데이터셋(Dataset)
- Train 데이터셋 (훈련/학습 데이터셋)
- 모델을 학습시킬 때 사용할 데이터셋.
- Validation 데이터셋 (검증 데이터셋)
- 모델을 중간평가
- 모델 하이퍼파라미터 튜닝시 모델 성능 검증을 위해 사용하는 데이터셋
- 하이퍼파라미터 튜닝: 모델의 하이퍼파라미터를 변경하여 성능을 향상시키는 작업
- Test 데이터셋 (평가 데이터셋)
- 모델의 성능을 최종적으로 측정하기 위한 데이터셋
- Test 데이터셋은 마지막에 모델의 성능을 측정하는 용도로 한번만 사용되야 한다.
- 모델을 훈련하고 성능 검증했을 때 원하는 성능이 나오지 않으면 데이터나 모델 학습을 위한 설정(하이퍼파라미터)을 수정한 뒤에 다시 훈련시키고 검증을 하게 된다. 원하는 성능이 나올때 까지 설정변경->훈련->검증을 반복하게 된다.
- 위 사이클을 반복하게 되면 검증 결과를 바탕으로 설정을 변경하게 되므로 검증 할 때 사용한 데이터셋(Test set)에 모델이 맞춰서 훈련하는 것과 동일한 효과를 내게 된다.(설정을 변경하는 이유가 Test set에 대한 결과를 좋게 만들기 위해 변경하므로) 그래서 Train dataset과 Test dataset 두 개의 데이터셋만 사용하게 되면 모델의 성능을 제대로 평가할 수 없게 된다. 그래서 데이터셋을 train 세트, validation 세트, test 세트로 나눠 train set 와 validation set을 사용해 훈련과 검증을 해 모델을 최적화 한 뒤 마지막에 test set으로 최종 평가를 한다
- 모델링 과정
- Train -> Validation(검증0.79) -> Train(수정1) -> Validation(검증0.81) -> Train(수정2) -> Validation(검증0.83) -> Train(수정3) -> Validation(검증0.87) -> Test(평가0.86)
- 평가 값이 안나왔다고 수정 검증을 다시하는게 아니라 데이터를 섞어서 처음부터 다시해야한다. 또는 새로운 데이터를 가지고 해야한다.
from sklearn.datasets import load_iris X, y = load_iris(return_X_y=True) # data와 target값만 추출(X, y) X.shape, y.shape((150, 4), (150,))
# Train/Test set 분리 from sklearn.model_selection import train_test_split # X, y -> 3개 dataset으로 분리 ## train_test_split() -> 2개 dataset으로 분리 X_train, X_test, y_train, y_test = train_test_split( X, y, # input, output test_size=0.2, # testset의 비율. default:0.25 stratify=y, # 분류 데이터셋에만 적용. (y(target)이 범주형) 원본 클래스들 비율과 동일한 비율로 나누기. random_state=0 # random seed값. ) X_train.shape, X_test.shape((120, 4), (30, 4))
# Train/Validation/Test set 분리 ### Train set을 두개로 나눠서 하나는 train, 다른 하나는 validation set으로 사용. X_train, X_val, y_train, y_val = train_test_split( X_train, y_train, test_size=0.2, stratify=y_train, # stratify=output(y값, target, label) 지정. random_state=0) X_train.shape, X_test.shape, X_val.shape((96, 4), (30, 4), (24, 4))
모델 생성/평가
- max_depth=정수
- 하이퍼파라미터(Hyper Parameter): 모델의 성능에 영향을 주는 파라미터 값으로 개발자가 설정하는 값.
- 파라미터(Parameter): 머신러닝 모델의 파라미터 => 학습을 통해서 찾는 모델의 가중치값.
