[논문 리뷰] Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
요즘 회사에서 서비스를 하기 위해서 허깅페이스를 뒤지는 일이 굉장히 많아졌습니다 ㅎㅎ
항상 새로운 모델이 출시하면 데모 페이지를 통해 한국어 테스트를 많이 진행하고 있습니다
여러 모델 Phi, LLama, gemma, mistral...와 같이 아파치 라이선스를 따르고 있는 모델들을 사용하면서 한국어를 얼마나 이해하고 있는지,
학습이 원하는 방향대로 진행되는지를 테스트를 하고 있습니다.
현재 기준으로 제 체감상 가장 한국어를 잘하고 한국어 튜닝이 잘되는 모델인 알리바바에서 출시하는 Qwen 시리즈인 거 같습니다.
잘되는 이유의 뇌피셜..
- 중국은 지리적으로도 한국과 가까운 위치에 있고
- 한자와 한국어가 임베딩이 비슷한 위치에 있고(한글자리에 한자 나오는 경우 매우 높음)
- 한국어 데이터를 적극적으로 사용하고 있는 느낌(크롤링을 수집을 적극적으로 하는 느낌)
등으로 알리바바에 Qwen 시리즈를 실험, 서비스, 논문 작성등에 적극적으로 사용하고 있습니다.
이런 모델 시리즈에서 드디어 Qwen2-VL 모델이 등장했습니다.
