[논문 리뷰] UniBench: Visual Reasoning Requires Rethinking Vision Language Beyond Scaling
Abstract
VLM 학습 방식을 개선하고 확장하기 위한 연구가 많이 진행되고 있습니다.
VLM을 평가하기 위해 많은 벤치마크가 등장하였지만 의미 있는 벤치마크의 부족과 많은 벤치마크에서 오는 비효율성이 문제가 되고 있습니다.
이러한 문제를 해결하고 체계적으로 모델을 평가할 수 있는 UniBench를 소개합니다.
객체 인식, 공간 인식, 카운팅 등과 같은 다양한 능력을 검증할 수 있는 VLM 벤치마크를 통합하였습니다.
공개된 60개의 VLM 모델의 평가를 통해 학습 데이터나 모델의 확장이 VLM의 추론 능력에는 거의 도움이 되지 않는 다는 점을 확인했습니다.
공개된 가장 최신의 모델도 MNIST와 같은 간단한 숫자 인식에 대한 어려움을 겪는 반면 훨씬 더 간단한 네트워크는 쉽게 수행하는 것을 확인할 수 있습니다.
규모의 한계 이후에는 데이터의 품질이나 맞춤 학습이 더 좋은 결과를 낼 수 있음을 확인했습니다.
Introduction
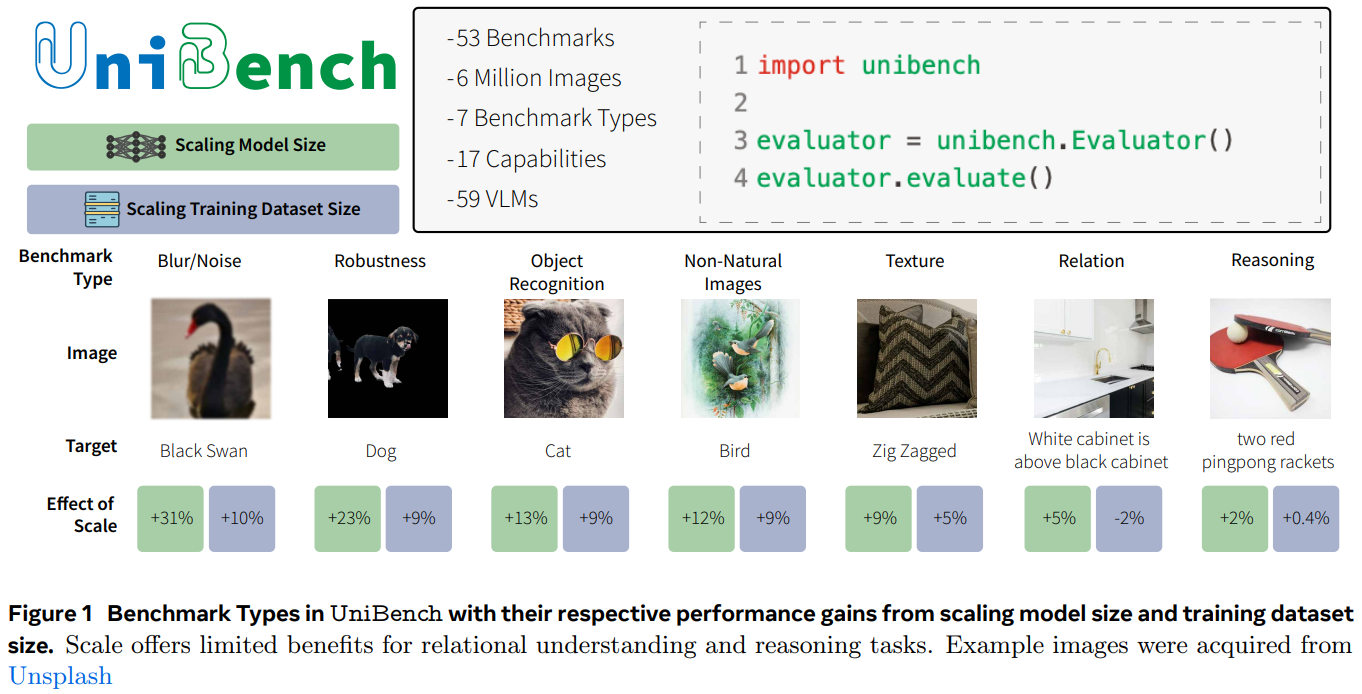
VLM의 발전으로 많은 모델들이 탄생하였고 이에 따라 다양한 벤치마크가 개발되었습니다.
