를 지정하는 하이퍼파라미터
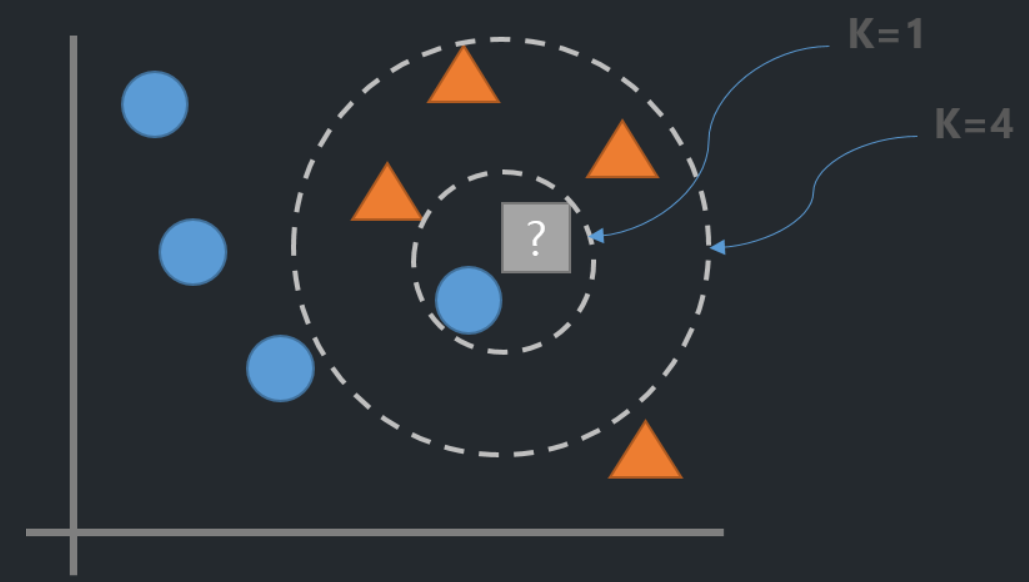
회귀
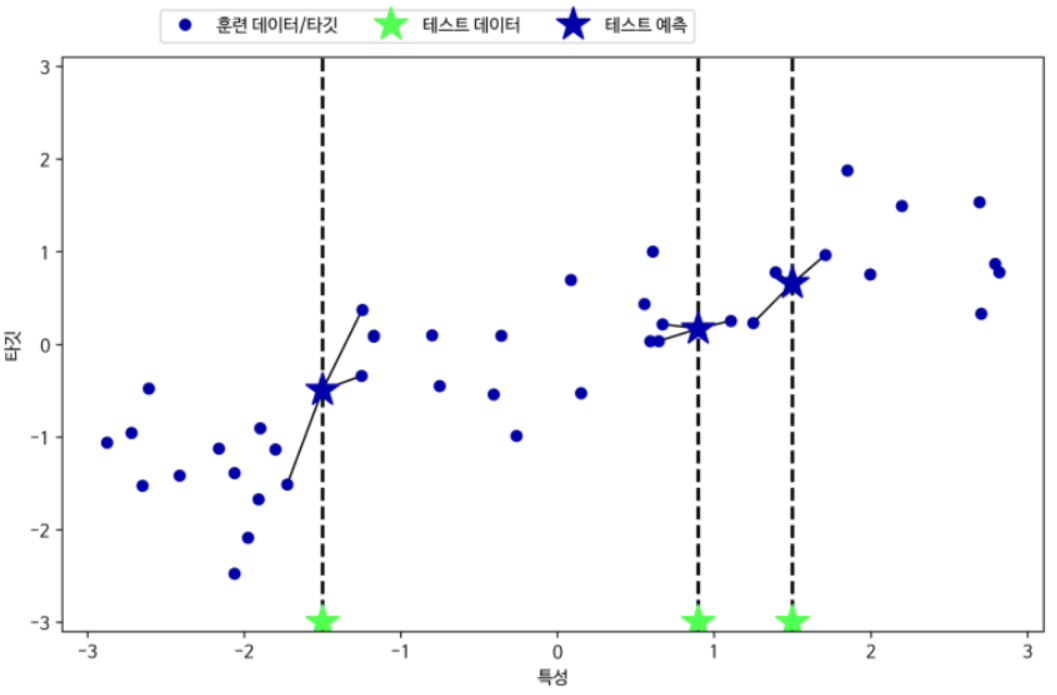
- 분류
- 추론할 feature들과 가까운 feature들로 구성된 data point K 개의 y중 다수의 class로 추론한다.
- 회귀
- 추론할 feature들과 가까운 feature들로 구성된 data point K 개의 y값의 평균값으로 추론한다.
- K가 너무 작으면 Overfitting이 일어날 수 있고 K가 너무 크면 Underfitting이 발생할 수 있다.