한국어를 잘하는 멀티모달 오픈 소스가 부족하였는데 가뭄에 단비 같은 모델이 등장하여 실제로 사용해보고
어떤 식으로 학습을 진행하였는지 궁금해졌습니다.
알리바바에서 발간한 Techincal Report를 통해 어떤 식으로 모델을 만들었는지 살펴보겠습니다.
Abstract
본 논문은 이미지와 텍스트를 모두 인식하고 이해할 수 있도록 고안된 Qwen-VL 시리즈를 소개합니다.
Qwen-LM(Language Model)을 기반하여 시각 인식 능력을 추가하기 위해
visual receptor, input-output interface, 3-stage training pipeline, multilingual multimodal cleaned corpus ((1) 시각 수용기, (2) 입력-출력 인터페이스, (3) 3단계 학습 파이프라인, (4) 다국어 멀티모달 정제 코퍼스)
를 설계했습니다.
기존의 이미지 설명 및 질문-응답 기반의 모델을 넘어서 이미지 속 텍스트 읽기 및 그라운딩(링크와 같은 다른 정보와의 연결)이 가능한 형태까지 추가하였습니다.
모델을 만들어 다양한 벤치마크에서 높은 성능을 보여 우수성을 증명했습니다.
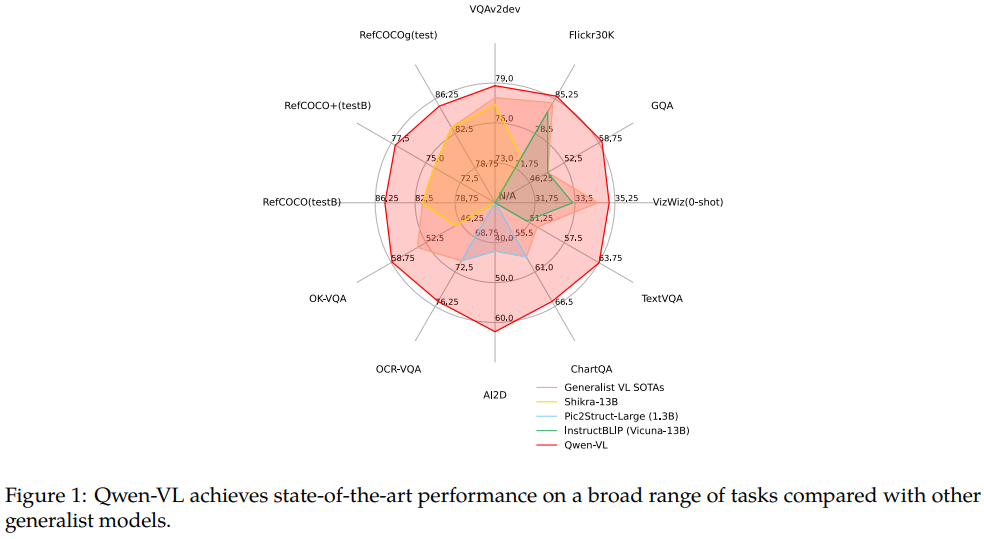
우수한 벤치마크 성능 지표

