UCI SECOM 데이터셋 반도체 양/불 예측
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import tensorflow as tf
from sklearn.metrics import confusion_matrix
# csv 파일 읽어오기
data = pd.read_csv('/content/drive/MyDrive/data/uci-secom.csv')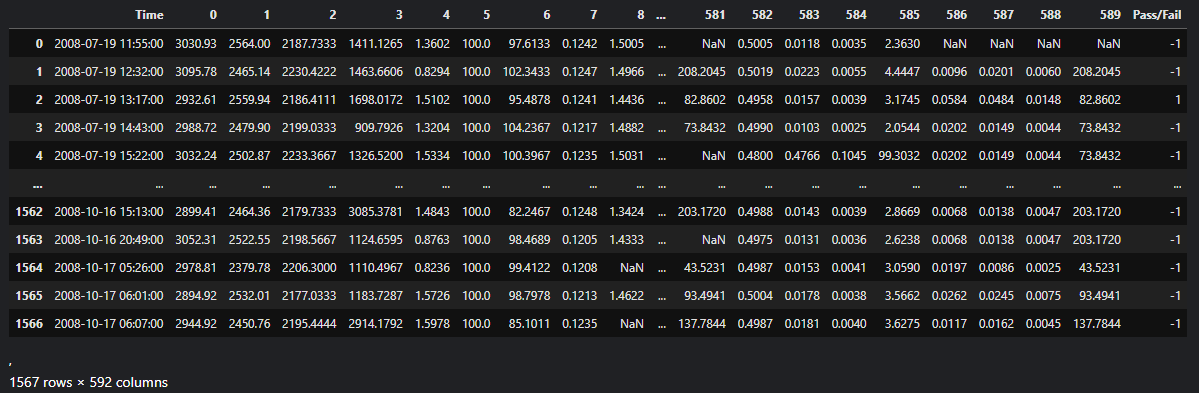
1567 * 592 공정 데이터와 양/불 라벨
Colinearity Removal
상관계수가 높은 feature들을 제거하여 과적합 방지
def remove_collinear_features(x, threshold):
corr_matrix = x.corr()
iters = range(len(corr_matrix.columns) - 1)
drop_cols = []
for i in iters:
for j in range(i+1):
item = corr_matrix.iloc[j:(j+1), (i+1):(i+2)]
col = item.columns
row = item.index
# 절대값을 씌우는 이유는
# corr 절대값이 높은거를 제거하면 되기 때문에
val = abs(item.values)
if val >= threshold:
print(col.values[0], '|', row.values[0], '|', round(val[0][0], 2))
drop_cols.append(col.values[0])
drops = set(drop_cols)
x = x.drop(columns=drops)
return xPreprocessing and spliting data
def data_preprocess(data, th = 0.70):
# 결측값 모두 0으로 바꾸기
data = data.replace(np.NaN, 0)
# correlation이 threshold 이상인 feature 제거
data = remove_collinear_features(data, th)
# time column 제거하기
data = data.drop(columns = ['Time'], axis = 1)
# single value columns : 한가지 값으로 구성된 index row(정합성 없는 데이터)
single_value_columns = [
'13', '42', '52', '97', '141', '149', '178', '179', '186', '189', '190',
'191', '192', '193', '194', '226', '229', '230', '231', '232', '233', '234', '235', '236',
'237', '240', '241', '242', '243', '256', '257', '258', '259', '260', '261', '262', '263',
'264', '265', '266', '276', '284', '313', '314', '315', '322', '325', '326', '327', '328',
'329', '330', '364', '369', '370', '371', '372', '373', '374', '375', '378', '379', '380',
'381', '394', '395', '396', '397', '398', '399', '400', '401', '402', '403', '404', '414',
'422', '449', '450', '451', '458', '461', '462', '463', '464', '465', '466', '481', '498',
'501', '502', '503', '504', '505', '506', '507', '508', '509', '512', '513', '514', '515',
'528', '529', '530', '531', '532', '533', '534', '535', '536', '537', '538'
]
data = data.drop(single_value_columns, axis = 1)
return data
def split_x_y(data):
x = data.iloc[:, :306]
y = data['Pass/Fail']
return x, y
def train_val_test_split(x, y, random_state = 42):
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2,
random_state = random_state)
x_val, x_test, y_val, y_test = train_test_split(x_test, y_test, test_size = 0.5,
random_state = random_state)
print('x_train shape :', x_train.shape)
print('y_train shape :', y_train.shape)
print('x_test shape :', x_test.shape)
print('y_test shape :', y_test.shape)
print('x_val shape :', x_val.shape)
print('y_val shape :', y_val.shape)
return x_train, x_val, x_test, y_train, y_val, y_test
def standardization(x_train, x_val, x_test):
sc = StandardScaler()
sc.fit(x_train)
x_train = sc.transform(x_train)
x_val = sc.transform(x_val)
x_test = sc.transform(x_test)
return x_train, x_val, x_test
def y_change(y):
y_np = np.array(y)
y_np = np.where(y_np == -1, 0, 1)
return y_np
def cal_metric(x_test, model):
y_pred = np.argmax(model.predict(x_test), axis = 1)
cm = confusion_matrix(y_test, y_pred)
print(cm)
tp = cm[0,0]
fn = cm[0,1]