from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score # 모델 생성 max_depth = 4 # 하이퍼파라미터 - 사람이 지정하는 설정값. (모델 성능에 영향을 줌.) -> 어떻게 모델이 데이터를 학습할지 설정. tree = DecisionTreeClassifier(max_depth=max_depth, random_state=0) # 모델 학습 -trainset tree.fit(X_train, y_train) # 모델 검증 - validationset/trainset ## 1. 예측(추론) pred_train = tree.predict(X_train) pred_val = tree.predict(X_val) ## 2. 평가(검증) ==> accuracy train_acc = accuracy_score(y_train, pred_train) val_acc = accuracy_score(y_val, pred_val)# max_depth = 1 print(f"max_depth: {max_depth}") print("Train accuracy:", train_acc) print("Validation accuracy:", val_acc)max_depth: 1
Train accuracy: 0.6666666666666666
Validation accuracy: 0.6666666666666666# max_depth = 3 print(f"max_depth: {max_depth}") print("Train accuracy:", train_acc) print("Validation accuracy:", val_acc)max_depth: 3
Train accuracy: 0.9583333333333334
Validation accuracy: 0.9583333333333334
# Testset으로 최종평가 ## max_depth = 2 모델로 최종평가 model = DecisionTreeClassifier(max_depth=2, random_state=0) model.fit(X_train, y_train) pred = model.predict(X_test) test_acc = accuracy_score(y_test, pred) print("최종평가 결과:", test_acc)최종 평가결과: 0.9333333333333333
Hold out 방식의 단점
- train/validation/test 셋이 어떻게 나눠 지냐에 따라 결과가 달라진다.
- 데이터가 충분히 많을때는 변동성이 흡수되 괜찮으나 적을 경우 문제가 발생할 수 있다.
- 이상치에 대한 영향을 많이 받는다.
- 다양한 패턴을 찾을 수가 없기 때문에 새로운 데이터에 대한 예측 성능이 떨어지게 된다.
- 데이터가 충분히 많을때는 변동성이 흡수되 괜찮으나 적을 경우 문제가 발생할 수 있다.
- Hold out 방식은 (다양한 패턴을 가진) 데이터의 양이 많을 경우에 사용한다.
K-겹 교차검증 (K-Fold Cross Validation) - Data분리 방식 2
- 데이터셋을 설정한 K 개로 나눈다.
- K개 중 하나를 검증세트로 나머지를 훈련세트로 하여 모델을 학습시키고 평가한다.
- K개 모두가 한번씩 검증세트가 되도록 K번 반복하여 모델을 학습시킨 뒤 나온 평가지표들을 평균내서 모델의 성능을 평가한다.
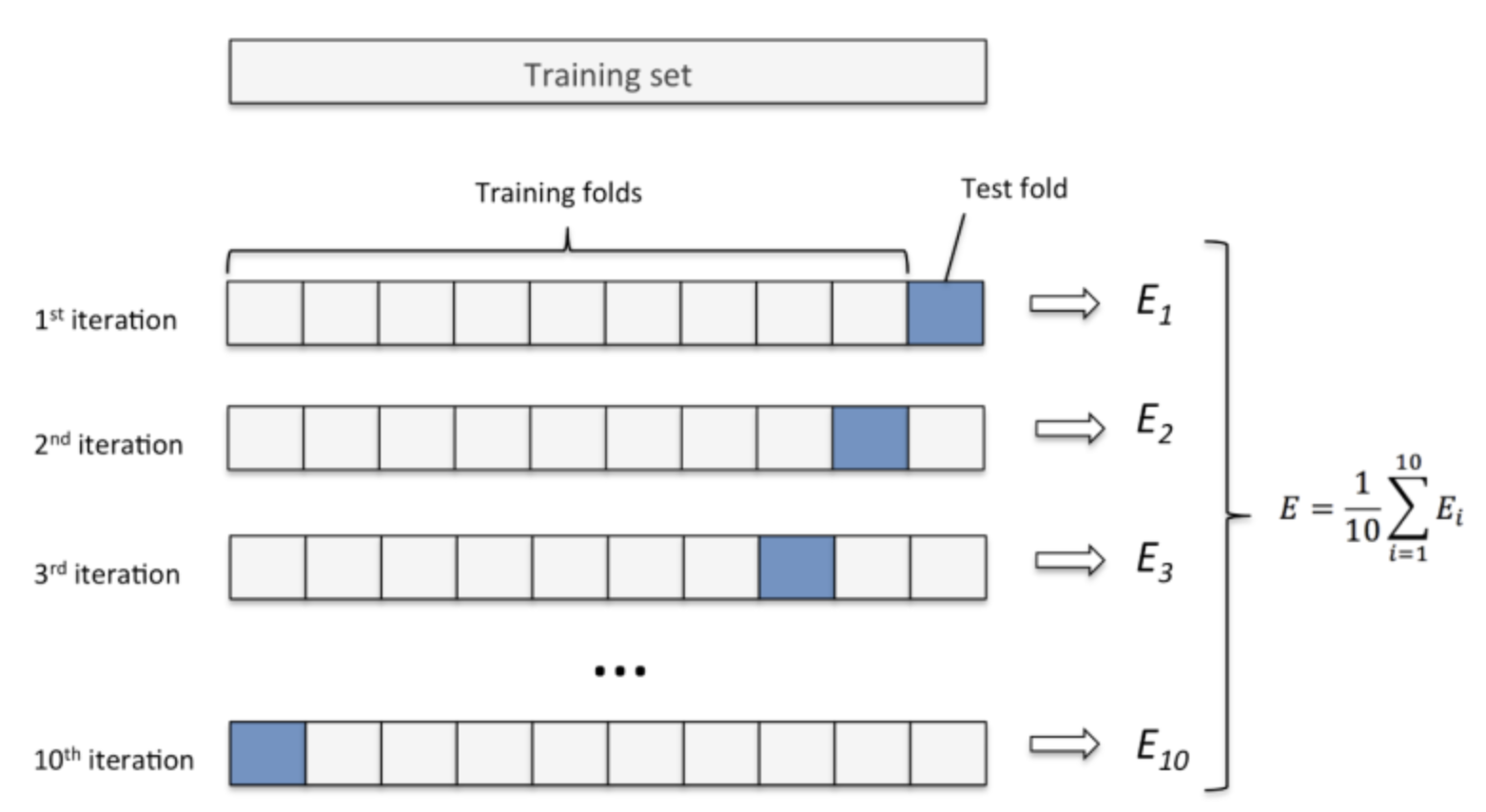
- 데이터양이 충분치 않을때 사용한다.
- 보통 Fold를 나눌때 2.5:7.5 또는 2:8 비율이 되게 하기 위해 4개 또는 5개 fold로 나눈다.
- scikit-learn 제공 클래스
- KFold