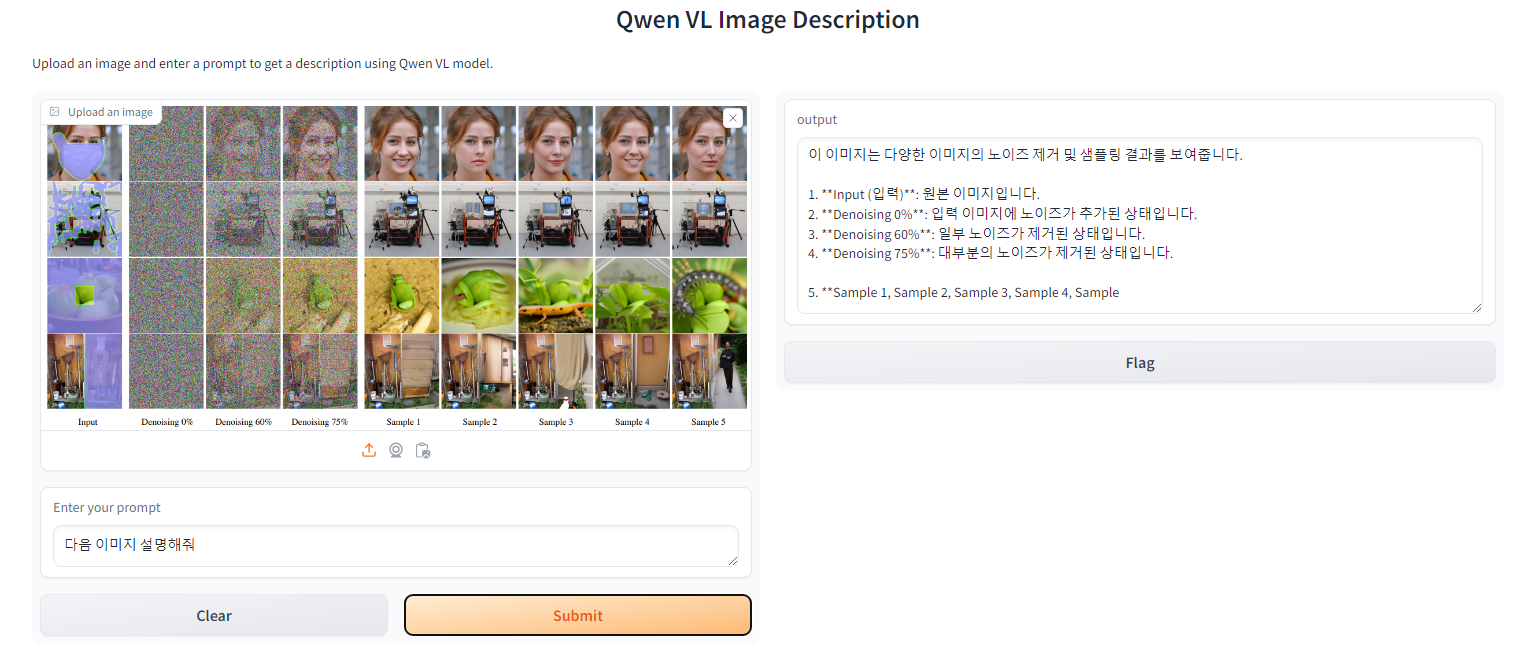
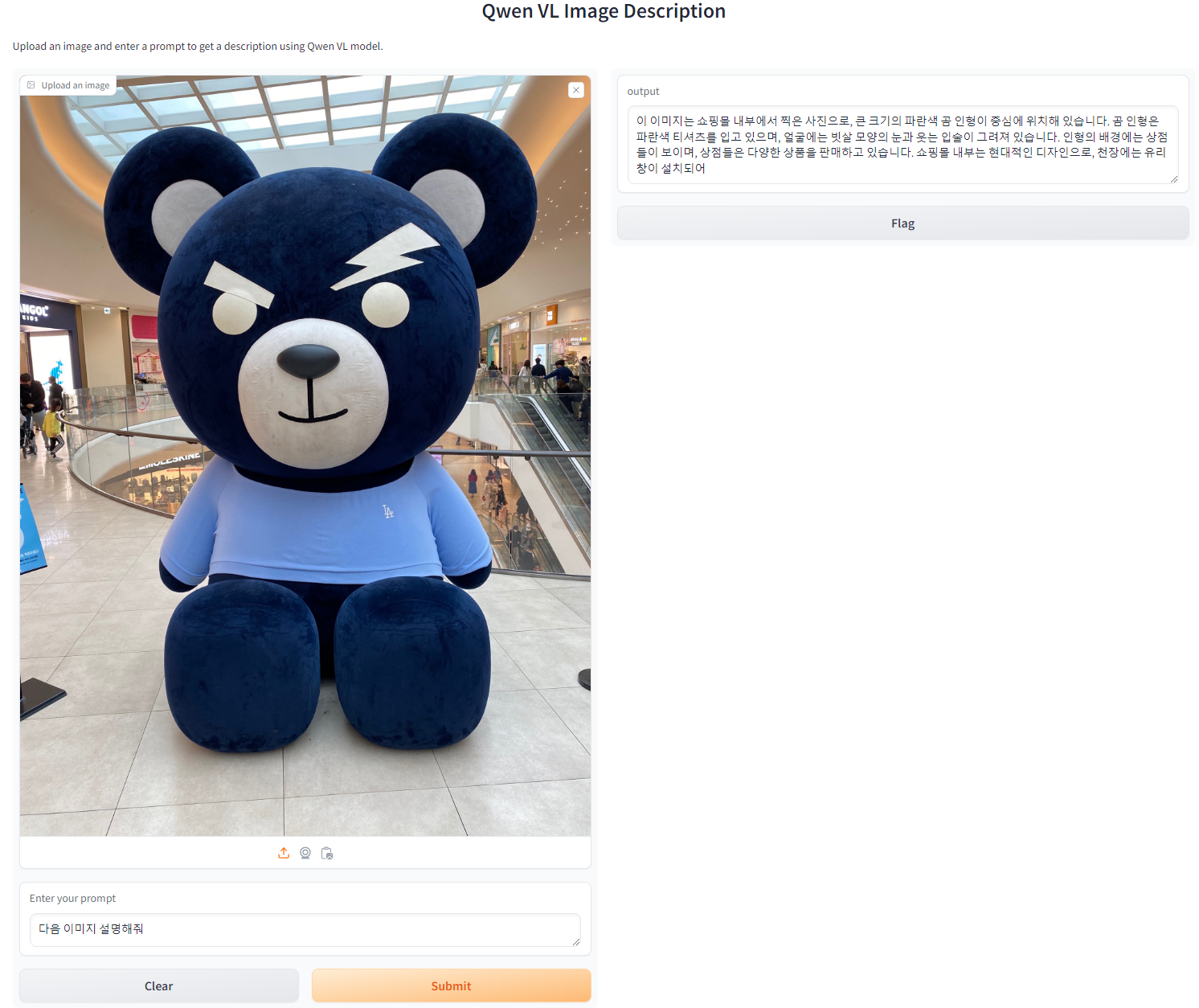
다양한 언어와 질문으로 모델과 소통이 가능한 모습.
Introduction
최근 언어 모델 LLM을 통한 텍스트 생성은 매우 전도유망한 기술이 되었습니다.
사용자의 의도에 맞게 조정된 명령엉를 통해 더욱 향상될 수 있으며, 지능형 비서로서도 큰 잠재력을 가지고 있습니다.
하지만 대부분의 언어 모델들은 순수한 텍스트를 처리하는데만 존재하며 다른 멀티모달리티를 처리하는 것은 부족하여 적용 범위의 큰 한계가 존재합니다.
이를 해결하기 위해 VLM이 개발되어 언어 모델이 시각적 신호를 인식하고 이해할 수 있는 능력을 갖추게 되었습니다.
본 논문에서는 오픈소스 Qwen 시리즈의 최신 버전인 Qwen-VL 시리즈를 공개합니다.
다재다능한 언어-비전 모델 시리즈입니다.
새로운 visual receptor를 도입하여 LLM에 시각적 능력을 부여합니다.
전반적인 모델 아키텍쳐와 입력-출력 인터페이스는 메우 간결하며, 방대한 이미지-텍스트 코퍼스를 기반으로 모델을 최적화하기 위해 3단계 학습 파이프라인을 정교한게 설계했습니다.
