
Data 분리
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
data = pd.read_csv('/kaggle/input/digit-recognizer/train.csv')
data = np.array(data)
m, n = data.shape
np.random.shuffle(data) # shuffle before splitting into dev and training sets
data_train = data[:m].T
Y_train = data_train[0]
X_train = data_train[1:n]
X_train = X_train / 255.
_,m_train = X_train.shape모델 파라미터
Forward propagation
Backward propagation
Parameter updates
Feed forward
- : 784 x m
- : 10 x m
- : 10 x 784 (as )
- : 10 x 1
- : 10 x m
- : 10 x 10 (as )
- : 10 x 1
Back propagation
- : 10 x m ()
- : 10 x 10
- : 10 x 1
- : 10 x m ()
- : 10 x 10
- : 10 x 1
함수정의
def init_params():
W1 = np.random.rand(10, 784) - 0.5
b1 = np.random.rand(10, 1) - 0.5
W2 = np.random.rand(10, 10) - 0.5
b2 = np.random.rand(10, 1) - 0.5
return W1, b1, W2, b2
def ReLU(Z):
return np.maximum(Z, 0)
def softmax(Z):
A = np.exp(Z) / sum(np.exp(Z))
return A
def forward_prop(W1, b1, W2, b2, X):
Z1 = W1.dot(X) + b1
A1 = ReLU(Z1)
Z2 = W2.dot(A1) + b2
A2 = softmax(Z2)
return Z1, A1, Z2, A2
def ReLU_deriv(Z):
return Z > 0
def one_hot(Y):
one_hot_Y = np.zeros((Y.size, Y.max() + 1))
one_hot_Y[np.arange(Y.size), Y] = 1
one_hot_Y = one_hot_Y.T
return one_hot_Y
def backward_prop(Z1, A1, Z2, A2, W1, W2, X, Y):
one_hot_Y = one_hot(Y)
dZ2 = A2 - one_hot_Y
dW2 = 1 / m * dZ2.dot(A1.T)
db2 = 1 / m * np.sum(dZ2)
dZ1 = W2.T.dot(dZ2) * ReLU_deriv(Z1)
dW1 = 1 / m * dZ1.dot(X.T)
db1 = 1 / m * np.sum(dZ1)
return dW1, db1, dW2, db2
def update_params(W1, b1, W2, b2, dW1, db1, dW2, db2, alpha):
W1 = W1 - alpha * dW1
b1 = b1 - alpha * db1
W2 = W2 - alpha * dW2
b2 = b2 - alpha * db2
return W1, b1, W2, b2
def get_predictions(A2):
return np.argmax(A2, 0)
def get_accuracy(predictions, Y):
print(predictions, Y)
return np.sum(predictions == Y) / Y.size
def gradient_descent(X, Y, alpha, iterations):
W1, b1, W2, b2 = init_params()
for i in range(iterations):
Z1, A1, Z2, A2 = forward_prop(W1, b1, W2, b2, X)
dW1, db1, dW2, db2 = backward_prop(Z1, A1, Z2, A2, W1, W2, X, Y)
W1, b1, W2, b2 = update_params(W1, b1, W2, b2, dW1, db1, dW2, db2, alpha)
if i % 10 == 0:
print("Iteration: ", i)
predictions = get_predictions(A2)
print(get_accuracy(predictions, Y))
return W1, b1, W2, b2학습 & 결과
W1, b1, W2, b2 = gradient_descent(X_train, Y_train, 0.10, 500)