좋은 벤치마크는 좋지만 복잡하고 많은 벤치마크는 평가의 복잡도가 올라가는 결과를 초래했습니다.
파편화된 벤치마크 환경에서 VLM을 객관적으로 평가하는 것은 매우 어려운 과제가 됩니다.
이러한 문제를 해결하기 위해 53개의 VLM 벤치마크를 통합하기위해 친화적인 코드로 구현하였습니다.
다양한 도메인을 다뤄 벤치마크의 일반화 성능도 도모합니다.
또한 벤치마크를 7가지 유형과 17개의 세부 유형으로 나누어 평가 지표를 카테고리화했습니다.
UniBench의 유용성을 입증하기 위해 공개된 60개의 VLM을 평가했습니다.
10억~128억개 사이의 다양한 모델 세트를 체계적으로 비교했습니다.
모델 크기나 데이터셋의 확장은 VLM의 추론 성능에는 별다른 도움이 되지 않는다는 점을 발견했습니다.
다양한 벤치마크 테스트 이후 실무자들에게 몇가지 실용적인 모델도 추천합니다.
예를 들어, Eva ViT-E/14와 같은 대규모 오픈 모델이 범용 VLM으로 적합하며, NegCLIP이 visual-encoder에서 우수한 성능을 보이는 것을 확인했습니다.
UniBench: A comprehensive unified evaluation framework for VLMs
VLMs Considered in UniBench
다양한 형태 59개의 VLM을 평가했습니다.
모델 크기, 아키텍쳐 측면에서 매개변수 수와 CNN 기반인지 Transformer 기반인지에 따라 모델을 분류했습니다.
예를 들어 ResNet은 3,800M의 매개변수+CNN, EVA02 ViT는 43억 개의 매개변수+Transformer의 형태를 가지고 있습니다.
평가 절차: 제로샷을 기반으로 벤치마크 성능을 평가했습니다. 프롬프트에 따라 평균화된 레이블의 표현과 이미지 표현을 대조하여 가장 높은 확률을 가진 클래스를 예측된 클래스로 사용하는 방식입니다.
Benchmark Types
Non-Naural Images: 다양한 비자연적인 이미지에서 모델이 얼마나 잘 처리할 수 있는지 평가합니다.
Object Recognition: 이미지 내 다양한 객체를 정확히 식별하고 분류하는 모델의 능력을 평가합니다.
Reasoning: 객체 간의 관계를 이해하고 공간 추론 및 시각적 입력을 기반으로 논리적 추론을 수행하는 모델의 능력을 테스트합니다.
Robustness: 변형된 이미지나 데이터 변이에 얼마나 강건한지 측정합니다.
Relation: 이미지 내 객체 간의 관계를 이해하고 표현하는 모델의 능력을 평가합니다.
Texture: 이미지 내에서 텍스처를 인식하고 구별하는지 평가합니다. 소재 인식이나 장면 이해와 같은 작업에 필요합니다.
Corruption: 이미지 손상에 대한 다양한 유형의 왜곡(노이즈, 블러, 아티팩트)를 도입합니다. 손상된 이미지의 이해는 실제 환경에서 열악한 환경을 시뮬레이션할 때 필요합니다.
Benchmark Capabilities
Depth Estimation, Pose Detection, and Spatial Understanding:
Medical and Satellite:
Counting and Character Recognition:
Geographic Diversity:
Scene Recognition:
Standard Object Recognition, ImageNet and Challenging ImageNet:
Specific Classification:
Texture Detection:
Rendition:
Corruptions and Natural Transformations:
위의 분류로 세분화하여 벤치마크의 능력을 다양하게 평가할 수 있습니다.