- 회귀(y값이 연속형, 수치형)문제의 Dataset을 분리할 때 사용
- StratifiedKFold
- 분류문제의 Dataset을 분리할 때 사용
- KFold
KFold
- 지정한 개수(K)만큼 분할한다.
- Raw dataset의 순서를 유지하면서 지정한 개수로 분할한다.
- 회귀 문제일때 사용한다.
- KFold(n_splits=K)
- 몇개의 Fold로 나눌지 지정
- KFold객체.split(데이터셋)
- 데이터셋을 지정한 K개 나눴을때 train/test set에 포함될 데이터의 index들을 반환하는 generator 생성
- Generator란
- 연속된 값을 제공(생성)하는 객체. 연속된 값을 한번에 메모리에 저장하지 않고 필요시마다 순서대로 하나씩 제공한다.
- 함수형식으로 구현하며 return 대신 yield를 사용한다.
Boston Housing Dataset(미국 보스톤의 구역별 집값 데이터셋 이용)
import pandas as pd import numpy as np df = pd.read_csv("data/boston_housing.csv") print(df.shape) df.head()(506, 14)
# X, y 를 분리 y = df['MEDV'].values X = df.drop(columns="MEDV").values ## DataFrame/Series.values -> ndarray 변환X.shape(), y.shape()((506, 13), (506,))
# KFold - 회귀용. K개의 fold로 나누는데 순서대로 나눈다. from sklearn.model_selection import KFold # 객체 생성 - k를 지정 kfold = KFold(n_splits=5) # K=5 - 8 : 2 , K=4 - 7.5 : 2.5 # X(input)을 넣어서 나누기 # K개 fold로 나눴을 때 train 데이터와 test 데이터의 index를 반환하는 generator를 반환 gen = kfold.split(X) # generator제공 값을 받기 -> for in 문 사용. next(generator) - 한개씩 반환받기.next(gen)
from sklearn.model_selection import KFold from sklearn.tree import DecisionTreeRegressor # DecisionTree 회귀 모델 from sklearn.metrics import mean_squared_error # 오차제곱평균.(회귀 지표중 하나) import numpy as np # dataset: X, y mse_list = [] kfold = KFold(n_splits=5) gen = kfold.next(X) for train_idx, test_idx in gen : X_train, y_train = X[train_idx], y[train_idx] X_test, y_test = X[test_idx], y[test_idx] # 모델생성 model = DecisionTreeRegressor(max_depth=2, random_state=0) # 학습 model.fit(X_train, y_train) # 검증 pred = model.predict(X_test) mse = mean_squared_error(y_test, pred) mse_list.append(mse)mse_list[19.362900914277557,
25.77734700471067,
58.61675649857523,
63.188138857997195,
41.21802825033429]
StratifiedKFold
- 분류문제일 때 사용한다.
