꽃받침(Sepal)과 꽃잎(Petal)의 길이 너비로 세개의 품종을 분류하는 데이터셋
데이터셋 확인하기
scikit-learn 내장 데이터셋 가져오기
- scikit-learn은 머신러닝 모델을 테스트 하기위한 데이터셋을 제공한다.
- 이런 데이터셋을 Toy dataset이라고 한다.
- 패키지 : sklearn.datasets
- 함수 : load_xxxx()
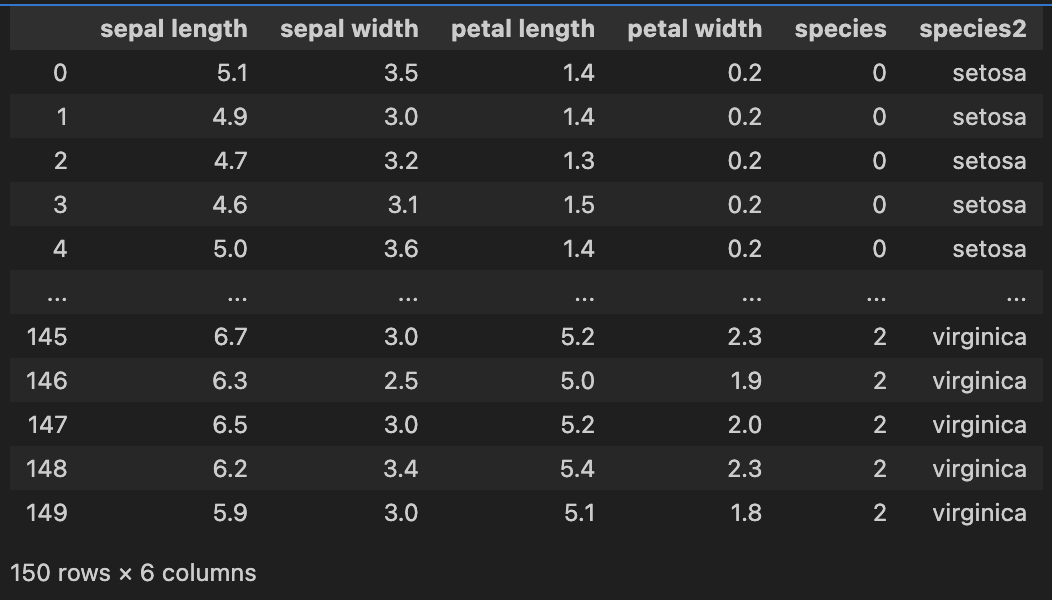
from sklearn.datasets import load_iris iris = load_iris()# input data X = iris["data"] X2 = iris.data # output data y = iris['target'] y2 = iris.targetprint("각 feature(4개)가 어떤값인지 확인") iris['feature_names']print("각 feature(4개)가 어떤값인지 확인")
iris['feature_names']['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']# output data (target, label) import numpy as np print("Shape:", y.shape) # (150: 데이터개수,) print(y[:5]) print("y의 class-범주값 조회:", np.unique(y))Shape: (150,)
[0 0 0 0 0]
y의 class-범주값 조회: [0 1 2]### y의 범주값의 이름(단어어 iris.target_namesarray(['setosa', 'versicolor', 'virginica'], dtype='<U10')
데이터 프레임으로 만들기
import pandas as pd X = iris.data y = iris.target columns = [v.replace(" (cm)", "") for v in iris.feature_names] target_names = iris.target_namesimport pandas as pd X = iris.data y = iris.target columns = [v.replace(" (cm)", "") for v in iris.feature_names] target_names = iris.target_names
머신러닝을 이용한 예측
- 머신러닝으로 하려는 것은 컴퓨터가 데이터를 학습하여 규칙을 자동으로 만들도록 하는 것
- 이를 위해 DecisionTree(결정트리)를 이용해 머신러닝 구현
- 1. import 모델
- 2. 모델 생성
- 3. 모델 학습시키기
- 4. 예측
