Ensemble - Boosting Model
부스팅(Boosting)이란 단순하고 약한 학습기(Weak Learner)들를 결합해서 보다 정확하고 강력한 학습기(Strong Learner)를 만드는 방식.
정확도가 낮은 하나의 모델을 만들어 학습 시킨뒤, 그 모델의 예측 오류는 두 번째 모델이 보완한다. 이 두 모델을 합치면 처음보다는 정확한 모델이 만들어 진다. 합쳐진 모델의 예측 오류는 다음 모델에서 보완하여 계속 더하는 과정을 반복한다. 즉 약한 학습기들은 앞 학습기가 만든 오류를 줄이는 방향으로 학습한다
GradientBoosting
- 개별 모델로 Decision Tree 를 사용한다.
- depth가 깊지 않은 트리를 많이 연결해서 이전 트리의 오차를 보정해 나가는 방식으로 실행한다.
- 각 모델들은 앞의 모델이 틀린 오차를 학습하여 전체 오차가 줄어들드록 학습한다.
- 얕은 트리를 많이 연결하여 각각의 트리가 데이터의 일부에 대해 예측을 잘 수행하도록 하고 그런 트리들이 모여 전체 성능을 높이는 것이 기본 아이디어.
- 분류와 회귀 둘다 지원하는 모델 (GradientBoostingClassifier, GrandientBoostingRegressor)
- 훈련시간이 많이 걸리고, 트리기반 모델의 특성상 희소한 고차원 데이터에서는 성능이 안 좋은 단점이 있다.
GradientBoosting 학습 및 추론 프로세스
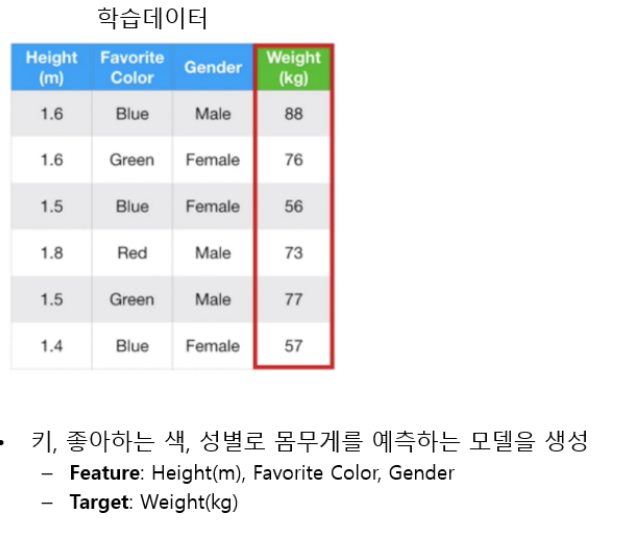
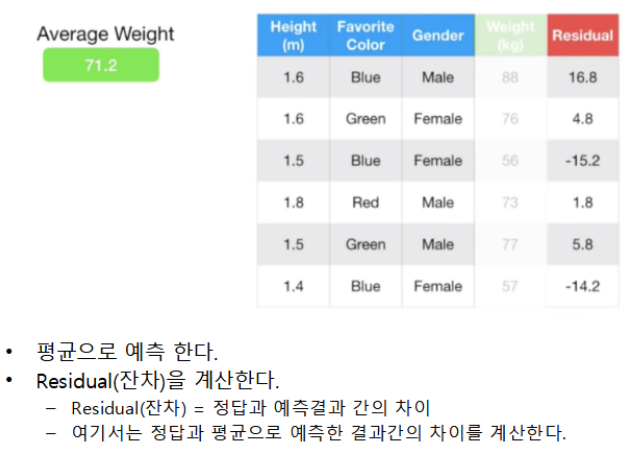

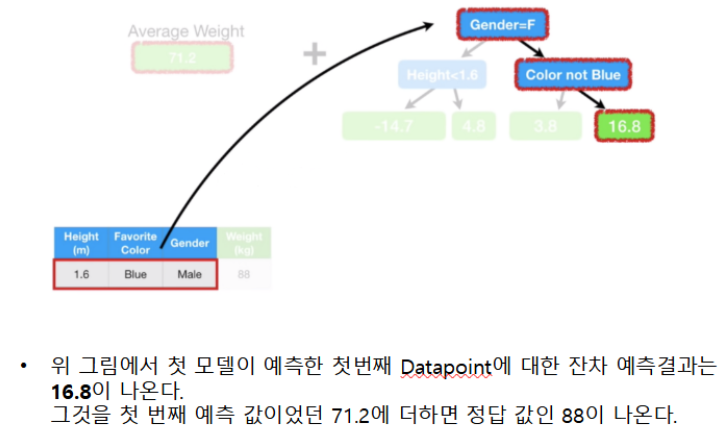

