느낀점
- 이미지 생성과 이미지 이해를 동시에 수행할 수 있는 모델을 오픈소스로 풀어서 매우 감동
- 인코더를 분리해서 사용하는 부분이 간단하면서 독창적임
- Rectified Flow가 두 분포 사이의 맵핑을 효율화하는 모듈로 효과적으로 적용된 거 같음
- 여전히 중국산? 데이터가 어떤 식으로 수집하고 활용되는지 알 수 없음
- 중국 모델들 학습 단계에 매우 큰 공을 들이고 그 방식도 창의적인 거 같음
Abstract
딥시크에서 이미지 이해와 이미지 생성을 단일 모델에서 통합하는 인공지능 프레임워크인 JanusFlow를 소개합니다.
JanusFlow는 autoregressive language models과 생성 모델링의 기법인 rectified flow을 결합한 minimalist 아키텍처를 도입합니다.
rectified flow가 대형 언어 모델 프레임워크 내에서 별다른 아키텍처 수정 없이 간단하게 학습될 수 있음을 보여주는 점을 발견하였습니다.
통합된 모델의 성능을 향상시키기 위해 두 가지 핵심 전략을 채택합니다.
-
Understanding와 generation encoder를 분리(decoupling)
-
학습 과정에서 여러 representations을 alignment
Introduction
LLM은 다양한 지식을 학습하고 새로운 상황에 일반화하는 데 있어 놀라운 능력을 보여주었습니다.
이러한 능력을 이용하여 연구자들은 Image-Understanding, text-image generation에 특화된 모델을 개발했습니다.
최근 연구는 두 작업을 동시에 처리할 수 있는 통합 시스템을 구축하는 방향으로 전환되고 있습니다.
한 가지 자주 사용되는 접근법은 사전 학습된 text-image generation 모델을 활용하여 고품질의 이미지를 생성하고, LLM을 이를 학습하여 이러한 모델을 위한 conditions을 생성하는 방식입니다.
그러나 이 방법은 아키텍처가 복잡해지고, LLM과 생성 모델을 별도로 유지해야 해서 모델의 능력을 제한할 가능성이 있습니다.
해결책으로 single LLM을 두 가지 작업에 모두 활용하는 접근법도 제안되었고, 일반적으로 diffusion models 또는 vector-quantized autoregressive models을 통합하는 방식이 사용됩니다.
우리의 접근법은 최근 rectified flow 모델에서의 발전을 기반으로 합니다.
rectified flow 모델은 단순한 생성 모델링 프레임워크를 제공하면서도 뛰어난 성능을 보여줍니다.
JanusFlow는 rectified flow을 LLM 아키텍처와 통합한 멀티모달 모델입니다.
minimalist 설계 원칙을 따르는 JanusFlow는 LLM을 rectified flow 작업에 맞추기 위해 가벼운 인코더와 디코더만을 필요로 합니다.
JanusFlow의 성능을 최적화하기 위해 두 가지 핵심 전략을 적용하였습니다.
- 이미지 이해 및 생성 작업을 위한 vision encoder를 분리하여 작업 간 간섭을 방지하고 이해 능력을 강화하였습니다.
- 학습 과정에서 생성 및 이해 모듈 간 intermediate representation을 정렬하여 생성 과정에서의 의미적 일관성을 강화하였습니다.

실험 결과 매우 높은 성능을 달성하는 것을 확인하였습니다.
JanusFlow
JanusFlow의 아키텍처와 학습 전략을 소개합니다
Background
Multimodal LLMs
주어진 데이터셋 는 이산 토큰 시퀀스를 포함하며 각 시퀀스는 다음과 같이 표현될 수 있습니다:
LLM은 이러한 시퀀스 분포를 Autoregressive 방식으로 모델링하도록 학습됩니다.
은 LLM의 파라미터를 나타내며 ℓ은 시퀀스 길이를 의미합니다.
대규모 데이터셋에서 학습된 LLM은 다양한 작업을 일반화하고 다양한 명령을 따르는 능력을 가지고 있습니다.
이러한 모델을 시각적 입력을 처리할 수 있도록 확장하기 위해 LLM에 비전 인코더를 추가합니다.
예를 들어, LLaVA는 pre-trained CLIP 이미지 인코더를 LLM과 프로젝션 레이어를 통해 결합하여, 추출된 이미지 특징을 LLM이 단어 임베딩처럼 사용할 수 있는 임베딩 공간으로 변환합니다.
