느낌점
- 디퓨전은 거창하지만 결국 마스크 샘플링을 복원하는건 transformer의 역할
- 성능이 너무 애매함(유사하거나 비슷하다고 표현함)
- 역방향 저주 관련한 문제는 해결 방법이 많이 나온 거 같음
- 속도도 느리고 성능도 애매하면 트렌드를 바꿀 수 있을지 의문
Abstract
Autoregressive models(ARM)은 LLM의 초석으로 알려져 있습니다.
처음부터 Diffusion 형태로 학습한 모델인 LLaDA를 도입하여 이러한 통념을 깨기 위해 도전합니다.
LLaDA는 순방향 데이터 마스킹 프로세스와 역방향 프로세스를 통해 데이터 분포를 모델링하며 이는 마스킹된 토큰을 예측하기 위해 Transformer로 파라미터화됩니다.
LLaDA는 likelihood bound를 최적화함으로써 확률적 추론을 위한 새로운 텍스트 생성 방식을 제공합니다.
다양한 실험에서 LLaDA는 ARM 기준 모델보다 우수한 성능을 보였습니다.
LLaDA 8B는 in-context learning에서 LLaMA3 8B와 같은 LLM과 경쟁할만하며, SFT 후에는 멀티턴 대화와 같은 사례에서 인상적인 지시 추종 능력을 보여줍니다.
LLaDA는 역방향으로 작성하는 시(poem) 작성 작업에서 GPT-4o를 능가하며 역방향 저주(reversal curse) 문제도 해결할 수 있습니다
Introduction
LLMs은 생성 모델링 프레임워크 내에서 완전히 동작합니다.
구체적으로 설명하면 LLM은 maximum likelihood estimation, 즉 두 확률 분포 간 KL 발산 최소화를 통해 언어 분포 를 학습하고자 합니다:
대부분의 접근 방식은 autoregressive modeling(ARM)으로 다음 토큰 예측(next-token prediction)이라고 불리는 방법을 활용하여 모델 분포를 정의합니다:
ARM은 매우 효과적인 것으로 입증되었으며 현재 LLM의 백본이 되었습니다.
그러나 여전히 근본적인 의문이 남아 있습니다
"ARM이 LLM이 보여주는 고성능을 구현하는 유일한 방법인가?"입니다
우리는 이와 같은 질문에 "예"라고 단순한 답이라고 생각하지 않습니다
우리는 생성형 모델의 특성이 ARM 때문이 아닌 생성 모델링 원칙이라는 점이라고 정의합니다.
특히, 확장성(scalability)은 트랜스포머, 모델 크기 및 데이터 크기, 생성 원칙에 의해 유도된 Fisher consistenc의 상호작용의 결과이지 ARM의 고유한 특징이 아니라고 주장합니다.
또한, instruction-following과 in-context learning 능력도 구조적으로 일관된 언어적 작업에서 모든 적절한 조건부 생성 모델의 내재적 특성이지 자가회귀 모델만이 가질 수 있는 장점이라 생각하지 않습니다
또한, ARM 모델은 lossless data compression으로 해석될 수 있지만 충분히 표현력이 높은 확률 모델은 유사한 능력을 가질 수 있다고 생각합니다.
하지만 ARM 모델은 몇 가지 문제점이 존재합니다.
- token-by-token generation으로 인해 높은 연산 비용 발생
- left-to-right modeling으로 인해 역추론(reverse reasoning) 작업 수행이 어려움
이러한 문제점는 LLM이 더 긴 context와 복잡한 작업을 처리하는 능력을 제약합니다.
LLaDA(를 도입하여, LLM이 ARM 없이도 생성 모델링 원칙을 통해 기존 LLM의 능력을 구현할 수 있는지를 연구했습니다.
LLaDA는 masked diffusion model(MDM) 을 활용합니다
이 모델은 random masking process을 사용한 확산 과정과 이를 복원하는 mask predictor를 훈련하여 bidirectional 의존성을 가진 모델 분포를 구축합니다.