- Overfitting: K값을 더 크게 잡는다.
- Underfitting: K값을 더 작게 잡는다.
주요 하이퍼 파라미터
- 분류: sklearn.neighbors.KNeighborsClassifier, 회귀: sklearn.neighbors.KNeighborsRegressor
- 이웃 수
- n_neighbors = K
- K가 작을 수록 모델이 복잡해져 과대적합이 일어나고 너무 크면 단순해져 성능이 나빠진다.(과소적합)
- n_neighbors는 Feature수의 제곱근 정도를 지정할 때 성능이 좋은 것으로 알려져 있다.
- 거리 재는 방법
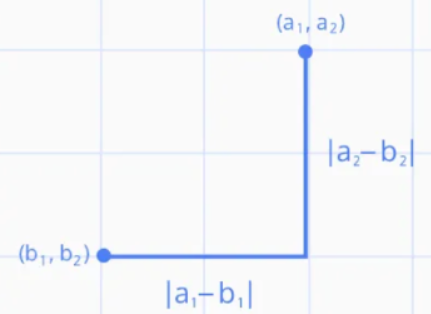
- p=2: 유클리디안 거리(Euclidean distance - 기본값 - L2 Norm)
- p=1: 맨하탄 거리(Manhattan distance - L1 Norm)
유클리디안 거리(Euclidean_distance)
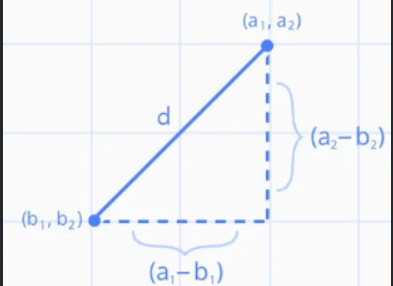
맨하탄 거리 (Manhattan distance)
요약
- K-NN은 이해하기 쉬운 모델이며 튜닝할 하이퍼파라미터의 수가 적어 빠르게 만들 수있다.
- K-NN은 서비스할 모델을 구현할때 보다는 복잡한 알고리즘을 적용해 보기 전에 확인용 또는 base line을 잡기 위한 모델로 사용한다.
- 훈련세트가 너무 큰 경우(Feature나 관측치의 개수가 많은 경우) 거리를 계산하는 양이 늘어나 예측이 느려진다.
- 추론에 시간이 많이 걸린다.
- Feature간의 값의 단위가 다르면 작은 단위의 Feature에 영향을 많이 받게 되므로 전처리로 Feature Scaling작업이 필요하다.
- Feature가 너무 많은 경우와 대부분의 값이 0으로 구성된(희소-sparse) 데이터셋에서 성능이 아주 나쁘다
위스콘신 유방암 데이터를 이용한 암환자분류
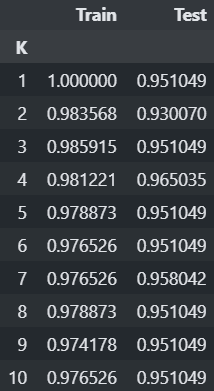
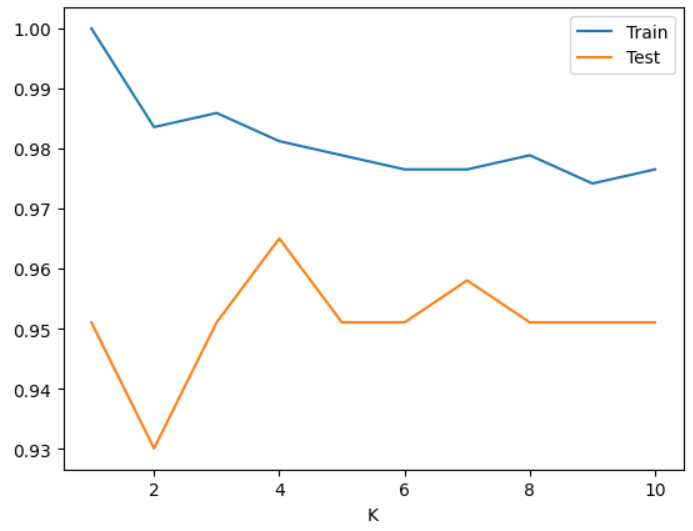
from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split X, y = load_breast_cancer(return_X_y=True) X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) X_test_scaled = scaler.transform(X_test)### K값 변화에 따른 성능 변화를 체크 from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import accuracy_score train_acc_list = [] test_acc_list = [] for k in range(1, 11): # 모델 생성 knn = KNeighborsClassifier(n_neighbors=k) #default: 유클리디안 디스턴스로 거리계산. # 학습 knn.fit(X_train_scaled, y_train) # knn.fit(X_train, y_train) # 검증 train_acc_list.append(accuracy_score(y_train, knn.predict(X_train_scaled))) test_acc_list.append(accuracy_score(y_test, knn.predict(X_test_scaled))) # train_acc_list.append(accuracy_score(y_train, knn.predict(X_train))) # test_acc_list.append(accuracy_score(y_test, knn.predict(X_test)))import pandas as pd df = pd.DataFrame({ "K":range(1, 11), "Train":train_acc_list, "Test":test_acc_list }) df.set_index("K", inplace=True) df # K가 작을 수록 모델의 복잡도가 높다. overfitting일 경우 K를 더 크게 잡아준다.
