데이터 분석과 관련된 다양한 기능을 제공하는 패키지.
표 형태의 데이터를 다루는데 특화된 파이썬 모듈.
표 형태의 데이터를 다루기 위한 Series, DataFrame 클래스 제공
Series
- 1차원 자료구조
- DataFrame의 한 행(row)이나 한 열(column)을 표현
- 각 원소는 index와 index 이름을 가짐
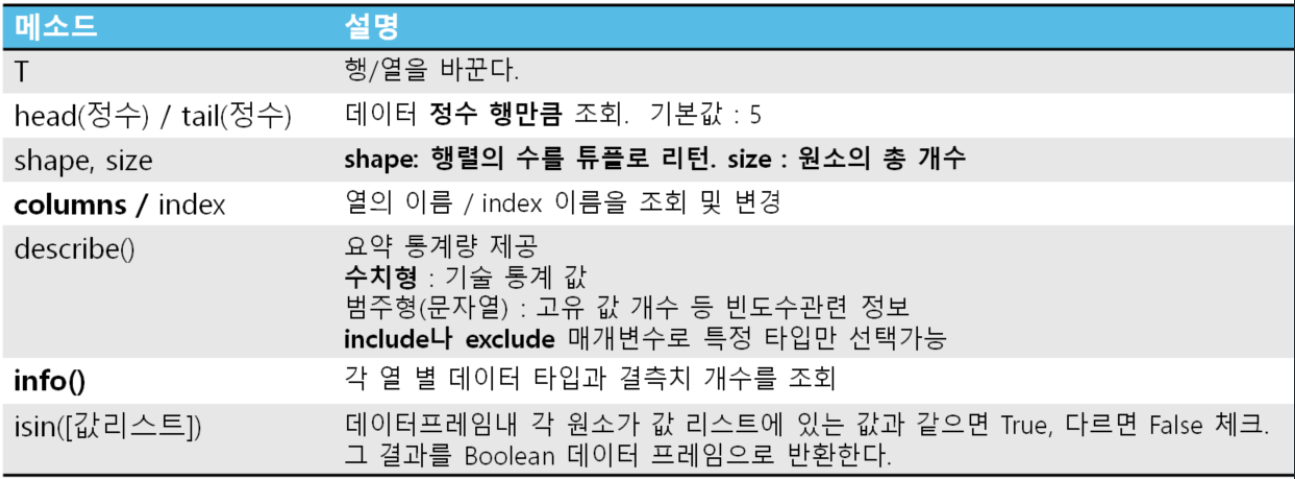
메소드
.shape : 차원별 원소 개수
.size : 총 원소 개수
.index : index 이름 조회
.rename({현재이름 : 바꿀이름}) : index 이름 변경
.between(값1, 값2) : 값1 ~ 값2 사아의 값인지 비교
.head([정수])/tail([정수]) : 원소를 정수 개수만큼 조회. 기본값 : 5
.dtype : 데이터타입 조회
.astype(데이터타입) : 데이터타입 변경
.isin([값리스트]) : Series의 원소가 값리스트의 값들 중 하나와 같으면 True, 다르면 False인 boolean Series 반환
.sort_values()/sort_index() : 값(sort_values)/index명(sort_index)을 기준으로 정렬. ascending=False :내림차순, True가 기본(오름차순)
.value_counts() : 고유한 값의 빈도수 조회(DataFrame은 지원안함). normalize=True 지정하면 상대빈도수(비율)로 반환.