- 전체 데이터셋의 class별 개수 비율과 동일한 비율로 fold들이 나뉘도록 한다.
- StratifiedKFold(n_splits=K)
- 몇개의 Fold로 나눌지 지정
- StratifiedKFold객체.split(X, y)
- 데이터셋을 지정한 K개 나눴을때 train/test set에 포함될 데이터의 index들을 반환하는 generator 생성
- input(X)와 output(y) dataset을 전달한다.
from sklearn.datasets import load_iris from sklearn.model_selection import StratifiedKFold from sklearn.tree import DecisionTreeClassified from sklearn.metrics import accuracy_score X, y = load_iris(return_X_y=True)# k를 지정해서 객체생성 s_kfold = StratifiedKFold(n_splits=4) # 나누기 s_gen = s_kfold.splits(X, y) # input, output data 모두 제공 # next(): 제네레이터를 호출할 때 사용하는 함수. 다음 폴드의 train_idx, valid_idx를 가져와서 가져온 인덱스를 사용하여 데이터를 나눔. train_idx, valid_idx = next(s_gen) # fold별 검증 결과를 저장할 리스트 val_result = [] for train_idx, valid_idx in s_gen : # data 추출 X_train, y_train = X[train_idx], y[train_idx] X_test, y_test = X[test_idx], y[test_idx] # 모델링 ## 모델 생성 model = DecisionTreeClassifier(max_depth=4, random_state=0) # 학습 model.fit(X_train, y_train) ## 검증 pred = model.predict(X_test) val_result.append(accuracy_score(y_test, pred))# 가장 validation 결과가 좋은 하이퍼 파라미터로 모델을 만들어서 다시 학습. final_model = DecisionTreeClassifier(max_depth=3, random_state=0) final_modle.fit(X, y)
cross_val_score( )
- 교차검증을 처리하는 함수.
- 데이터셋을 K개로 나누고 K번 반복하면서 평가하는 작업을 처리해 주는 함수
- 평가 지표를 하나만 사용할 수있다.
- 주요매개변수
- estimator: 모델객체
- X: feature
- y: label
- scoring: 평가지. 문자열, 함수
- cv: 나눌 개수 (K)
- 정수: 개수
- KFold 타입 객체
- 반환값: array - 각 반복마다의 평가점수
평가지표: https://scikit-learn.org/stable/modules/model_evaluation.html#scoring-parameter
## Boston Dataset import pandas as pd df = pd.read_csv('data/boston_hosing.csv') y = df['MEDV'].values X = df.drop(columns="MEDV").values X.shape, y.shape## train/test set 분리 (최종 평가를 위해서) from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)## cross validation(교차검증) - cross_val_score() 이용 from sklearn.model_selection import cross_val_score() from sklearn.tree import DecisionTreeRegressor model = DecisionTreeRegressor(max_depth=2, random_state=0) val_results = cross_val_score( estimator=model, # 교차검증할 모델 X=X_train, # X-input, features y=y_train, # y-output, target, label scoring="neg_mean_squared_error", # 평가지표함수-문자열, 함수객체 cv=4, # fold 수 ) print(val_results) print(-val_results)[-25.325642 -25.07376354 -42.7879561 -42.4207859 ][25.325642 25.07376354 42.7879561 42.4207859 ]
### 모델링 - 하이퍼파라미터 튜닝을 통해서 가장 성능 좋은 모델을 찾기. ## 하이퍼 파라미터: max_depth max_depth_list = [1, 2, 3, 4, 5] # max_depth별 모델의 검증 결과를 저장할 딕셔너리. key: max_depth, scores, mean_score results = {"max_depth":[], "scores":[], "mean_score":[]} for max_depth in max_depth_list : model = DecisionTreeRegressor(max_depth=max_depth, random_state=0) # 교차검증을 이용해 성능 평가 scores = cross_val_score(estimator=model, X=X_train, y=y_train, scoring="neg_mean_squared_error", cv=4) # 결과 dicitionary에 저장 results['max_depth'].append(max_depth) results['scores'].append(scores) results['mean_score'].append(np.mean(scores))results{'max_depth': [1, 2, 3, 4, 5],
'scores': [array([-45.89379405, -40.67507482, -71.05002262, -55.33355572]),