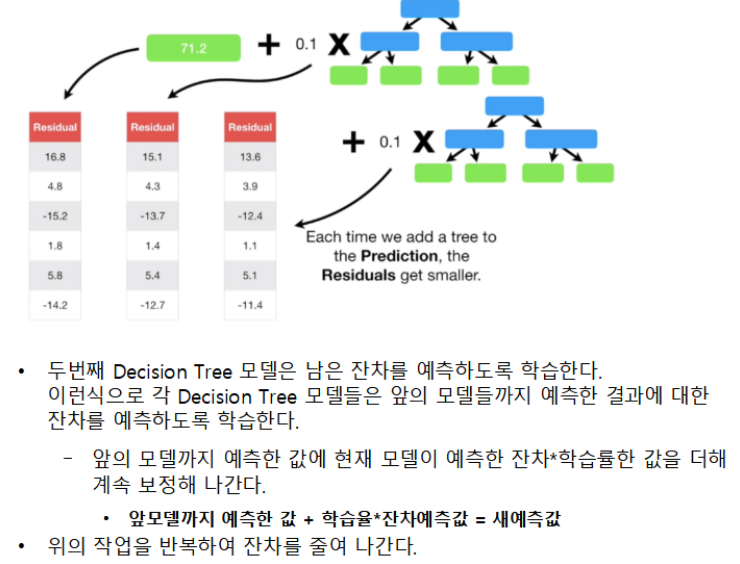
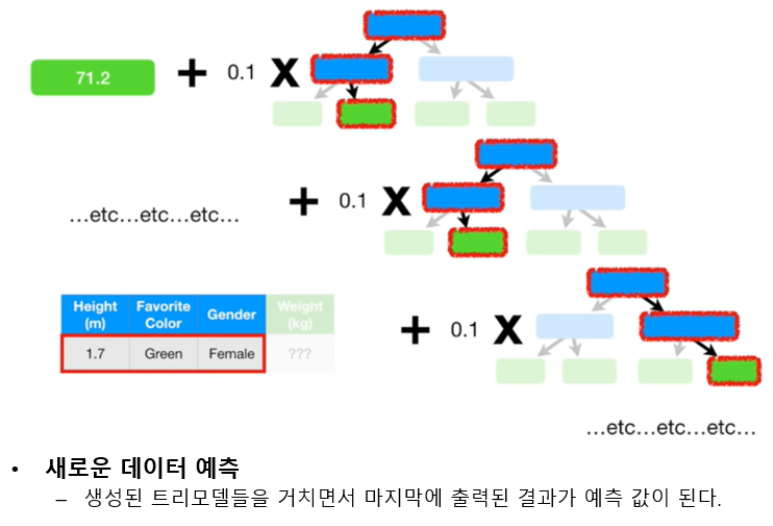
이미지 참조: https://www.youtube.com/watch?v=3CC4N4z3GJc&list=PLblh5JKOoLUICTaGLRoHQDuF_7q2GfuJF&index=49
주요 파라미터
-
Decision Tree 의 가지치기 관련 매개변수
- 각각의 decision tree가 복잡한 모델이 되지 않도록 한다.
-
learning rate
- 이전 decision tree의 오차를 얼마나 강하게 보정할 것인지 제어하는 값.
- 값이 크면 보정을 강하게 하여 복잡한 모델을 만든다. 학습데이터의 정확도는 올라가지만 과대적합이 날 수있다.
- 값을 작게 잡으면 보정을 약하게 하여 모델의 복잡도를 줄인다. 과대적합을 줄일 수 있지만 성능 자체가 낮아질 수있다.
- 기본값 : 0.1
-
n_estimators
- decision tree의 개수 지정. 많을 수록 복잡한 모델이 된다.
-
n_iter_no_change, validation_fraction
- validation_fraction에 지정한 비율만큼 n_iter_no_change에 지정한 반복 횟수동안 검증점수가 좋아 지지 않으면 훈련을 조기 종료한다.
-
보통 max_depth를 낮춰 개별 decision tree의 복잡도를 낮춘다. 보통 5가 넘지 않게 설정한다. 그리고 n_estimators를 가용시간, 메모리 한도에 맞춰 크게 설정하고 적절한 learning_rate을 찾는다.