fp = cm[1,0]
tn = cm[1,1]
precision = tp / (tp + fp)
recall = tp / (tp + fn)
f1 = 2*precision*recall / (precision + recall)
acc = (tp+tn) / (tp+fn+fp+tn)
print('precision : ', precision)
print('recall : ', recall)
print('f1 : ', f1)
print('acc : ', acc)
return cm, precision, recall, f1, accdata_pre = data_preprocess(data)
x, y = split_x_y(data_pre)
x_train, x_val, x_test, y_train, y_val, y_test = train_val_test_split(x, y)
x_train, x_val, x_test = standardization(x_train, x_val, x_test)
y_train, y_val, y_test = y_change(y_train), y_change(y_val), y_change(y_test)Model Training
model = tf.keras.Sequential([
tf.keras.layers.Dense(32, activation = 'elu',
input_shape = (194,)),
tf.keras.layers.Dense(16, activation = 'elu'),
tf.keras.layers.Dense(8, activation = 'elu'),
tf.keras.layers.Dense(4, activation = 'elu'),
tf.keras.layers.Dense(2, activation = 'softmax'),
])
model.compile(optimizer = 'adam', loss = 'sparse_categorical_crossentropy')history = model.fit(x_train, y_train,
validation_data = (x_val, y_val),
epochs = 100)
Epoch 1/100
40/40 [==============================] - 1s 7ms/step - loss: 0.6910 - val_loss: 0.5348
Epoch 2/100
40/40 [==============================] - 0s 3ms/step - loss: 0.3953 - val_loss: 0.2742
Epoch 3/100
40/40 [==============================] - 0s 3ms/step - loss: 0.1743 - val_loss: 0.1016
Epoch 4/100
40/40 [==============================] - 0s 3ms/step - loss: 0.0606 - val_loss: 0.0394
Epoch 5/100
40/40 [==============================] - 0s 3ms/step - loss: 0.0233 - val_loss: 0.0180
Epoch 6/100
40/40 [==============================] - 0s 3ms/step - loss: 0.0119 - val_loss: 0.0108
Epoch 7/100
40/40 [==============================] - 0s 3ms/step - loss: 0.0072 - val_loss: 0.0071
Epoch 8/100
40/40 [==============================] - 0s 3ms/step - loss: 0.0048 - val_loss: 0.0050
Epoch 9/100
40/40 [==============================] - 0s 4ms/step - loss: 0.0034 - val_loss: 0.0037
Epoch 10/100
40/40 [==============================] - 0s 3ms/step - loss: 0.0025 - val_loss: 0.0030
Epoch 11/100
40/40 [==============================] - 0s 3ms/step - loss: 0.0020 - val_loss: 0.0023
Epoch 12/100
40/40 [==============================] - 0s 3ms/step - loss: 0.0016 - val_loss: 0.0019
Epoch 13/100
40/40 [==============================] - 0s 3ms/step - loss: 0.0013 - val_loss: 0.0016
Epoch 14/100
40/40 [==============================] - 0s 3ms/step - loss: 0.0011 - val_loss: 0.0014
Epoch 15/100
40/40 [==============================] - 0s 3ms/step - loss: 9.0052e-04 - val_loss: 0.0012
Epoch 16/100
40/40 [==============================] - 0s 3ms/step - loss: 7.7080e-04 - val_loss: 0.0010
Epoch 17/100
40/40 [==============================] - 0s 3ms/step - loss: 6.6596e-04 - val_loss: 9.0644e-04
Epoch 18/100
40/40 [==============================] - 0s 3ms/step - loss: 5.8166e-04 - val_loss: 8.0559e-04
Epoch 19/100
40/40 [==============================] - 0s 3ms/step - loss: 5.1117e-04 - val_loss: 7.1926e-04
Epoch 20/100
40/40 [==============================] - 0s 3ms/step - loss: 4.5259e-04 - val_loss: 6.4941e-04
Epoch 21/100