Iteration: 0
[2 6 4 ... 0 3 0] [1 3 8 ... 3 7 4]
0.10939024390243902
Iteration: 10
[2 5 7 ... 1 3 0] [1 3 8 ... 3 7 4]
0.16495121951219513
Iteration: 20
[2 5 7 ... 3 3 0] [1 3 8 ... 3 7 4]
0.20821951219512194
Iteration: 30
[2 3 7 ... 3 3 0] [1 3 8 ... 3 7 4]
0.24424390243902439
Iteration: 40
[2 3 7 ... 1 3 0] [1 3 8 ... 3 7 4]
0.281780487804878
Iteration: 50
[2 3 7 ... 3 3 0] [1 3 8 ... 3 7 4]
0.3227317073170732
Iteration: 60
[2 3 7 ... 3 9 0] [1 3 8 ... 3 7 4]
0.3648048780487805
Iteration: 70
[2 3 7 ... 3 9 0] [1 3 8 ... 3 7 4]
0.40904878048780485
Iteration: 80
[2 3 7 ... 3 7 0] [1 3 8 ... 3 7 4]
0.450609756097561
Iteration: 90
[2 3 7 ... 3 7 0] [1 3 8 ... 3 7 4]
0.4898292682926829
Iteration: 100
[2 8 7 ... 3 7 0] [1 3 8 ... 3 7 4]
0.5265121951219512
Iteration: 110
[2 8 7 ... 3 7 0] [1 3 8 ... 3 7 4]
0.5636097560975609
Iteration: 120
[2 8 7 ... 3 7 0] [1 3 8 ... 3 7 4]
0.5929268292682927
Iteration: 130
[2 8 7 ... 3 7 0] [1 3 8 ... 3 7 4]
0.6162682926829268
Iteration: 140
[2 8 7 ... 3 7 0] [1 3 8 ... 3 7 4]
0.6360975609756098
Iteration: 150
[2 8 7 ... 3 7 0] [1 3 8 ... 3 7 4]
0.6531219512195122
Iteration: 160
[2 3 7 ... 3 7 0] [1 3 8 ... 3 7 4]
0.6678536585365854
Iteration: 170
[2 3 7 ... 3 7 4] [1 3 8 ... 3 7 4]
0.6811707317073171
Iteration: 180
[2 3 7 ... 8 7 4] [1 3 8 ... 3 7 4]
0.6940487804878048
Iteration: 190
[2 3 7 ... 8 7 4] [1 3 8 ... 3 7 4]
0.7065609756097561
Iteration: 200
[2 3 7 ... 8 7 4] [1 3 8 ... 3 7 4]
0.7169756097560975
Iteration: 210
[2 3 7 ... 8 7 4] [1 3 8 ... 3 7 4]
0.7270243902439024
Iteration: 220
[2 3 7 ... 8 7 4] [1 3 8 ... 3 7 4]
0.7370487804878049
Iteration: 230
[2 3 7 ... 8 7 4] [1 3 8 ... 3 7 4]
0.745780487804878
Iteration: 240
[2 3 7 ... 8 7 4] [1 3 8 ... 3 7 4]
0.7534634146341463
Iteration: 250
[2 3 7 ... 8 7 4] [1 3 8 ... 3 7 4]
0.7608292682926829
Iteration: 260
[2 3 7 ... 8 7 4] [1 3 8 ... 3 7 4]
0.7681951219512195
Iteration: 270
[2 3 7 ... 8 7 4] [1 3 8 ... 3 7 4]
0.7747073170731708
Iteration: 280
[2 3 7 ... 8 7 4] [1 3 8 ... 3 7 4]
0.7802926829268293
Iteration: 290
[2 3 7 ... 8 7 4] [1 3 8 ... 3 7 4]
0.7852439024390244
Iteration: 300
[2 3 7 ... 8 7 4] [1 3 8 ... 3 7 4]
0.7903170731707317
Iteration: 310
[2 3 7 ... 8 7 4] [1 3 8 ... 3 7 4]
0.795219512195122
Iteration: 320