기여
-
확장성(Scalability)
LLaDA는 10²³ FLOPs까지 효과적으로 확장되며, 동일한 데이터에서 훈련된 ARM 모델과 비교해 6개 작업(MMLU, GSM8K 등)에서 유사한 성능을 달성했습니다. -
In-Context Learning
LLaDA 8B는 15개의 Zero/Few-shot Learning 작업에서 LLaMA2 7B를 거의 모두 능가하였으며, LLaMA3 8B와 비슷한 성능을 보였습니다. -
Instruction-Following
LLaDA는 SFT 후 명령어 수행 능력이 크게 향상되었으며 다중 턴 대화와 같은 사례에서도 이를 확인할 수 있습니다. -
Reversal Reasoning
LLaDA는 역추론 문제에서 일관된 성능을 보이며, reversal curse를 해결했습니다. 특히, 역방향 시 완성(poem completion task)에서 GPT-4o를 능가하는 성능을 기록하였습니다.
Approach
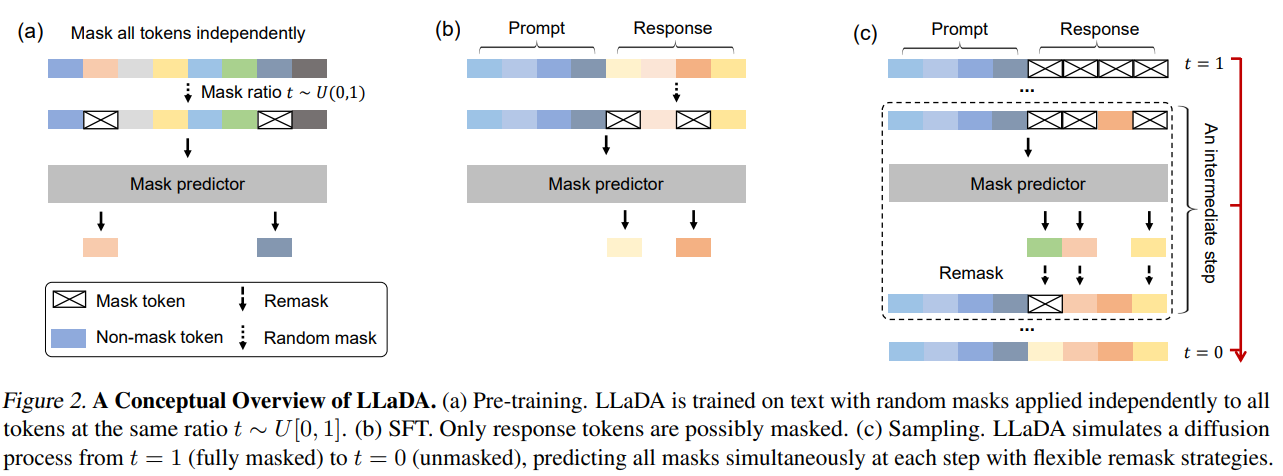
사전학습 - SFT - Sampling 3단계로 LLaDA가 구성되어 있는 모습을 확인할 수 있습니다.
Probabilistic Formulation
LLaDA는 순방향 과정과 역방향 과정을 통해 모델 분포 를 정의합니다.
순방향 과정에서는 의 토큰을 독립적으로 점차 마스킹하여 일 때 시퀀스가 완전히 마스킹되도록 합니다.
에서 시퀀스 는 부분적으로 마스킹되며, 각 토큰이 마스킹될 확률은 , 마스킹되지 않을 확률은 으로 정의합니다.
역방향 과정에서는 가 1에서 0으로 이동하면서 점진적으로 마스킹된 토큰을 예측하여 원래 데이터 분포를 복원하는 과정을 거칩니다.
LLaDA의 핵심 요소는 mask predictor로 로 표현되며, 입력 를 받아 모든 마스킹된 토큰( 으로 표기됨)을 동시에 예측한다.
