장점
- 메모리 집약적 작업 향상
- LoRA와 비교하여 더 높은 성능과, 새로운 지식을 효과적으로 학습 가능
- 동일한 수의 학습 가능한 파라미터 유지
- 학습 가능한 파라미터 수를 유지하면서 high-rank 업데이트 가능
단점
- 추론 시간에 대한 문제
- high-rank update와 추가 operators는 연산 속도에 영향이 있을 것으로 보이나 ablation이 존재하지 않음
- Instruction Tuning, Mathematical Reasoning에서 좋은 성능을 보이지 않고 있는데 제안한 방식에 효율성 입증이 부족함
Abstract
LoRA는 LLM을 위한 효율적인 파인튜닝 방법입니다.
본 논문에서 LoRA는 LLM의 새로운 정보를 학습하기에 부족한 능력을 가지고 있음을 확인했습니다.
정사각 행렬을 사용하여 훈련 가능한 파라미터를 유지하면서 고랭크 업데이트가 가능한 MoRA를 제안합니다.
입력 차원을 줄이면서 출력 차원은 늘리기 위해 비파라미터 연산자를 도입합니다.
LoRA처럼 배포할 수 있는 형태로 진행할 수 있습니다.
Introduction
언어 모델이 커짐에 따라 하위 작업에 모델들을 훈련시키 위한 효율적인 매개변수 미세조정(parameter-efficient fine-tuning, PEFT)가 인기를 얻고 있습니다.
전체 미세조정(Full Fine-Tuning, FFT)는 모델의 모든 매개변수를 업데이트하는 반면, PEFR는 소수의 매개변수만 업데이트합니다.
소수의 매개변수만 업데이트하는 점은 메모리 연구 사항을 크게 줄이고 모델의 저장 및 배포를 용이하게 합니다.
Low-Rank Adaptation (LoRA)와 같은 PEFT 방법은 매우 널리 알려져 있습니다.
저차원 행렬을 통해 매개변수를 업데이트하고 해당 행렬들은 원래 도델 매개변수와 통합될 수 있어 추가적인 계산 비용을 피할 수 있습니다.
본 논문에서는 동일한 설정에서 다양한 작업을 통해 LoRA의 종합적인 평가를 수행합니다.
Instruction tuning, mathematical reasoning, and continual pretraining 등이 포함됩니다.
LoRA와 유사한 방법이 instruction tuning에서 유사한 성능을 보이지만 mathematical reasoning, and continual pretraining에서는 성능이 떨어지는 것을 발견했습니다.
Instruction tuning은 형식과 상호작용하는 것을 중점으로 두고 있지만, mathematical reasoning, and continual pretraining은 사전 학습 동안 얻어지게 됩니다.
지식을 향상 시켜야하는 뒤의 2가지 방식은 LoRA를 통해 학습시키는데 어려움을 겪습니다.
LoRA의 한계는 low-rank updates metrix인 ∆W는 FFT에서 모든 업데이트 추정하는 데 어려움을 겪으며 특정 지식을 기억해야 하는 작업에서 문제가 두드러집니다.
∆W의 rank가 전체 rank보다 현저히 작기 때문에 새로운 정보를 저장하는 능력이 제한됩니다.
LoRA의 변형이 low rank의 본질적인 특성을 변경할 수 없습니다.
이를 증명하기 위해 가짜 데이터를 사용하여 기억 작업을 할 수 있는지 파악하고 LoRA의 새로운 지식을 기억하는 성능을 평가했습니다.
해당 실험을 통해 rank가 256처럼 큰 값을 가지더라도 FFR보다 현저히 떨어지는 기억능력을 가지고 있는 것을 확인했습니다.
위의 문제를 해결하기 위해 본 논문은 MoRA 방법을 제안합니다.
low-rank matrxi 대신 square-matrix를 사용하여 동일한 수의 학습 가능한 매개변수를 유지하면서 ∆W의 랭크를 최대화합니다.
hidden state 4096에서 8 rank를 사용할 때, LoRA는 A ∈ R4096×8과 B ∈ R8×4096의 두 low-rank 행렬을 사용하며, rank(∆W) ≤ 8입니다.