########### 위스콘신 유방암 데이터 ############## from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split X, y = load_breast_cancer(return_X_y=True) X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)GradientBoostingClassifier 모델 생성, 학습, 평가
from sklearn.ensemble import GradientBoostingClassifier # , GradientBoostingRegressor gbc = GradientBoostingClassifier(random_state=0) gbc.fit(X_train, y_train) pred_train = gbc.predict(X_train) pred_test = gbc.predict(X_test) pred_train_proba = gbc.predict_proba(X_train)[:, 1] pred_test_proba = gbc.predict_proba(X_test)[:, 1]from metrics import print_binary_classification_metrics print_binary_classification_metrics(y_train, pred_train, pred_train_proba, "Train set") print_binary_classification_metrics(y_test, pred_test, pred_test_proba, "Test set")Train set
정확도: 1.0
재현율: 1.0
정밀도: 1.0
F1 점수: 1.0
Average Precision: 1.0
ROC-AUC Score: 1.0
Test set
정확도: 0.958041958041958
재현율: 0.9555555555555556
정밀도: 0.9772727272727273
F1 점수: 0.9662921348314607
Average Precision: 0.9741338688529869
ROC-AUC Score: 0.9776729559748428# Learning Rate 변화에 따른 성능 변화 import time max_depth = 1 n_estimators = 10_000 # lr = 0.0001 # 1e-4 lr = 0.01 # 1e-2 gbc = GradientBoostingClassifier( n_estimators=n_estimators, learning_rate=lr, max_depth=max_depth, random_state=0 ) s = time.time() gbc.fit(X_train, y_train) e = time.time() pred_train = gbc.predict(X_train) pred_test = gbc.predict(X_test)print(f"학습률: {lr}, n_estimators: {n_estimators}, fit 시간: {e-s}초") print_binary_classification_metrics(y_train, pred_train, title="============Train set 평가") print_binary_classification_metrics(y_test, pred_test, title="============Test set 평가")학습률: 0.01, n_estimators: 10000, fit 시간: 15.180491209030151초
============Train set 평가
정확도: 1.0
재현율: 1.0
정밀도: 1.0
F1 점수: 1.0
============Test set 평가
정확도: 0.958041958041958
재현율: 0.9555555555555556
정밀도: 0.9772727272727273
F1 점수: 0.9662921348314607
학습률: 0.0001, n_estimators: 10000, fit 시간: 14.542805671691895초
============Train set 평가
정확도: 0.9413145539906104
재현율: 0.9887640449438202
정밀도: 0.9230769230769231
F1 점수: 0.9547920433996383
============Test set 평가
정확도: 0.916083916083916
재현율: 0.9888888888888889
정밀도: 0.89
F1 점수: 0.9368421052631579
XGBoost(Extra Gradient Boost)
- https://xgboost.readthedocs.io/
- Gradient Boost 알고리즘을 기반으로 개선해서 분산환경에서도 실행할 수 있도록 구현 나온 모델.
- Gradient Boost의 단점인 느린수행시간을 해결하고 과적합을 제어할 수 있는 규제들을 제공하여 성능을 높임.
- 회귀와 분류 모두 지원한다.
- 캐글 경진대회에서 상위에 입상한 데이터 과학자들이 사용한 것을 알려저 유명해짐.
- 두가지 개발 방법
- 설치
- conda install -y -c anaconda py-xgboost
- pip install xgboost
Scikit-learn 래퍼 XGBoost
- XGBoost를 Scikit-learn프레임워크와 연동할 수 있도록 개발됨.
- Scikit-learn의 Estimator들과 동일한 패턴으로 코드를 작성할 수 있다.
- GridSearchCV나 Pipeline 등 Scikit-learn이 제공하는 다양한 유틸리티들을 사용할 수 있다.
- XGBClassifier: 분류
- XGBRegressor : 회귀
주요 매개변수
- learning_rate : 학습률, 보통 0.01 ~ 0.2 사이의 값 사용
- n_estimators : week tree 개수
- Decision Tree관련 하이퍼파라미터들
예제
from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split X, y = load_breast_cancer(return_X_y=True) X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)from xgboost import XGBClassifier # , XGBRegressor xgb = XGBClassifier(n_estimators=1000, learning_rate=0.01, max_depth=1, random_state=0) xgb.fit(X_train, y_train)
print_binary_classification_metrics( y_train, xgb.predict(X_train), xgb.predict_proba(X_train)[:, 1], "Trainset" ) print_binary_classification_metrics( y_test, xgb.predict(X_test), xgb.predict_proba(X_test)[:, 1], "Test set" )Trainset
정확도: 0.9929577464788732
재현율: 1.0
정밀도: 0.9888888888888889
F1 점수: 0.994413407821229
Average Precision: 0.9989988706056906
ROC-AUC Score: 0.9985160059359762
Test set
정확도: 0.965034965034965
재현율: 0.9777777777777777
정밀도: 0.967032967032967
F1 점수: 0.9723756906077348
Average Precision: 0.9891074862749493
ROC-AUC Score: 0.9837526205450735

