느낀점
- 다수결 방식으로 요정도 성능? 매우 인상적
- 레이블 없이도 성능 개선이 폭이 큼
- 1.5B에서 AIME 성능 개선이 없는 것이 아마 어려운 질문에 다수결 투표가 아마 의미가 없어보임. 점점 더 어려운 문제가 많이 나올텐데 어려운 문제에서 다수결 방식이 의미가 있을지 의심됨
Abstract
LLM에서 추론 작업에 대한 명확한 레이블이 없는 데이터에 대한 강화 학습을 연구합니다.
이 문제의 핵심은 정답 정보에 접근할 수 없는 추론 과정에서 보상을 추정하는 것입니다.
이러한 설정은 파악하기 어려워 보이지만 다수결 투표와 같은 일반적인 테스트 타임 스케일링 방식이 RL 학습을 유도하는 데 놀라울 정도로 효과적인 보상을 제공한다는 것을 발견했습니다.
본 연구에서는 레이블이 없는 데이터를 사용하여 LLM을 학습시키는 새로운 방법인 테스트 타임 강화 학습(TTRL)을 소개합니다.
TTRL은 사전 학습된 모델의 사전 지식을 활용하여 LLM의 자체 발전을 가능하게 합니다.
TTRL이 다양한 작업과 모델에서 성능을 일관되게 향상시킨다는 것을 보여줍니다.
TTRL은 레이블이 없는 테스트 데이터만으로 AIME 2024에서 Qwen-2.5-Math-7B의 pass@1 성능을 약 159% 향상시켰습니다.
TTRL은 Maj@N 메트릭에 의해서만 supervised 되었음에도 불구하고 초기 모델의 상한선을 꾸준히 넘어서고 정답 레이블로 테스트 데이터에 직접 학습된 모델의 성능에 근접하는 성능을 보여주었습니다.

Introduction
테스트 타임 스케일링(TTS)은 LLM의 추론 능력을 향상시키기 위한 새로운 방법입니다.
TTS는 사전 학습 중의 스케일링보다 계산적으로 더 효율적이며 동일한 계산 투자로 더 뛰어난 성능을 가능하게 합니다.
다수의 연구에서 보상 모델 및 디코딩 단계에서의 몬테카를로 트리 탐색과 같은 전략을 사용하여 TTS를 향상시키는 방법을 탐구했습니다.
DeepSeek-R1, OpenAI의 o1과 같은 최근의 주요 대규모 추론 모델(LRM)은 강화 학습이 chain-of-thought를 향상시키는 데 중요한 역할을 한다는 것을 강조합니다.
LRM은 여전히 레이블이 없고 새로운 데이터 스트림을 해결하는 데 어려움을 겪습니다.
TTS에 대한 이러한 연구들은 학습 시간에 초점을 맞춘 RL 기반 접근 방식에서 학습 시간과 테스트 시간 동작 간의 불일치를 분명히 보여주었습니다.
그러나 대규모 학습 데이터에만 RL을 적용하는 것은 새롭고 복잡한 입력의 새로운 특징이나 분포 변화를 처리하는 데 매우 불충분합니다.
새로운 테스트 데이터를 사용하여 테스트 시간에 모델 파라미터를 업데이트할 수 있는 테스트 타임 학습(TTT) 방법이 점점 더 많은 관심을 받고 있습니다.
TTT는 테스트 시간에 RL을 사용하여 모델을 미세 조정함으로써 TTS를 발전시키고 새로운 데이터에 대한 일반화 성능을 향상시키는 방법을 제시합니다.
하지만 여전히 질문이 남아있습니다.
테스트 시간에 RL에 대한 보상이나 검증자를 어떻게 얻을 수 있을까요?
실제 작업의 복잡성과 양이 증가함에 따라 RL을 위해 대규모로 이러한 데이터를 주석 처리하는 것은 점점 더 비실용적이 됩니다.
이는 주요 모델의 지속적인 학습에 상당한 장애물이 됩니다.
이러한 문제를 해결하기 위해 RL을 통해 테스트 타임 학습을 수행하는 테스트 타임 강화 학습(TTRL)을 소개합니다.