이 모델은 크로스 엔트로피 손실을 사용하여 마스킹된 토큰에 대해서만 학습이 됩니다.
여기서:
- 는 훈련 데이터에서 샘플링
- 는 에서 균일하게 샘플링
- 는 순방향 과정에서 샘플링
- indicator function 는 손실이 마스킹된 토큰에 대해서만 계산
훈련 후, 역방향 과정을 시뮬레이션하여 mask predictor에 의해 매개변수화된 모델 분포 를 정의할 수 있으며 에서 유도된 marginal distribution로 나타납니다.
LLaDA는 마스킹 비율을 0과 1 사이에서 무작위로 변화시키는 방식을 사용하는 반면 기존의 masked language models(MLM)은 고정된 비율을 사용한다.
이러한 미묘한 차이는 확장성에서 중요한 영향을 미친다.
위의 식에서 알 수 있듯이 LLaDA는 자연스럽게 맥락 내 학습을 수행할 수 있는 생성 모델이며, 극단적인 경우에도 Fisher consistency 을 보장하여 대규모 데이터 및 모델에서 확장성을 기대할 수 있습니다.
Pre-training
LLaDA는 Transformer를 mask predictor로 사용하며, LLMs과 유사한 구조를 가집니다.
그러나 LLaDA는 causal mask 를 사용하지 않았고 전체 입력을 한 번에 볼 수 있도록 설계되었습니다.
서로 다른 크기의 두 가지 LLaDA(1B, 8B) 을 훈련했습니다.
대부분의 하이퍼파라미터를 일관되게 유지하면서 몇 가지 필수적인 수정 사항을 적용했습니다.
- LLaDA는 KV 캐싱(KV caching)을 사용할 수 없음
- 단순함 위해 grouped query attention 대신 vanilla multi-head attention 사용.
- 어텐션 레이어의 매개변수 수 증가 → 모델 크기를 유지하기 위해 FFN 차원 감소.
- 토크나이저의 차이로 인해 vocab size 약간 다름.
훈련 데이터:
- 총 토큰 수: 2.3조 (2.3T)
- 데이터 출처: 기존 LLM과 유사한 데이터 프로토콜.
- 데이터 필터링: 온라인 코퍼스에서 수집 후 LLM 기반 필터링 적용.
- 포함된 데이터 유형: 일반 텍스트, 고품질 코드, 수학, 다국어 데이터.
훈련 설정:
- 최대 시퀀스 길이: 4096 토큰
- 총 연산 비용: 0.13M H800 GPU 시간
- 훈련 과정:
- 훈련 시퀀스 샘플링
- 무작위 샘플링 후, 각 토큰을 확률로 독립적으로 마스킹하여 생성
- SGD
- 학습률 스케줄러: Warmup-Stable-Decay 사용
Supervised Fine-Tuning
LLaDA의 follow instructions 능력을 향상시키기 위해 SFT을 수행했습니다.
SFT는 가장 기본적인 후처리 방법으로, 프롬프트 와 응답 쌍을 사용하여 를 학습하는 방식입니다.
- 총 데이터셋: 450만 개(4.5M) 쌍
- 도메인: 코드, 수학, 명령어 따르기, 구조적 데이터 이해
- 훈련 프로토콜: 기존 LLM(SFT) 방식과 일치
- 최적화 기법: 추가적인 최적화 기술 없음
Inference
LLaDA는 새로운 텍스트 생성(sampling) 및 likelihood evaluation 가 가능합니다.
- 샘플링: 완전히 마스킹된 응답에서 시작하여 역방향 과정으로 생성.
- 리마스킹 전략:
- 저신뢰 리마스킹 (low-confidence remasking)
- 반자가회귀 리마스킹 (semi-autoregressive remasking)
- 비지도(classifier-free) 방법을 활용한 확률 평가 가능.