[2 3 5 ... 8 7 4] [1 3 8 ... 3 7 4]
0.7995365853658537
Iteration: 330
[2 3 5 ... 8 7 4] [1 3 8 ... 3 7 4]
0.8032439024390244
Iteration: 340
[2 3 5 ... 8 7 4] [1 3 8 ... 3 7 4]
0.8069756097560976
Iteration: 350
[2 3 5 ... 8 7 4] [1 3 8 ... 3 7 4]
0.8109024390243903
Iteration: 360
[2 3 5 ... 8 7 4] [1 3 8 ... 3 7 4]
0.8143170731707317
Iteration: 370
[2 3 5 ... 8 7 4] [1 3 8 ... 3 7 4]
0.8172195121951219
Iteration: 380
[2 3 5 ... 8 7 4] [1 3 8 ... 3 7 4]
0.8200975609756097
Iteration: 390
[6 3 5 ... 8 7 4] [1 3 8 ... 3 7 4]
0.8228048780487804
Iteration: 400
[6 3 5 ... 8 7 4] [1 3 8 ... 3 7 4]
0.8251219512195122
Iteration: 410
[6 3 5 ... 8 7 4] [1 3 8 ... 3 7 4]
0.8273170731707317
Iteration: 420
[6 3 5 ... 8 7 4] [1 3 8 ... 3 7 4]
0.8297317073170731
Iteration: 430
[6 3 5 ... 8 7 4] [1 3 8 ... 3 7 4]
0.8323414634146341
Iteration: 440
[6 3 5 ... 8 7 4] [1 3 8 ... 3 7 4]
0.8342682926829268
Iteration: 450
[6 3 5 ... 8 7 4] [1 3 8 ... 3 7 4]
0.8360975609756097
Iteration: 460
[6 3 5 ... 8 7 4] [1 3 8 ... 3 7 4]
0.8379268292682926
Iteration: 470
[6 3 5 ... 8 7 4] [1 3 8 ... 3 7 4]
0.8395365853658536
Iteration: 480
[6 3 5 ... 8 7 4] [1 3 8 ... 3 7 4]
0.8408536585365853
Iteration: 490
[6 3 5 ... 8 7 4] [1 3 8 ... 3 7 4]
0.8427073170731707 ########################약 85%의 정확도
def make_predictions(X, W1, b1, W2, b2):
_, _, _, A2 = forward_prop(W1, b1, W2, b2, X)
predictions = get_predictions(A2)
return predictions
def test_prediction(index, W1, b1, W2, b2):
current_image = X_train[:, index, None]
prediction = make_predictions(X_train[:, index, None], W1, b1, W2, b2)
label = Y_train[index]
print("Prediction: ", prediction)
print("Label: ", label)
current_image = current_image.reshape((28, 28)) * 255
plt.gray()
plt.imshow(current_image, interpolation='nearest')
plt.show()
############################################################
test_prediction(100, W1, b1, W2, b2)
test_prediction(101, W1, b1, W2, b2)
test_prediction(102, W1, b1, W2, b2)
test_prediction(103, W1, b1, W2, b2) Prediction: [1]
Label: 1
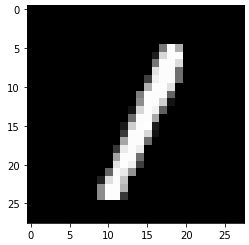
Prediction: [1]
Label: 8
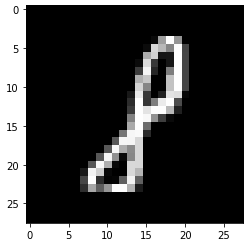
Prediction: [1]
Label: 1
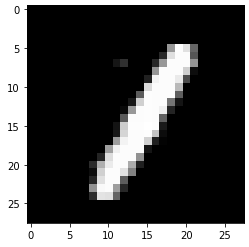
Prediction: [9]
Label: 9
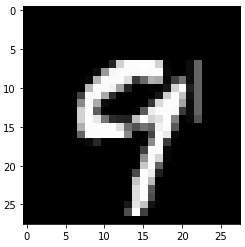

Data Science & Engineering