대규모 멀티모달 데이터셋과 강력한 LLM을 활용함으로써 다양한 비전-언어 작업을 수행할 수 있는 멀티모달 모델의 개발을 할 수 있게 되었습니다
Rectified Flow
연속적인 차원에서 로 구성된 데이터셋 가 주어졌을 때, rectified flow는 다음과 같은 보통 미분 방정식(ODE)을 학습하여 데이터 분포를 모델링합니다:
여기서 은 velocity neural network의 파라미터이며, 는 일반적으로 표준 가우시안 노이즈 로 설정되는 단순 분포입니다.
이 네트워크는 유클리드 거리 손실을 최소화하도록 학습됩니다.
여기서
입니다.
네트워크가 충분한 capacity을 가지고 있고, optimal velocity field 가 학습되면, 초기 분포 는 데이터 분포 로 매핑됩니다.
즉,
의 분포는 을 따르게 됩니다.
이러한 rectified flow는 개념적으로 단순하지만, 텍스트-이미지 생성, 오디오 생성등의 다양한 생성 모델링 작업에서 우수한 성능을 보였습니다.
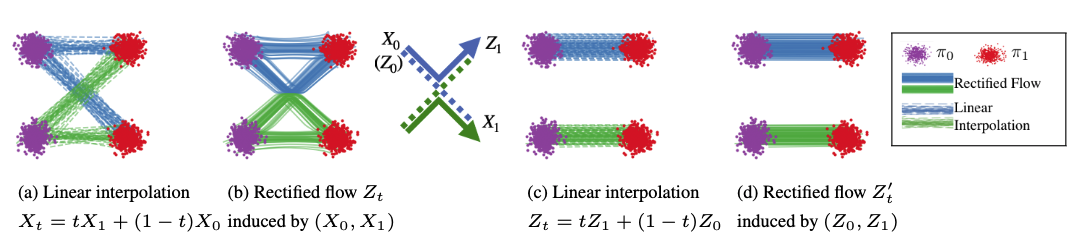
두 분포 간의 전송 매핑을 학습하는 생성 모델로, 직선 경로(Straight Path)를 통해 데이터를 생성하는 방법론이다.
A Unified Framework for Multimodal Understanding and Generation
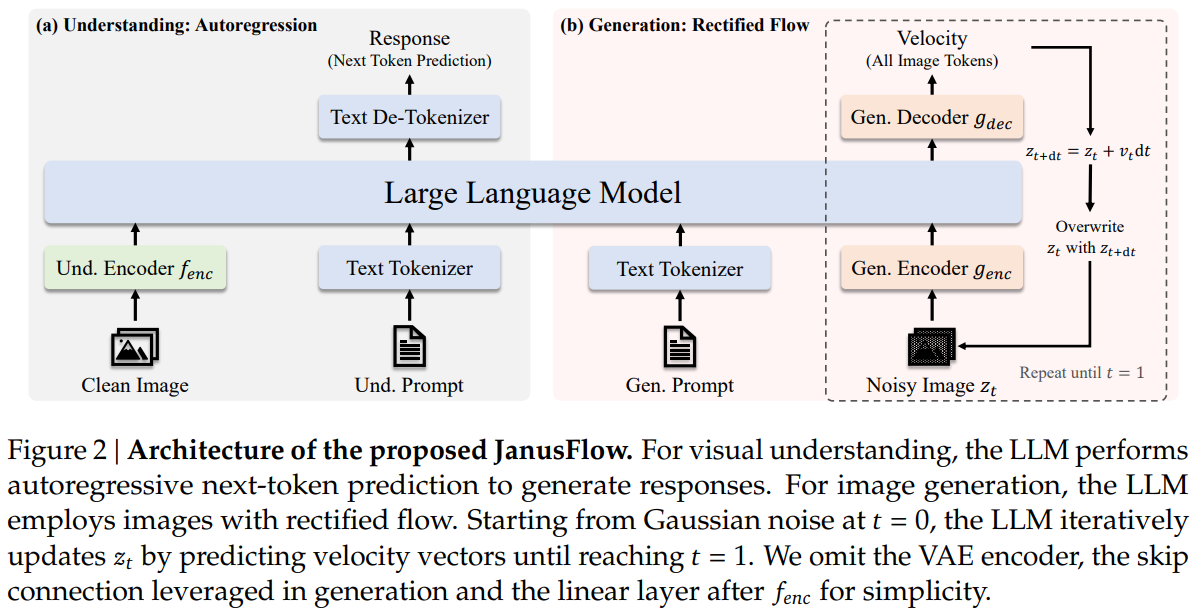
JanusFlow는 시각적 이해 및 이미지 생성 작업을 모두 처리할 수 있도록 설계된 프레임워크를 제공합니다.