TTRL은 롤아웃 단계에서 반복적인 샘플링 전략을 사용하여 레이블을 정확하게 추정하고 규칙 기반 보상을 계산하여 레이블이 없는 데이터에 대한 RL을 가능하게 합니다.
효과적인 다수결 투표 보상을 통합함으로써 TTRL은 정답 레이블이 없는 상황에서 효율적이고 안정적인 RL을 진행합니다.
더 어려운 작업의 발생은 레이블이 없는 데이터가 더 큰 비율이 될 것입니다.
TTRL은 지도학습 없이 모델을 학습시키는 문제에 직접적으로 대처하여 어렵지만 중요한 설정에서 모델의 탐색 및 학습 능력을 조사합니다.
TTRL은 모델이 자체 경험을 생성하고 보상을 추정하며 시간이 지남에 따라 성능을 향상시킬 수 있도록 합니다.
실험에서 Qwen2.5-Math-7B에 TTRL을 적용한 결과 AIME 2024에서 159%(13.3-> 43.3)의 성능 향상을 보였으며, AMC, AIME, MATH-500에서 평균 84%의 이득을 얻었습니다.
이러한 개선은 레이블이 지정된 학습 데이터 없이 자체 발전을 통해 달성되었으며 다른 작업으로 더욱 일반화됩니다.
TTRL은 pass@1에서의 성능을 향상시킬 뿐만 아니라 다수결 투표를 통해 TTS를 개선합니다.
TTRL이 다양한 규모와 유형의 모델에서 효과적이며 기존 RL 알고리즘과 통합될 수 있음을 시사합니다.
주요 결과
- 다수결 투표는 TTRL을 위한 효과적인 보상 추정치를 제공합니다.
- TTRL은 자체 학습 신호 및 상한선인 Maj@N을 초과하고 정답이 있는 테스트 데이터에 대한 직접 학습 성능과 매우 유사합니다.
- 비지도 방식으로 효율적이고 안정적인 RL을 달성할 수 있습니다.

Test-Time Reinforcement Learning (TTRL)
알려진 보상 신호로부터 학습하는 전통적인 RL과는 달리 TTRL은 레이블이 없는 테스트 데이터에서 작동합니다.
모델은 명시적인 지도 없이 학습하고 적응해야 합니다.
우리의 과제는 다음과 같이 정의됩니다.
정답 레이블 없이 RL을 사용하여 테스트 시간 동안 사전 학습된 모델을 학습시키는 문제를 연구합니다.
우리는 이러한 설정을 테스트 타임 강화 학습이라고 부릅니다.
Methodology
그림 2는 TTRL이라는 접근 방식이 문제를 어떻게 해결하는지 보여줍니다.
프롬프트 x로 표현되는 상태가 주어지면, 모델은 파라미터 θ로 매개변수화된 정책 에서 샘플링된 출력 y를 생성하여 행동합니다.
정답 레이블 없이 보상 신호를 구성하기 위해 모델에서 반복적인 샘플링을 통해 여러 후보 출력 을 생성합니다.
예를 들어, 다수결 투표 또는 다른 집계 방법을 통해 최적의 행동에 대한 프록시 역할을 하는 consensus 출력 를 도출합니다.
그런 다음 샘플링된 행동 y와 consensus 행동 간의 일치도에 따라 보상 를 제공합니다.
따라서 RL 목표는 기대 보상을 최대화하는 것이며,
(1)
파라미터 θ는 경사 상승법을 통해 업데이트됩니다.
(2)
여기서 η는 학습률을 나타냅니다. 이 접근 방식을 통해 모델은 추론 중에 적응하여 레이블링된 데이터 없이도 분포가 이동된 입력에 대한 성능을 효과적으로 향상시킬 수 있습니다.
Majority Voting Reward Function
다수결 투표 보상은 먼저 다수결 투표를 통해 레이블을 추정하여 결정됩니다.
추정된 레이블은 최종 보상 역할을 하는 규칙 기반 보상을 계산하는 데 사용됩니다.