40/40 [==============================] - 0s 3ms/step - loss: 4.0332e-04 - val_loss: 5.8738e-04
Epoch 22/100
40/40 [==============================] - 0s 3ms/step - loss: 3.6201e-04 - val_loss: 5.3342e-04
Epoch 23/100
40/40 [==============================] - 0s 3ms/step - loss: 3.2702e-04 - val_loss: 4.8694e-04
Epoch 24/100
40/40 [==============================] - 0s 3ms/step - loss: 2.9607e-04 - val_loss: 4.4644e-04
Epoch 25/100
40/40 [==============================] - 0s 3ms/step - loss: 2.6936e-04 - val_loss: 4.1285e-04
Epoch 26/100
40/40 [==============================] - 0s 3ms/step - loss: 2.4583e-04 - val_loss: 3.8190e-04
Epoch 27/100
40/40 [==============================] - 0s 3ms/step - loss: 2.2549e-04 - val_loss: 3.5411e-04
Epoch 28/100
40/40 [==============================] - 0s 3ms/step - loss: 2.0717e-04 - val_loss: 3.2888e-04
Epoch 29/100
40/40 [==============================] - 0s 3ms/step - loss: 1.9080e-04 - val_loss: 3.0687e-04
Epoch 30/100
40/40 [==============================] - 0s 3ms/step - loss: 1.7645e-04 - val_loss: 2.8686e-04
Epoch 31/100
40/40 [==============================] - 0s 3ms/step - loss: 1.6355e-04 - val_loss: 2.6849e-04
Epoch 32/100
40/40 [==============================] - 0s 3ms/step - loss: 1.5222e-04 - val_loss: 2.5245e-04
Epoch 33/100
40/40 [==============================] - 0s 3ms/step - loss: 1.4176e-04 - val_loss: 2.3701e-04
Epoch 34/100
40/40 [==============================] - 0s 3ms/step - loss: 1.3223e-04 - val_loss: 2.2391e-04
Epoch 35/100
40/40 [==============================] - 0s 2ms/step - loss: 1.2371e-04 - val_loss: 2.1115e-04
Epoch 36/100
40/40 [==============================] - 0s 3ms/step - loss: 1.1584e-04 - val_loss: 1.9947e-04
Epoch 37/100
40/40 [==============================] - 0s 3ms/step - loss: 1.0868e-04 - val_loss: 1.8877e-04
Epoch 38/100
40/40 [==============================] - 0s 3ms/step - loss: 1.0212e-04 - val_loss: 1.7868e-04
Epoch 39/100
40/40 [==============================] - 0s 3ms/step - loss: 9.5822e-05 - val_loss: 1.6915e-04
Epoch 40/100
40/40 [==============================] - 0s 2ms/step - loss: 9.0310e-05 - val_loss: 1.6053e-04
Epoch 41/100
40/40 [==============================] - 0s 3ms/step - loss: 8.5121e-05 - val_loss: 1.5296e-04
Epoch 42/100
40/40 [==============================] - 0s 3ms/step - loss: 8.0457e-05 - val_loss: 1.4585e-04
Epoch 43/100
40/40 [==============================] - 0s 2ms/step - loss: 7.6151e-05 - val_loss: 1.3880e-04
Epoch 44/100
40/40 [==============================] - 0s 3ms/step - loss: 7.2066e-05 - val_loss: 1.3265e-04
Epoch 45/100
40/40 [==============================] - 0s 3ms/step - loss: 6.8286e-05 - val_loss: 1.2683e-04
Epoch 46/100
40/40 [==============================] - 0s 3ms/step - loss: 6.4747e-05 - val_loss: 1.2130e-04
Epoch 47/100
40/40 [==============================] - 0s 3ms/step - loss: 6.1486e-05 - val_loss: 1.1619e-04
Epoch 48/100
40/40 [==============================] - 0s 2ms/step - loss: 5.8486e-05 - val_loss: 1.1126e-04
Epoch 49/100
40/40 [==============================] - 0s 3ms/step - loss: 5.5665e-05 - val_loss: 1.0677e-04