머신러닝 프로세스

# Train/Test data set으로 전체 dataset을 나누기. from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split( X, # 나눌 입력데이터(Features) y, # 나눌 출력데이터(Target) test_size=0.2, # 나눌 비율. test_size의 전체 대비 비율 지정.(정수:개수). train:test = 0.8:0.2 stratify=y, # 분류문제 데이터셋일 때 설정. class 별로 동일한 비율이 되도록 나눈다. shuffle=True, # 나누기 전에 데이터를 섞어준다. (default: True) random_state=0 # random seed 값 설정. )X.shape(), y.shape()((150, 4), (150,))
X_train.shape, X_test.shape, y_train.shape, y_test.shape((120, 4), (30, 4), (120,), (30,))
# 모델생성 tree2 = DecisionTreeClassifier() # 모델학습 tree2.fit(X_train, y_train)# 평가 from sklearn.metrics import accuarcy_score pred = tree2.predict(X_test) score = accuarcy_score(y_test, pred) print("정확도:", score)정확도: 0.9666666666666667
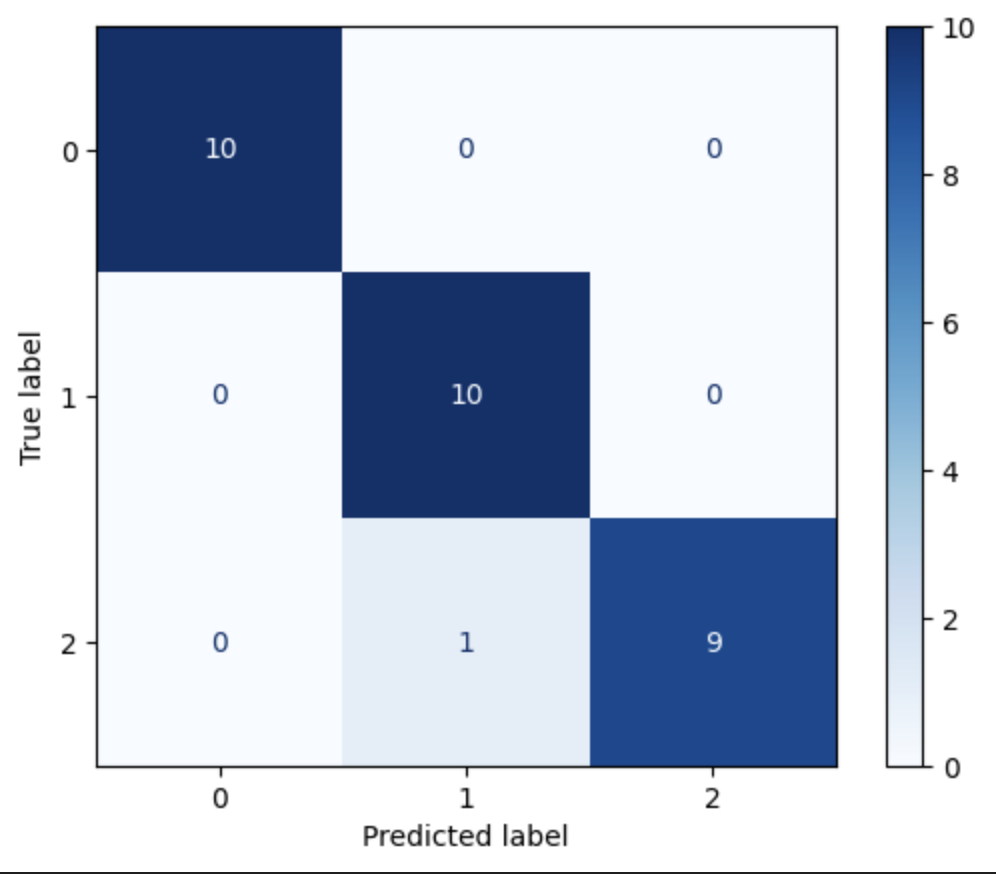
- 혼동행렬 (Confusion Matrix) 을 통해 확인
- 모델이 예측한 결과와 실제 정답간의 개수를 표로 제공
- 분류의 평가 지표로 사용된다.
- sklearn.metrics 모듈의 confusion_matrix() 함수 이용
- 결과 ndarray 구조
- axis=0의 index: 정답(실제)의 class
- axis=1의 index: 예측결과의 class
- value: 개수(각 class별 정답/예측한 개수)
from sklearn.metrics import confusion_matrix c_matrix = confusion_matrix(y_test, pred)c_matrixarray([[10, 0, 0],
[ 0, 10, 0],
[ 0, 1, 9]], dtype=int64)
from sklearn.metrics import ConfusionMatrixDisplay disp = ConfusionMatrixDisplay(c_matrix) disp.plot(cmap="Blues")

공부 & 프로젝트 & 개발 블로그