array([-25.325642 , -25.07376354, -42.7879561 , -42.4207859 ]),
array([-15.89637347, -24.77699693, -49.78552275, -25.01324593]),
array([-12.560709 , -16.50424255, -49.41891582, -20.55564482]),
array([-11.13574744, -18.13445467, -52.99608118, -14.40992532])],
'mean_score': [-53.23811180112813,
-33.90203688337762,
-28.868034772038833,
-24.759878046646527,
-24.169052153115132]}results['mean_score'][-53.23811180112813,
-33.90203688337762,
-28.868034772038833,
-24.759878046646527,
-24.169052153115132]# mse 결과에 -를 붙이는 이유 ## scikit-learn은 평가 결과값이 클수록 성능이 더 좋은 모델이라고 처리한다. ## 그런데 MSE 의 경우는 낮을 수록 더 좋은 모델이다. ## 그래서 음수를 붙어서 클수록 좋은 성능이 되도록 하는 scikit-learn 방식에 맞춘다. # sorted(results["mean_score"], reverse=True)[0]####### max_depth가 5일 때 검증결과가 가장 좋음. ### 최종 모델을 max_depth=5 해서 만들고 학습. best_model = DecisionTreeRegressor(max_depth=max_depth, random_state=0) best_model.fit(X_train, y_train)## test set으로 최종 평가 from sklearn.metrics import mean_squared_error pred_test = best_model.predict(X_test) mean_squared_error(y_test, pred_test)32.0407432413041
cross_validate()
- 교차검증을 처리하는 함수.
- 데이터셋을 K개로 나누고 K번 반복하면서 평가하는 작업을 처리해 주는 함수
- 평가 지표를 여러개 사용할 수있다.
- cross_val_score()와 다른 점은 평가 지표를 여러개 사용할 수 있다는 것. 나머지는 동일
- 주요매개변수
- estimator: 모델객체
- X: feature
- y: label
- scoring: 평가지표. 문자열, 함수, 리스트(여러개일 때는 리스트로 묶어준다.)
- cv: 나눌 개수 (K)
- 정수: 개수
- KFold 타입 객체
- 반환값: dictionary
## 회귀 평가지표 - mse, r-square from sklearn.model_selection import cross_validate, cross_val_score, KFold, StratifiedKFold, train_test_split model2 = DecisionTreeRegressor(max_depth=5) result_dict = cross_validate( estimator=model2, # 모델지정 X=X_train, y=y_train, # input/output dataset 지정 scoring=["neg_mean_squared_error", "r2", "neg_mean_absolute_error"], cv=4 )result_dict.keys() # 'fit_time' : 학습할때 걸린 시간 #'score_time': 검증할 때 걸린 시간 # 'test_neg_mean_squared_error', 'test_r2' : 검증 결과dict_keys(['fit_time', 'score_time', 'test_neg_mean_squared_error', 'test_r2', 'test_neg_mean_absolute_error'])
result_dict{'fit_time': array([0.00296092, 0.00248003, 0.00167894, 0.00161195]),
'score_time': array([0.00116014, 0.00075698, 0.00066113, 0.0005331 ]),
'test_neg_mean_squared_error': array([-11.17146312, -17.23712794, -55.94892177, -15.48784611]),
'test_r2': array([0.86707836, 0.73043523, 0.36438976, 0.85004633]),
'test_neg_mean_absolute_error': array([-2.61823906, -2.96319701, -3.96487468, -2.70686402])}