동일한 조건에서 MoRA는 M ∈ R256×256의 square-matrix을 사용하며, rank(∆W) ≤ 256을 따릅니다.
입력 차원을 줄이고 M의 출력 차원을 늘리기 위해 non-parameter operators을 추가했습니다.
또한, M은 ∆W로 교환될 수 있고 이는 LoRA와 마찬가지로 LLM에 통합될 수 있습니다.
본 논문은 3가지 기여를 제공합니다.
- low-rank matrix 대신 square-matrix를 사용하는 MoRA를 소개하고 동일한 수의 학습 가능한 매개변수를 유지하면서 high-rank 업데이트를 가능하게 합니다.
- 입력 차원을 주리고 square-matrix의 출력 차원을 늘리기 위해 MoRA의 4가지 non-parameter operators 설계하였고 이는 LLM의 통합될 수 있음을 보장합니다.
- 많은 평가에서 뛰어난 성능을 보여줍니다.
Related Work
LoRA
LoRA는 넓은 적용성과 높은 성능 때문에 LLM 미세조정을 위해 가장 인기 많은 PEFT 방법입니다.
FFT에서 업데이트된 가중치 ∆W를 근사하기 위해, LoRA는 두 개의 low-rank matrix를 이용하여 분해합니다.
두 matrix를 조정함으로써 LoRA는 학습 가능한 매개변수 수정할 수 있고, 미세 조정 후에도 FFT 비교하여 추론 지연 없이 행렬을 통합할 수 있습니다.
Fine-Tuning with LLMs
In-context learning이 인상적이지만, 특정 시나리오에서는 여전히 미세 조정이 필요합니다.
3가지의 시나리오가 존재합니다.
- Instruction tuning은 사용자 선호도와 맞게 수정될 수 있지만 LLM의 지식과 능력의 향상 시키는 것에는 도움이 적습니다.
- 수학 문제를 해결과 같이 복잡한 지시 사항은 instruction tuning으로 성능을 올리기에 부적합니다.
- 도메인 특화 모델을 만들기 위해서는 미세조정이 필수적입니다.
대부분의 LoRA 변형은 instruction tuning 또는 GLUE의 텍스트 분류 작업을 사용하여 성능을 검증합니다.