.nunique() : 고유 값의 개수를 조회
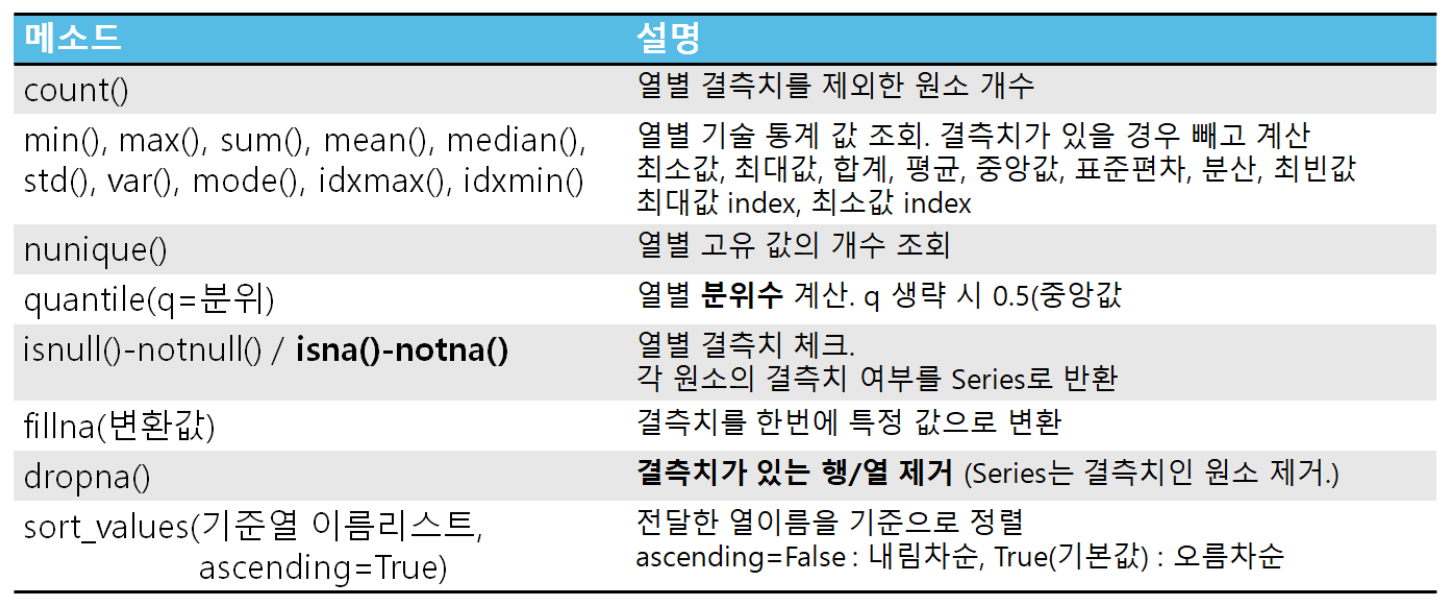
.count() : 결측치를 제외한 원소 개수
.median(), std(), var(), mode(), idxmax(), idxmin() : 결측치가 있을 경우 빼고 계산. 순서대로 중앙값, 표준편차, 분산, 최빈값, 최대값 index, 최소값 index
.describe() : 요약 통계량 제공
.quantile(q=분위) : 분위수 계산. q 생략 시 0.5 (중앙값)
.isnull()/notnull() : 결측치 체크. 각 원소의 결측치 여부를 Series로 리턴
.fillna(변환값) : 결측치를 한번에 특정값으로 변환
.dropna() : 결측치를 제거 (DataFrame은 행/열을 지운다.)
Indexing
- Series.iloc[순번] : index을 순번으로 조회
- Series[index이름], Series.loc[index이름] : index 이름으로 조회
- Series[index리스트] : 팬시 index. 한번에 여러개의 원소를 조회
ex) series[["A", "B", "C"]]
Boolean indexing
- 논리연산자 사용. &, |, ~, True, False
Slicing
- 범위로 원소들을 조회
- slicing한 결과의 원소를 변경하면 slicing 한 원본도 변경됨
- 원본은 변경되지 않게 하려면 slicing결과.copy()를 이용해 Series를 복사해 그것을 변경해야됨
특정 조건 원소 조회
- 특정 조건이 True인 원소들을 조회: boolean indexing
- 특정 조건이 True인 원소들의 index를 조회: numpy.where(boolean 연산)
- 특정 조건이 True인 원소와 False인 원소를 각각 다른 값으로 변경: numpy.where(boolean 연산, True변환값, False변환값)
DataFrame 개요
- 표(table-행렬) 를 다루는 Pandas의 타입.