JanusFlow가 하나의 LLM 아키텍처 내에서 이 두 가지 작업을 처리하는 방법을 설명합니다.
Multimodal Understanding
멀티모달 이해 작업에서 LLM은 텍스트와 이미지 데이터가 혼합된 입력 시퀀스를 처리합니다.
텍스트는 이산 토큰으로 토큰화되어 차원의 임베딩으로 변환됩니다.
이미지의 경우, 이미지 인코더 가 각 이미지 을 크기의 feature map으로 변환됩니다.
Feature map은 평탄화된 후 선형 변환 레이어를 통해 크기의 임베딩 시퀀스로 변환됩니다.
텍스트 및 이미지 임베딩은 LLM 입력 시퀀스로 연결되며, 모델은 Autoregressive 방식으로 다음 토큰을 예측합니다.
일반적인 관행에 따라 이미지 시작을 나타내는 특별 토큰 와 이미지 끝을 나타내는 를 추가하여 모델이 이미지 임베딩을 시퀀스 내에서 올바르게 위치시킬 수 있도록 합니다.
Image Generation
이미지 생성 시 LLM은 조건이 되는 텍스트 시퀀스 을 받아 rectified flow를 사용하여 해당 이미지를 생성합니다.
연산 효율성을 높이기 위해 생성은 사전 학습된 SDXL-VAE의 잠재 공간에서 동작됩니다.
생성 과정은 가우시안 노이즈 를 샘플링하는 것으로 시작됩니다.
이는 생성 인코더 에 의해 변환되어 크기의 임베딩 시퀀스를 형성합니다.
이 시퀀스는 현재 시간 단계 를 나타내는 시간 임베딩과 연결되며 초기 길이는 이 됩니다.
이전 방법들과 달리 attention 마스킹 전략이 필요 없음을 발견했습니다.
LLM의 출력은 생성 디코더 를 통해 다시 변환되어 크기의 속도 벡터를 생성하며 상태는 오일러 해석법을 사용하여 업데이트됩니다.
여기서 는 사용자 정의한 step입니다.
이 과정을 반복하여 최종 상태 을 얻고 VAE 디코더를 통해 최종 이미지를 생성합니다.
이미지 생성 품질을 향상시키기 위해, 분류기 없는 가이던스(Classifier-Free Guidance, CFG)를 적용합니다.
여기서 는 텍스트 조건 없이 추론된 속도이고 은 CFG 강도를 조절하는 하이퍼파라미터입니다.
실험적으로 를 증가시키면 semantic alignment가 개선됨을 확인했습니다.
멀티모달 이해와 유사하게 이미지 생성을 시작할 때 토큰을 추가합니다.
Decoupling Encoders for the Two Tasks
이전의 Autoregressive 생성과 확산 모델을 통합하는 공동 LLM 학습 프레임워크에서는 이해 및 생성 작업 모두에 동일한 인코더 , 를 사용했습니다.
그러나 최근의 통합 Autoregressive 모델 연구에서는 이러한 공유 인코더 설계가 최적이 아님을 확인할 수 있습니다.
특히, 벡터 양자화된 토큰을 기반으로 Autoregressive 방식으로 이미지를 생성하는 모델에서 이 문제가 두드러졌다.
이러한 통찰을 바탕으로, JanusFlow는 분리된 인코더 설계를 채택하였다.
멀티 모달 이해를 위한 의미적 연속 특성을 추출하기 위해 사전 학습된 SigLIP-Large-Patch/16 모델을 로 사용하며, 생성 작업을 위해서는 별도로 초기화된 ConvNeXt 블록을 , 로 활용하였습니다.
기존 연구를 따라 와 사이에 긴 스킵 연결을 추가하였습니다.
4.5절의 실험 결과에 따르면 이러한 분리된 인코더 설계는 통합 모델의 성능을 크게 향상시키는 것으로 나타났습니다.
JanusFlow의 전체 아키텍처는 그림 2에 제시되어 있습니다.