하지만 instruction tuning은 미세 조정에 적은 용량만 변경되어 LoRA의 변형을 잘 파악하기 어렵습니다.
더 잘 평가하기 위해 다양한 추론 작업을 사용하여 테스트를 하기 시작했습니다.
하지만 이 역시 추론을 학습하기에는 너무 작고 이는 이러한 방법의 효과를 평가하는데 어려움이 있습니다.
Analysis the Influence of Low-rank Updating
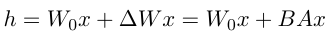
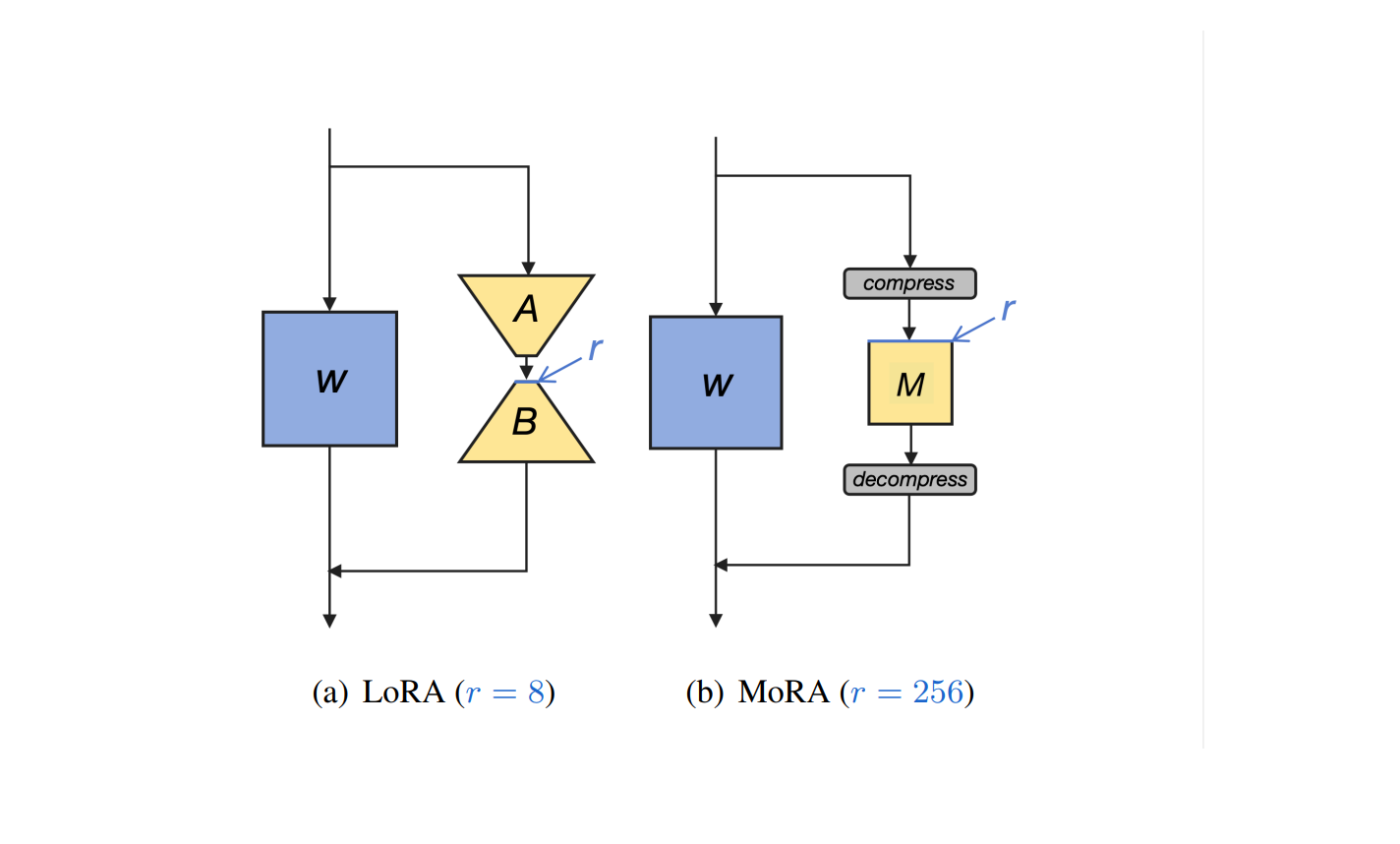
LoRA는 FFT의 전체 rank 업데이트를 추정하기 위해 low-rank 업데이트를 사용합니다.
사전 학습된 매개변수 matrix인 W0 ∈ Rd×k에 대해, LoRA는 두 개의 low-rank matrix를 사용하여 가중치 업데이트를 ∆W 계산합니다.(위의 식)
A ∈ Rr×k 및 B ∈ Rd×r은 LoRA의 low-rank matrix를 나타냅니다.
훈련이 처음 시작할 때 ∆W = 0을 보장하기 위해 LoRA는 A를 가우시안 분포로 초기화하고 B를 0으로 초기화합니다.
LoRA의 가중치 업데이트는 FFT에서의 전체 rank 업데이트에 비해 현저히 낮은 rank를 나타내며, r ≪ min(d, k)를 따릅니다.
해당 방식은 간단한 텍스트 분류나, instruction tuning과 같은 작업에는 동등한 성능을 보입니다.
하지만 복잡한 추론이나 지속적인 사전학습과 같은 작업에서는 LoRA의 성능이 떨어지는 것을 확인했습니다.
이러한 관찰을 바탕으로 low-rank 업데이트가 LLM의 원래 지식과 능력을 활용하여 작업을 해결하는 데는 쉬우나, LLM의 지식과 기초 능력을 향상시키는 작업을 처리하는 데는 어려움을 겪는다는 가설을 제시합니다
가설을 입증하기 위해 LoRA와 FFT의 차이를 조사합니다.
LLM의 사전 지식을 활용하지 않기 위해 32개의 16진수 값을 가진 UUID 쌍 10,000개를 무작위로 생성하여 사용합니다.