Epoch 50/100
40/40 [==============================] - 0s 3ms/step - loss: 5.3016e-05 - val_loss: 1.0232e-04
Epoch 51/100
40/40 [==============================] - 0s 3ms/step - loss: 5.0544e-05 - val_loss: 9.8180e-05
Epoch 52/100
40/40 [==============================] - 0s 3ms/step - loss: 4.8187e-05 - val_loss: 9.4617e-05
Epoch 53/100
40/40 [==============================] - 0s 3ms/step - loss: 4.6015e-05 - val_loss: 9.0769e-05
Epoch 54/100
40/40 [==============================] - 0s 3ms/step - loss: 4.3958e-05 - val_loss: 8.7460e-05
Epoch 55/100
40/40 [==============================] - 0s 3ms/step - loss: 4.2015e-05 - val_loss: 8.4257e-05
Epoch 56/100
40/40 [==============================] - 0s 3ms/step - loss: 4.0169e-05 - val_loss: 8.1055e-05
Epoch 57/100
40/40 [==============================] - 0s 3ms/step - loss: 3.8458e-05 - val_loss: 7.8214e-05
Epoch 58/100
40/40 [==============================] - 0s 3ms/step - loss: 3.6821e-05 - val_loss: 7.5422e-05
Epoch 59/100
40/40 [==============================] - 0s 3ms/step - loss: 3.5285e-05 - val_loss: 7.2857e-05
Epoch 60/100
40/40 [==============================] - 0s 3ms/step - loss: 3.3845e-05 - val_loss: 7.0336e-05
Epoch 61/100
40/40 [==============================] - 0s 3ms/step - loss: 3.2463e-05 - val_loss: 6.7829e-05
Epoch 62/100
40/40 [==============================] - 0s 3ms/step - loss: 3.1151e-05 - val_loss: 6.5504e-05
Epoch 63/100
40/40 [==============================] - 0s 2ms/step - loss: 2.9924e-05 - val_loss: 6.3517e-05
Epoch 64/100
40/40 [==============================] - 0s 3ms/step - loss: 2.8765e-05 - val_loss: 6.1475e-05
Epoch 65/100
40/40 [==============================] - 0s 3ms/step - loss: 2.7640e-05 - val_loss: 5.9419e-05
Epoch 66/100
40/40 [==============================] - 0s 3ms/step - loss: 2.6579e-05 - val_loss: 5.7525e-05
Epoch 67/100
40/40 [==============================] - 0s 3ms/step - loss: 2.5584e-05 - val_loss: 5.5709e-05
Epoch 68/100
40/40 [==============================] - 0s 3ms/step - loss: 2.4613e-05 - val_loss: 5.3930e-05
Epoch 69/100
40/40 [==============================] - 0s 3ms/step - loss: 2.3707e-05 - val_loss: 5.2189e-05
Epoch 70/100
40/40 [==============================] - 0s 3ms/step - loss: 2.2833e-05 - val_loss: 5.0672e-05
Epoch 71/100
40/40 [==============================] - 0s 2ms/step - loss: 2.2004e-05 - val_loss: 4.9135e-05
Epoch 72/100
40/40 [==============================] - 0s 3ms/step - loss: 2.1209e-05 - val_loss: 4.7582e-05
Epoch 73/100
40/40 [==============================] - 0s 3ms/step - loss: 2.0439e-05 - val_loss: 4.6201e-05
Epoch 74/100
40/40 [==============================] - 0s 2ms/step - loss: 1.9710e-05 - val_loss: 4.4798e-05
Epoch 75/100
40/40 [==============================] - 0s 3ms/step - loss: 1.9017e-05 - val_loss: 4.3539e-05
Epoch 76/100
40/40 [==============================] - 0s 3ms/step - loss: 1.8355e-05 - val_loss: 4.2272e-05
Epoch 77/100
40/40 [==============================] - 0s 3ms/step - loss: 1.7726e-05 - val_loss: 4.1108e-05
Epoch 78/100