사전학습된 모델 체크포인트로, Qwen-VL은 시각적 인식을 이해하여, 주어진 프롬프트에 따라 원하는 응답을 생성할 수 있습니다.
Qwen-VL은 크게 4가지 특징이 존재합니다.
- Leading performance: 다른 VLM과 비교하였을 때 높은 성능을 기록합니다.
- Multi-lingual: 다국어 지원!(한국어 포함)
- Multi-image: 다중 이미지 처리
- Fine-grained visual understanding: 높은 해상도의 입력 크기와 세밀한 코퍼스로 디테일한 시각 요소 이해가 가능합니다.
Methodology
Model Architecture
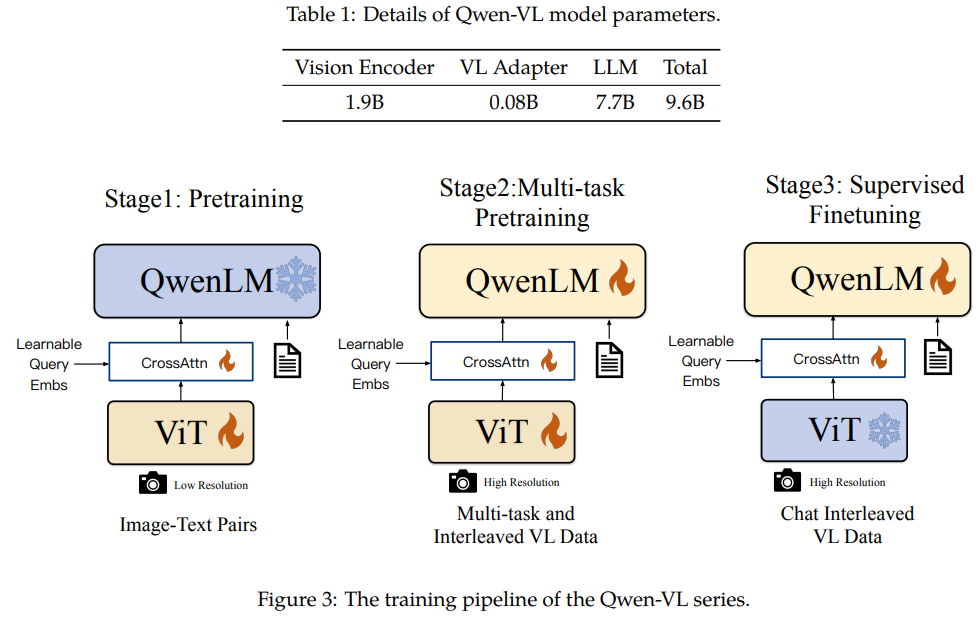
Qwen-VL은 3가지 구성 요소로 이루어져 있습니다.
Large Language Model: Qwen-7B로부터 사전 학습된 가중치로 시작합니다.
Visual Encoder:: Openclip의 ViT-bigG의 초기 가중치를 사용합니다. 학습과 추론 과정 모두 입력 이미지는 특정 해상도로 조정됩니다. visual encoder는 이미지를 14의 스트라이드 패치로 분할하고 특징 집합을 생성합니다.
Position-aware Vision-Language Adapter: 이미지 특징 시퀀스에서 발생하는 효율성 문제를 해결하기 위해 Qwen-VL은 이미지 특징을 압축하는 Position-aware Vision-Language Adapter를 사영합니다.
해당 어댑터는 랜덤으로 single-layer cross-attention module을 사용합니다.
해당 모듈은 학습 가능한 벡터(임베딩)을 쿼리 벡터로 사용하고 visual-encoder에서 생성된 이미지 feature를 키로 사용하여 cross-attention을 수행합니다.
해당 메커니즘은 visual feature sequence를 고정 길이인 256 사이즈로 압축합니다.
Inputs and Outputs
Image Input: 이미지는 visual encoder와 어댑터를 통해 처리되어 고정된 길이의 iamge feature를 생성합니다. 이미지 feature와 text feature의 입력을 구별하기 위해 special token인 를 이미지 feature sequence의 시작과 끝에 추가하여 구별할 수 있게 합니다.
Bounding Box Input and Output: 세밀한 이해와 그라운딩 능력을 강화하기 위해 Qwen-VL은 다양한 데이터가 포함됩니다.