입력된 UUID를 기반으로 해당하는 UUID를 생성하도록 LLM에 요구합니다.
예를 들어 "205f3777-52b6-4270-9f67-c5125867d358"와 같은 UUID가 주어지면, 모델은 10,000개의 훈련 쌍을 기반으로 해당하는 UUID를 생성해야 합니다.
질문-답변 쌍 작업으로 볼 수 있고 답변의 완성하는데 필요한 지식은 전적으로 훈련 데이터셋에 포함되어 있습니다.
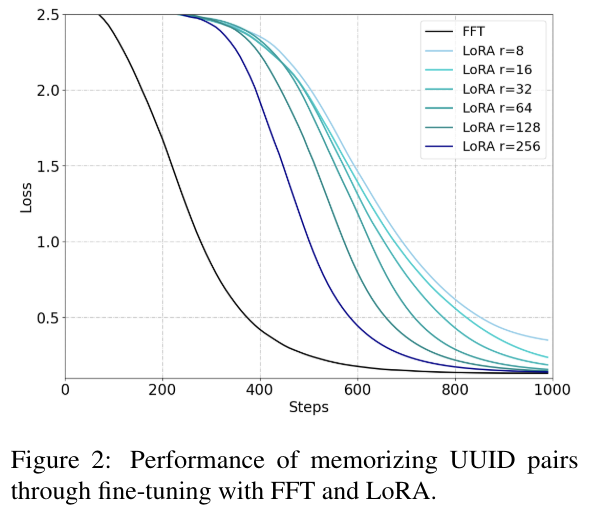
위의 이미지를 통해 low-rank 업데이트가 FFT와 비교하여 새로운 지식을 기억하는 데 어려움을 겪는 것을 관찰할 수 있습니다.
Method
위의 분석을 바탕으로 새로운 방법을 제안합니다.
최대한 많은 훈련 파라미터를 사용하여 ΔW의 high-rank를 달성하는 것이 그 방법입니다.
사전 훈련된 가중치 고려할 때, LoRA는 rank 에 대해 총 개의 훈련 가능한 파라미터를 가진 두 개의 low-rank matrix 와 를 사용합니다.
동일한 훈련 가능한 파라미터 하에서, 일 때, 인 정사각 행렬은 가장 높은 랭크를 달성할 수 있습니다.
여기서 입니다.
위의 조건을 달성하기 위해서는 입력 차원을 줄이고 의 출력 차원을 증가시켜야 합니다.
는 의 입력 차원을 에서 로 줄이는 함수이고,
는 출력 차원을 에서 로 증가시키는 함수입니다.
위의 두 함수는 non-parameterized operator여야 하며 차원에 따라 linear time에 따라 동작해야 합니다.
와 에 대응하여 을 로 변환할 수 있어야 합니다.
어떤 에 대해서도 다음이 성립해야 합니다:
(3)
여기서 입니다. 만약 방정식 (3)이 성립한다면, 은 와 를 기반으로 로 무손실 확장이 가능합니다.
와 의 설계를 위해, 가장 간단한 방법 중 하나는 차원을 잘라내고 그 후에 대응 차원에 추가하는 것입니다.
이는 아래의 식을 통해 표현될 수 있습니다.
위의 식과 대응 되는 는 아래와 같습니다.
그러나 위의 방법은 압축 중에 상당한 정보 손실을 초래하며, 해압축 시 0 벡터를 추가하여 출력의 일부만 수정합니다.
이를 개선하기 위해, 우리는 의 행과 열을 공유하여 보다 효율적인 압축과 해압축을 달성할 수 있습니다. 공식적으로, 이는 다음과 같이 표현될 수 있습니다:
(6)
(6)
여기서 와 는 에서 동일한 행과 열을 공유하는 미리 정의된 그룹을 나타냅니다.
는 번째 차원이 의 번째 그룹에 속함을 나타냅니다.
는 의 번째 차원과 관련된 역 그룹을 나타냅니다.
이에 대응하는 는 다음과 같습니다:
행과 열을 공유하는 것은 또는 과 같은 더 큰 랭크에 대해 효율적일 수 있습니다.