- Database의 Table이나 Excel의 표와 동일한 역할을 한다.
- 분석할 데이터를 가지는 판다스의 가장 핵심적인 클래스이다.
- 행(row)와 열(column) 으로 구성되 있다.
- 각 행과 각 열은 식별자를 가지며 Series와 같이 두가지 종류가 있다.
- 순번
- 양수, 음수 index 두가지를 가진다.
- 컬럼도 내부적으로는 순번으로 관리되지만 우리가 조회할 때 사용할 수는 없다.
- 이름
- 명시적으로 지정한 행과 열의 이름을 말한다.
- 행의 이름은 index name 이라고 하고 열의 이름은 column name이라고 한다.
- index name과 column name은 중복될 수 있다.
- 명시적으로 지정하지 않으면 양수 순번이 index, column 이름으로 설정된다.
- 하나의 행과 하나의 열은 Series로 구성된다.
- DataFrame 객체는 직접 데이터를 넣어 생성하거나 데이터 셋을 파일(csv, 엑셀, DB 등)로 부터 읽어와 생성한다.
DataFrame에 저장된 값들을 파일에 저장
- DataFrame객체는 다양한 형식의 파일로 저장할 수 있다.
- 기본구문
DataFrame객체.to_저장형식()
CSV 파일로 저장
DataFrame객체.to_csv(파일경로,sep=',', index=True, header=True)
- 텍스트 파일로 저장
- 파일경로: 저장할 파일경로(경로/파일명)
- sep : 데이터 구분자
- index, header: 인덱스/헤더 저장 여부
- index=False : index name 저장 안함.
- Header=False : 컬럼명 저장 안함.
- encoding방식: UTF-8 로 저장된다.
- csv (comma separate value)
- 표(table)을 text파일에 작성하는 형식
- 한행에 한개의 데이터를 입력
- 속성값들을
,로 구분10,20,30 100,10,5 1,40,70
파일로 부터 데이터셋을 읽어와 생성하기
csv 파일 등 텍스트 파일로 부터 읽어와 생성
pd.read_csv(파일경로, sep=',', header, index_col, na_values)
- 파일경로
- 읽어올 파일의 경로
- sep=","
- 데이터 구분자.
- 기본값: 쉼표
- header=정수
- 열이름(컬럼이름)으로 사용할 행 지정
- 기본값: 첫번째 행
- None을 설정하면 Header는 없다는 것으로 파일의 첫번째 행부터 값으로 사용하고 컬럼명은 0부터 자동증가하는 값을 붙인다.
- index_col=정수,컬럼명
- index 명으로 사용할 열이름(문자열)이나 열의 순번(정수)을 지정.
- 생략시 0부터 자동증가하는 값을 붙인다.
- na_values
- 읽어올 데이터셋의 값 중 결측치로 처리할 문자열 지정.
주요 메소드
컬럼이름/행이름 변경 관련 메소드
DataFrame객체.rename(index=행이름변경설정, columns=열이름변경설정, inplace=False)- 개별 컬럼이름/행이름 변경 하는 메소드
- 변경한 DataFrame을 반환
- 변경설정: 딕셔너리 사용
- {'기존이름':'새이름', ..}
- inplace: 원본을 변경할지 여부(boolean)
# 특정(개별) 컬럼명들, 행이름들을 변경. - rename() ## dictionary : {원래이름:바꿀이름} new_columns = { "ID": "학생 이름", "국어": "국어1" } new_index = { "1번": "일번", "3번": "삼번" } # grade.rename(columns=new_columns) # 컬럼명 변경 # grade.rename(index=new_index) # index 명 변경 grade.rename(index=new_index, columns=new_columns, inplace=True) # 변경 대상을 바꿀때 -> inplace=True