이미지-텍스트와 같이 전통적인 방식외에도 해닥 작업은 지정된 형식으로 영역 설명을 정확히 이행하고 생성할 수 있는 모델의 능력을 요구합니다. 주어진 바운딩 박스에 대해 정규화가 진행되고 (0, 1000) 범위 내에서) 지정된 문자열 형식으로 변환됩니다. 약시 동일하게 탐지된 문자열과 일반 텍스트를 구분하기 위해 스페셜 토큰을 추가합니다. 또한 바운딩 박스에 대한 설명과 문장을 잘 연결하기 위해
Training
Pre-training
사전 학습 단계에서는 대규모+weakly labeled+웹크롤링된 이미지-텍스트 쌍을 사용합니다.
사전 학습 데이터셋은 공개된 데이터셋과 일부 내부 데이터셋으로 구성되었습니다.
데이터를 정제하기 위해 많은 노력을 기울였습니다.
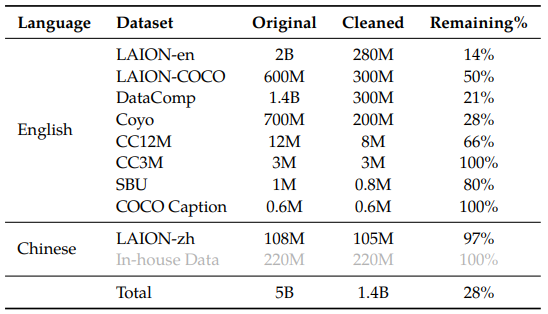
표2에서 알 수 있듯이 50억 개의 이미지-텍스트 쌍을 포함하고 있으며, 정제 후에는 14어 개의 데이터가 남게 되었습니다.
77.3%는 영어, 22.7%는 중국어 데이터입니다.
해당 단계에서는 LLM은 고정하고, visual encoder와 VL adapter만 최적화합니다.
입력 이미지는 224*224 크기로 고정됩니다.
학습 목표는 텍스트 토큰의 cross-entropy를 최소화하는 것입니다.
Multi-task Pre-training
다중 작업을 위한 사전학습을 위해서는 더 큰 입력 해상도의 이미지와 그에 맞는 텍스트 데이터를 사용합니다.
표3에 알 수 있듯이 Qwen-VL을 7개의 작업에 대해 동시에 학습시켰습니다.
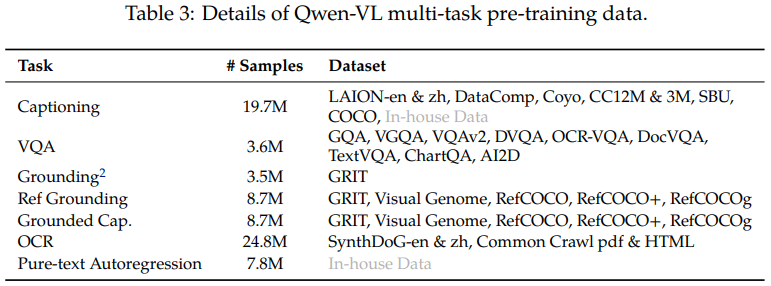
텍스트 중심으로 설계된 작업을 개선하기 위해 PDF와 HTML 형식 데이터를 수집하고, 자연 풍경 배경과 함께 영어와 중국어로 된 합성 OCR 데이터를 생성합니다.
마지막으로 동일한 작업 데이터를 2048 길이의 시퀀스로 묶어 이미지-텍스트 데이터를 간단히 구성합니다.
visual-encoder의 입력 해상도도 224224->448448로 증가시켜 이미지 다운 샘플링의 인한 정보 손실도 줄였습니다.
Supervised Fine-tuning
Qwen-VL 사전 학습 모델을 fine-tuning하여 지시를 따르는 능력과 대화 능력을 향상시 Qwen-VL-Chat 모델을 만들었습니다.
multi-modal instruction tuning data는 주로 캡션 데이터나 LLM 자체 지시를 통해 생성된 대화 데이터에서 나오며 단일 이미지 대화와 추론에만 초점을 맞추고 이미지 내용 이해에 대해 국한됩니다.
Qwen-VL 모델에 localization와 다중 이미지 이해 능력을 포함시키기 위해 manual annotation, model generation, and strategy concatenation을 통해 추가적인 대화 데이터를 구성했습니다.
해당 전략을 통해 모델이 더 넓은 범위의 언어와 질문 유형으로 효과적으로 튜닝될 수 있음을 확인했습니다.