예를 들어, 일 때 이고, , 입니다.
이 경우, 단 4개의 행 또는 열만이 동일한 행 또는 열을 공유합니다.
반면, 과 같은 작은 랭크의 경우, 이 되며, 그룹 내 평균 16개의 행 또는 열이 에서 동일한 행 또는 열을 공유해야 합니다.
이는 방정식 (6)에서 압축 중에 상당한 정보 손실을 초래할 수 있습니다.
low-rank의 성능을 향상시키기고 입력 정보를 보존하기 위해 를 직접 압축하는 대신 재구성합니다.
이고,
입니다.
대응되는 및 는 다음과 같습니다:
는 의 행을 벡터로 연결하는 것을 의미합니다.
단순화를 위해, 우리는 위 함수에서 패딩과 잘라내기 연산자를 생략하고 인 경우에 초점을 맞춥니다.
행과 열을 공유하는 것과 비교하여, 이 방법은 를 대신 로 재구성함으로써 추가적인 계산 오버헤드를 발생시킵니다.
그러나 의 크기가 보다 훨씬 작기 때문에, 이 추가 계산은 rank 8과 같은 경우에는 매우 작습니다.
예를 들어, rank 8로 7B 모델을 미세 조정할 때, 이 방법은 이전 방법보다 1.03배 느립니다.
RoPE(Su et al., 2024)을 이용하여 에 rotation operators를 에 통합하여 이 다양한 를 표현력을 증가시킬 수 있습니다.
방정식 (8)을 다음과 같이 수정할 수 있습니다:
(8)
(8)
여기서 와 는 각각 와 회전 후의 의 대응 값을 나타냅니다.
RoPE 회전을 달성하기 위해 인 block diagonal matrix을 사용합니다.
그러나 우리의 방법은 RoPE에서 토큰 위치 대신 를 구별하기 위해 회전 정보를 사용합니다.
우리는 와 를 다음과 같이 정의할 수 있습니다:
여기서 이며, 는 회전 행렬입니다:
Experiments
다양한 방법을 통해 high-rank update를 이해하고 수행합니다.
- UUID 쌍을 암기하는 작업에서 LoRA와 우리의 방법을 평가하여 high-rank update가 암기에 미치는 이점을 보여줍니다.
- LoRA, LoRA 변형 및 FFT를 재현하여 instruction tuning, mathematical reasoning and continual pretraining 세 가지 미세 조정 작업을 수행합니다.
- 우리의 방법과 LoRA, ReLoRA를 비교하여 트랜스포머를 처음부터 훈련시키는 사전 훈련 작업을 수행합니다.
Memorizing UUID Pairs
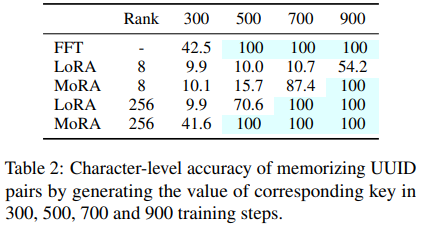
본 논문의 방법을 LoRA 및 FFT와 비교하여 UUID 쌍을 암기하는 작업을 수행했습니다.
Eq. 8의 comp 및 decomp 기능을 사용하며, M matrix의 행과 열을 공유하는 방식을 사용합니다.
두 개의 matrix A와 B 대신 하나의 matrix M을 사용함으로써, M을 0으로 직접 초기화할 수 있습니다.
미리 정의된 그룹 g와 g'에 대해서는 인접한 rˆ 행 또는 열을 함께 그룹화했습니다.
위의 talbe 2를 LoRA와 비교하여 MoRA의 기억 향상 성능이 크게 증가한 것을 확인할 수 있습니다.