df.plot();
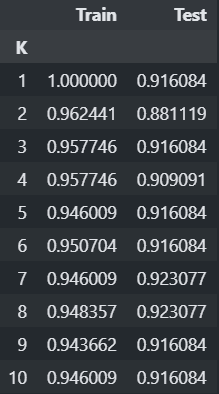
## Feature Scaling 하지 않은 X로 학습한 결과 import pandas as pd df = pd.DataFrame({ "K":range(1, 11), "Train":train_acc_list, "Test":test_acc_list }) df.set_index("K", inplace=True) df
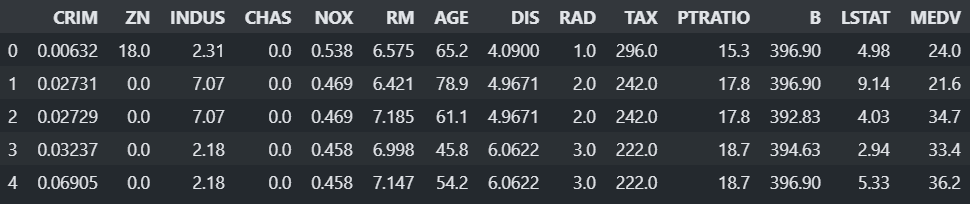
Boston Housing Dataset 집값 예측
import pandas as pd df = pd.read_csv("data/boston_hosing.csv") df.head()
X = df.drop(columns='MEDV').values y = df['MEDV'].valuesfrom sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)### GridSearchCV로 최적 K값, p값 찾기 from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler from sklearn.neighbors import KNeighborsRegressor from sklearn.model_selection import GridSearchCV pipeline = Pipeline([ ("scaler", StandardScaler()), ("knn", KNeighborsRegressor()) ]) params = { "knn__n_neighbors":range(3, 10), "knn__p":[1, 2] } gs = GridSearchCV(pipeline, params, scoring="neg_mean_squared_error", cv=4, n_jobs=-1) gs.fit(X_train, y_train)
gs.best_params_{'knnn_neighbors': 3, 'knnp': 1}
-gs.best_score_18.73019870598482
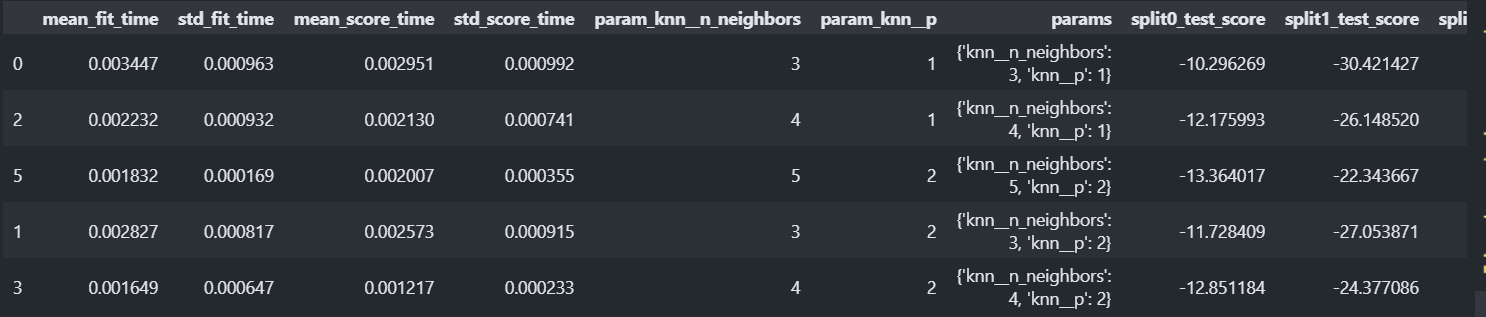
df = pd.DataFrame(gs.cv_results_) df.sort_values('rank_test_score').head(5)
# 최종평가 from metrics import print_regression_metrics best_model = gs.best_estimator_ pred = best_model.predict(X_test) print_regression_metrics(y_test, pred, "최종평가")최종평가
MSE: 29.62185476815397
RMSE: 5.442596326033557
R Squared: 0.6374270288407293

공부 & 프로젝트 & 개발 블로그