추가적으로 모델의 일반화 성능을 보장하기 위해 훈련 중 멀티모달 및 텍스트 대화 데이터를 혼합했습니다.
Experiment
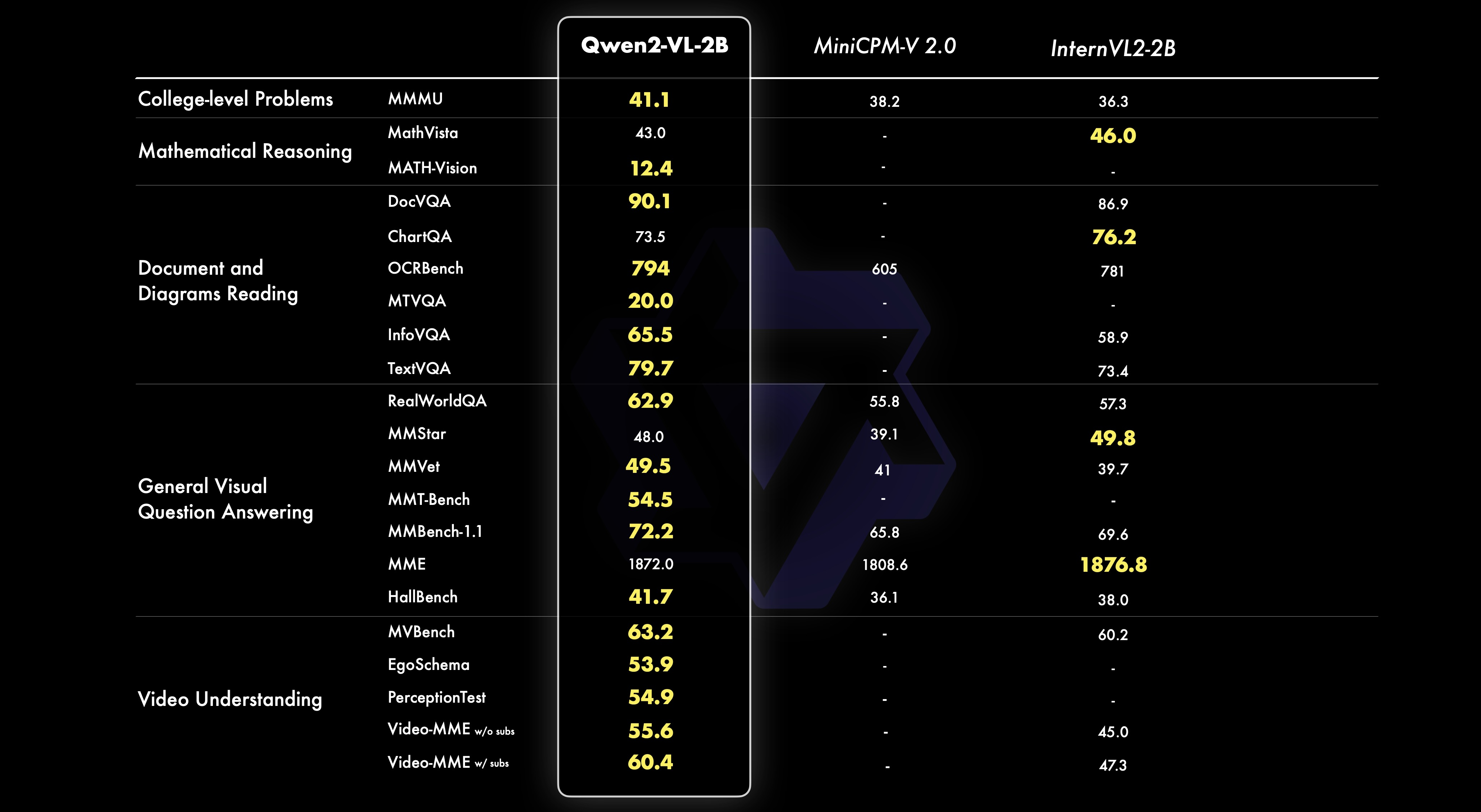
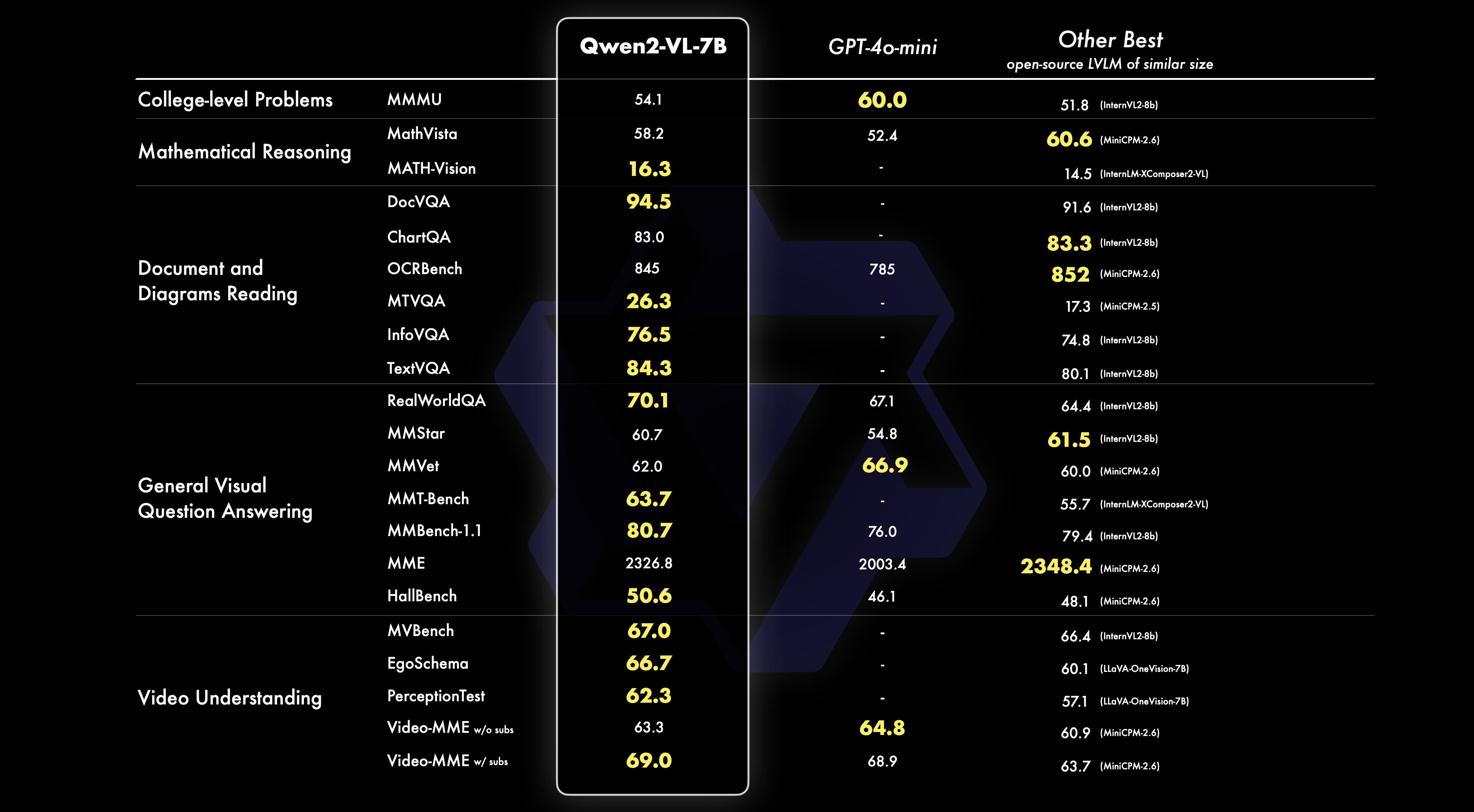