Fine-tuning Tasks
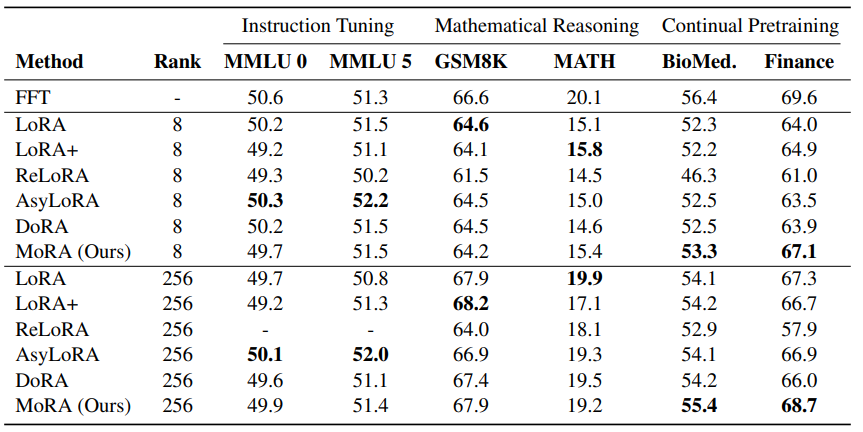
위의 표를 통해 성능을 확인할 수 있습니다.
MoRA는 지침 조정 및 수학적 추론에서 LoRA와 비슷한 성능을 보입니다.
그러나 새로운 지식을 암기하는 고차원 업데이트의 이점 덕분에, MoRA는 Continual Pretraining에서 생물의학 및 금융 분야에서 LoRA보다 더 나은 성능을 보였습니다.
LoRA 변형들은 LoRA와 비교했을 때 이 fine-tuning tasks에서 유사한 성능을 나타냈습니다.
AsyLoRA는 instruction tuning에서 최고의 성능을 달성했지만, 수학적 추론에서는 낮은 성능을 보였습니다.
ReLoRA의 경우, 훈련 중 low-rank를 병합하는 것이 특히 높은 랭크(256)에서 성능에 해를 끼칠 수 있음을 발견했습니다.
Analysis
High-rank Updating
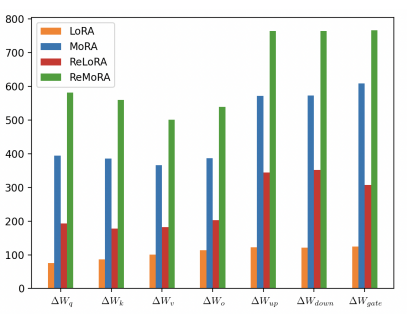
High-rank Update가 ∆W의 랭크에 미치는 영향을 입증하기 위해, 250M 사전 훈련 모델에서 학습된 ∆W의 특이값 스펙트럼을 분석했습니다.
모든 레이어에 걸쳐 ∆Wq, ∆Wk, ∆Wv, ∆Wo, ∆Wup, ∆Wdown, ∆Wgate에 대해 0.1을 초과하는 특이값의 평균 개수를 위의 그림에 제시했습니다.
MoRA와 ReMoRA는 LoRA와 ReLoRA에 비해 상당히 높은 수의 유의미한 특이값을 보여주며, 본 모델이 ∆W의 랭크를 증가시키는 데 효과적임을 강조합니다.
Influence of Decompression and Compression

decompression and compression functions in MoRA의 영향을 판단하기 위해 다양한 방법(truncation, sharing, decoupling, and rotation)을 사용한 성능을 위의 표에 제공합니다.
Truncation은 compression 중에 상당한 정보 손실이 발생하여 최악의 성능을 보였습니다.
Sharing은 입력 정보를 보존하기 위해 공유된 행 또는 열을 활용하여 절단보다 더 나은 성능을 달성할 수 있습니다.
하지만 r = 8의 경우, 많은 수의 행 또는 열을 공유하기 때문에 공유 방법은 decoupling, and rotation보다 성능이 낮았습니다(섹션 4에서 논의함).
rotation은 decoupling보다 효율적인데, 이는 회전 정보가 square matrix가 입력 정보를 구별하는 데 도움을 줄 수 있기 때문입니다.
Conclusion
LoRA의 한계를 파악하고 극복하기 위해 non-parameterized operators for high-rank updating를 사용하는 MoRA방법을 소개합니다.
다양한 비교 실험을 진행하였고 여러 실험에서 우수한 성능을 보이는 것을 확인했습니다.