40/40 [==============================] - 0s 3ms/step - loss: 1.7102e-05 - val_loss: 3.9814e-05
Epoch 79/100
40/40 [==============================] - 0s 3ms/step - loss: 1.6518e-05 - val_loss: 3.8695e-05
Epoch 80/100
40/40 [==============================] - 0s 2ms/step - loss: 1.5940e-05 - val_loss: 3.7577e-05
Epoch 81/100
40/40 [==============================] - 0s 3ms/step - loss: 1.5397e-05 - val_loss: 3.6559e-05
Epoch 82/100
40/40 [==============================] - 0s 3ms/step - loss: 1.4873e-05 - val_loss: 3.5606e-05
Epoch 83/100
40/40 [==============================] - 0s 3ms/step - loss: 1.4383e-05 - val_loss: 3.4558e-05
Epoch 84/100
40/40 [==============================] - 0s 3ms/step - loss: 1.3916e-05 - val_loss: 3.3604e-05
Epoch 85/100
40/40 [==============================] - 0s 3ms/step - loss: 1.3460e-05 - val_loss: 3.2669e-05
Epoch 86/100
40/40 [==============================] - 0s 3ms/step - loss: 1.3013e-05 - val_loss: 3.1857e-05
Epoch 87/100
40/40 [==============================] - 0s 3ms/step - loss: 1.2596e-05 - val_loss: 3.1007e-05
Epoch 88/100
40/40 [==============================] - 0s 2ms/step - loss: 1.2200e-05 - val_loss: 3.0115e-05
Epoch 89/100
40/40 [==============================] - 0s 3ms/step - loss: 1.1807e-05 - val_loss: 2.9350e-05
Epoch 90/100
40/40 [==============================] - 0s 2ms/step - loss: 1.1440e-05 - val_loss: 2.8617e-05
Epoch 91/100
40/40 [==============================] - 0s 3ms/step - loss: 1.1083e-05 - val_loss: 2.7919e-05
Epoch 92/100
40/40 [==============================] - 0s 3ms/step - loss: 1.0741e-05 - val_loss: 2.7211e-05
Epoch 93/100
40/40 [==============================] - 0s 3ms/step - loss: 1.0411e-05 - val_loss: 2.6522e-05
Epoch 94/100
40/40 [==============================] - 0s 4ms/step - loss: 1.0091e-05 - val_loss: 2.5902e-05
Epoch 95/100
40/40 [==============================] - 0s 3ms/step - loss: 9.7864e-06 - val_loss: 2.5225e-05
Epoch 96/100
40/40 [==============================] - 0s 3ms/step - loss: 9.4818e-06 - val_loss: 2.4528e-05
Epoch 97/100
40/40 [==============================] - 0s 2ms/step - loss: 9.1961e-06 - val_loss: 2.3941e-05
Epoch 98/100
40/40 [==============================] - 0s 2ms/step - loss: 8.9172e-06 - val_loss: 2.3297e-05
Epoch 99/100
40/40 [==============================] - 0s 3ms/step - loss: 8.6489e-06 - val_loss: 2.2740e-05
Epoch 100/100
40/40 [==============================] - 0s 3ms/step - loss: 8.3913e-06 - val_loss: 2.2201e-05Performance
from sklearn.metrics import accuracy_score
from sklearn.metrics import f1_score
from sklearn.metrics import confusion_matrix
print("Accuracy: ", accuracy_score(y_test, y_pred)*100)
y_pred = np.argmax(model.predict(x_test), axis =1)
print('f1 score : ', f1_score(y_test, y_pred))
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot = True)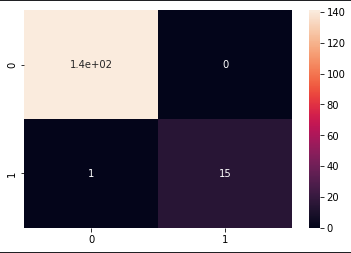

Data Science & Engineering
글 잘 봤습니다!!
성능이 굉장히 좋아서 저도 사용해보려 했는데 제 생각에 오류가 있는 것 같아 물어봅니다
def split_x_y(data):
이 부분에서 x안에 Pass_Fail column이 포함되어 있어 성능이 잘나오는가 싶어 어떻게 생각하시는지 궁금하네요
Pass/Fail부분 빼고 실험해보니 TN부분은 낮아지고 FP부분이 높아져 어떻게 생각하시는지 궁금합니다