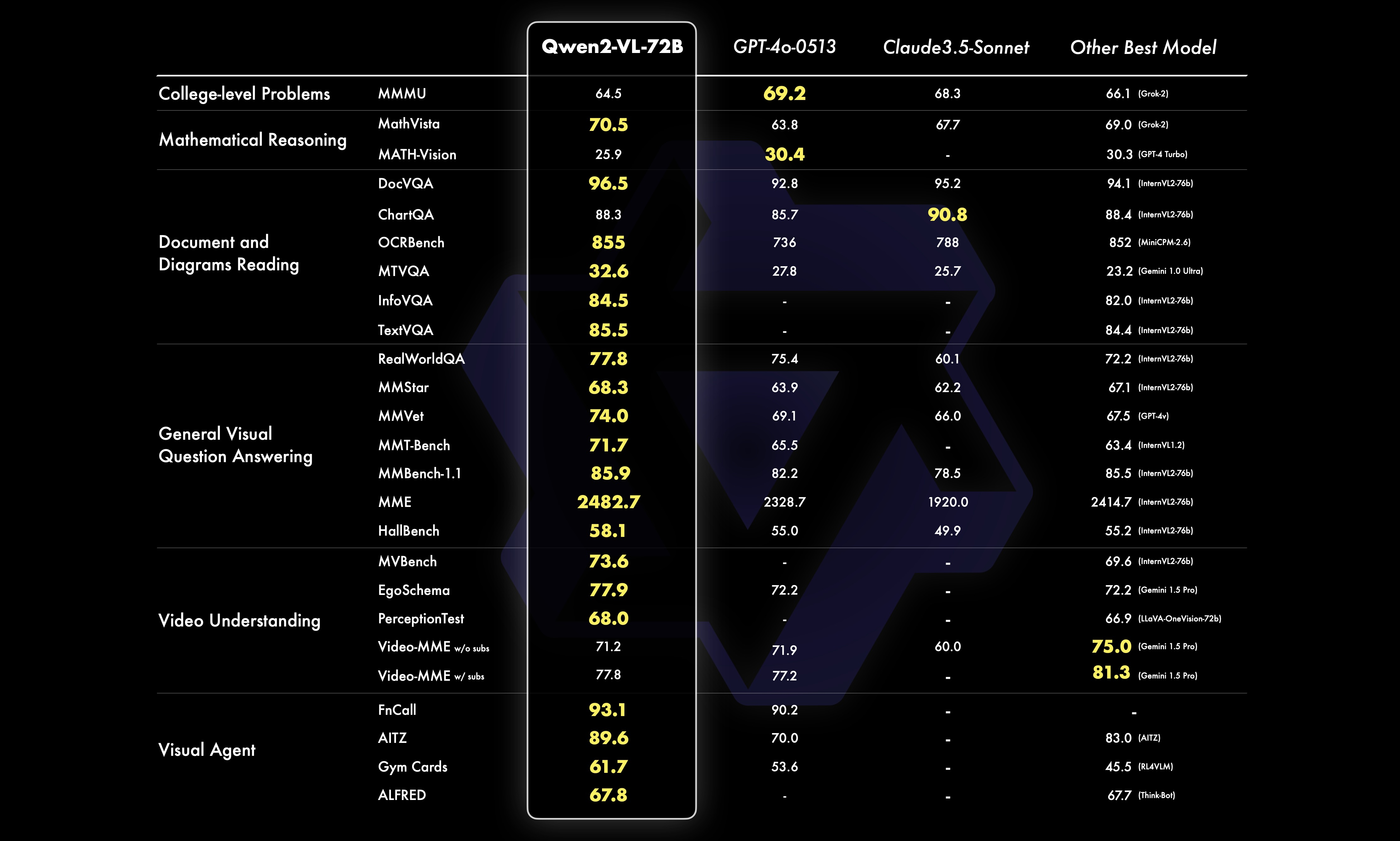
24.08.31 기준으로 2b, 7b의 가중치를 가진 VLM을 공개하였는데 2가지 모델 모두 매우 높은 성능을 기록하고 있고 7b의 경우 GPT-4o-mini의 성능을 넘는 것을 확인할 수 있습니다.
추가적으로 가장 큰 모델인 72b는 GPT-4o의 성능을 넘는 것을 확인할 수 있습니다.
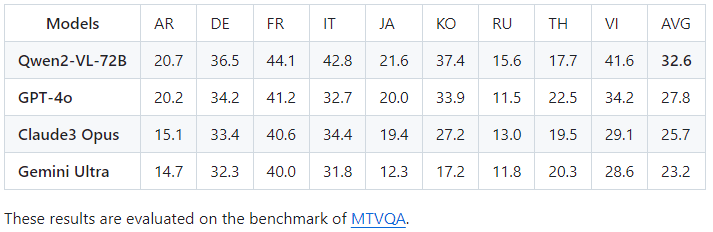
위의 이미지는 다중 언어의 벤치마크의 평균입니다.
오픈 소실 VLM이 성능이 매우 좋지 못해 서비스와 실험에 사용하기 어려웠는데 엄청 높은 성능을 기록하는 것을 확인할 수 있습니다.