질문 x가 주어지면 먼저 x를 LLM에 입력하여 일련의 출력을 생성합니다.
그런 다음 답변 추출기가 이러한 출력을 처리하여 해당 예측 답변(P = {})을 얻습니다.
먼저 P에 대해 방정식 4를 따라 다수결 투표를 점수 함수 s(y, x)로 사용하여 P에서 가장 자주 발생하는 예측인 y를 얻어 레이블을 추정합니다.
그런 다음 다수결 투표로 얻은 예측 y는 규칙 기반 보상\을 계산하기 위한 추정된 레이블로 사용됩니다.
보상 함수는 다음과 같습니다.
(3)
from collections import Counter
def majority_voting_reward_fn(outputs) :
각 출력에서 추출한 답변이 다수결 답변과 일치하면 1의 보상을 할당하고, 그렇지 않으면 0을 할당합니다.
# 각 출력에서 답변을 추출합니다.
answers = [extract_answer(output)for output in outputs]
# 다수결 답변을 찾습니다.
counts = Counter(answers)
majority_answer, _ = counts.most_common(1) [0]
# 보상을 할당합니다. 답변이 다수결 답변과 일치하면 1, 그렇지 않으면 0입니다.
rewards = [1 if ans == majority_answer else 0 for ans in answers ]
return rewards
outputs = llm.generate(problem, n = N)
rewards = majority_voting_reward_fn(outputs)Experiments

성능 많이 오르는 게 인상적
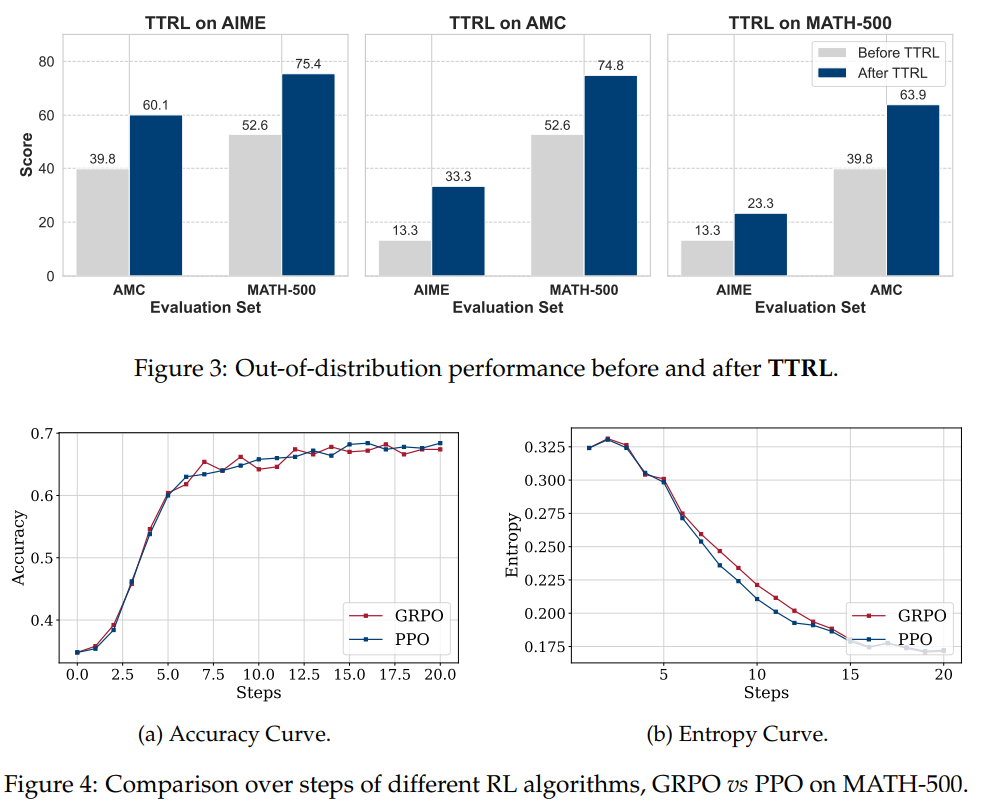
GRPO랑도 비슷하거나 더 좋거나