Training Schemes
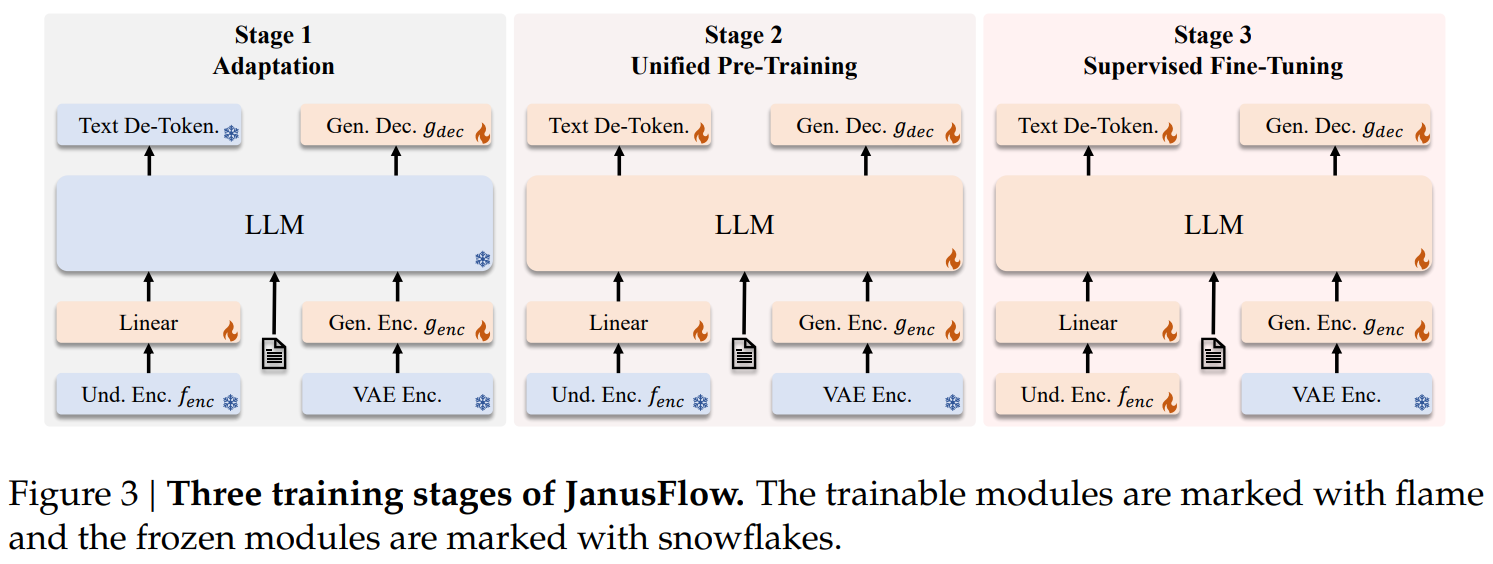
Stage 1: Adaptation of Randomly Initialized Components
첫 번째 단계에서는 무작위로 초기화된 모듈(선형 레이어, 생성 인코더, 생성 디코더)만을 학습하는 데 집중합니다.
이 단계는 새로운 모듈들이 사전 학습된 LLM 및 SigLIP 인코더와 효과적으로 작동하도록 적응하는 과정으로 새롭게 도입된 구성 요소들의 초기화 단계 역할을 합니다.
Stage 2: Unified Pre-Training
1단계 이후 기존 연구에 따라 시각적 인코더를 제외한 전체 모델을 학습합니다.
이 과정에서는 다중 모달 이해, 이미지 생성, 텍스트 전용 데이터의 세 가지 유형의 데이터를 활용합니다.
먼저 모델의 이해 능력을 구축하기 위해 멀티 모달 이해 데이터의 비율을 높게 설정한 후, 확산 기반 모델의 수렴 요구사항을 반영하여 이미지 생성 데이터의 비율을 점진적으로 증가시킵니다.
Stage 3: Supervised Fine-Tuning (SFT)
마지막 단계에서는 대화 데이터, 특정 작업 관련 대화, 고품질 텍스트 조건부 이미지 생성 예제로 구성된 instruction tuning 데이터를 활용하여 사전 학습된 모델을 미세 조정합니다.
이 과정에서 SigLIP 인코더의 매개변수를 unfreeze하여 함께 학습하며, 이를 통해 모델이 다중 모달 이해 및 이미지 생성 작업에서 사용자 명령에 효과적으로 응답할 수 있도록 한다.