UniBench: a systematic, practical VLM evaluation
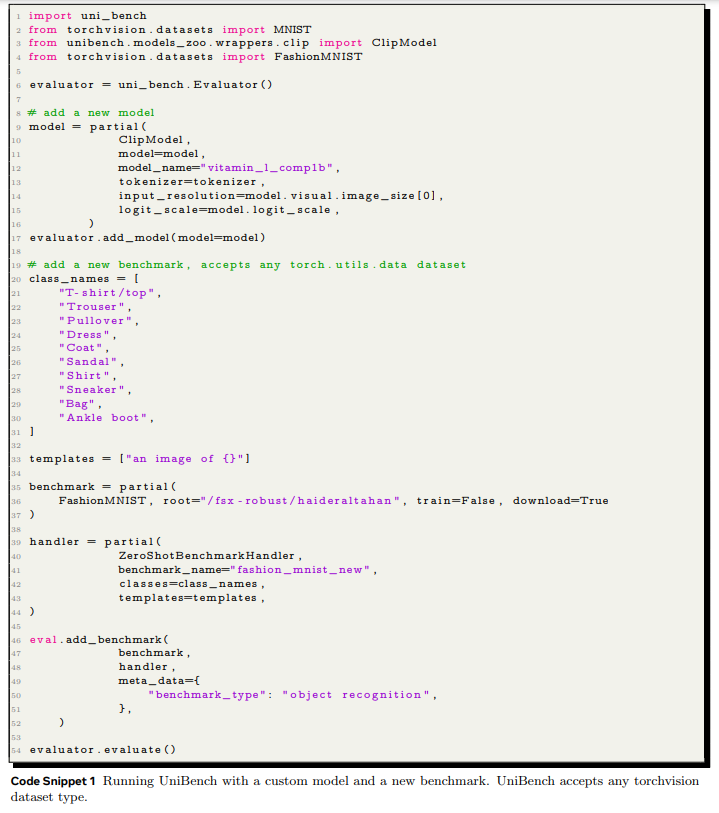
위의 이미지에서 볼 수 있듯이 굉장히 간단한 형식으로 VLM을 평가할 수 있는 것을 알 수 있습니다.
Gauging progress in Vision Language Modeling with UniBench
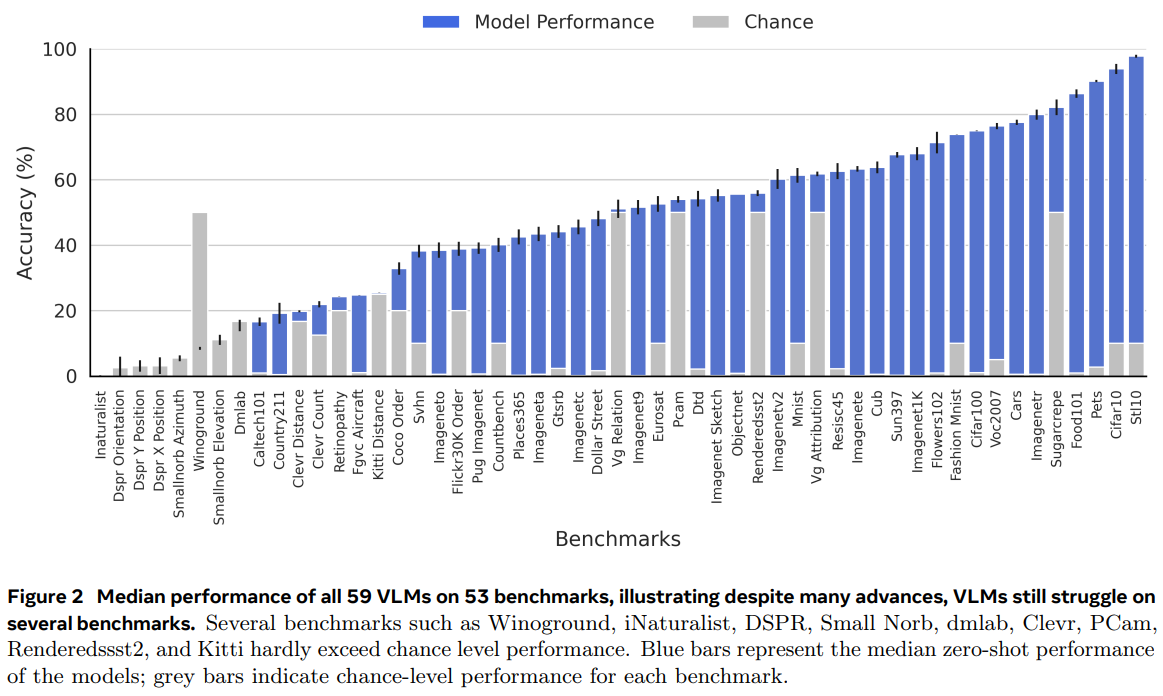
53개의 벤치마크에서 60개의 VLM의 전체 성능을 도출한 결과를 그림2에서 볼 수 있습니다.
VLM이 많은 작업에서 우수한 성과를 보였지만, 일부 작업에서는 성능이 무작위 수준에 가깝거나 그 이하입니다.
Scaling improves many benchmarks, but offers little benefit for reasoning and relations
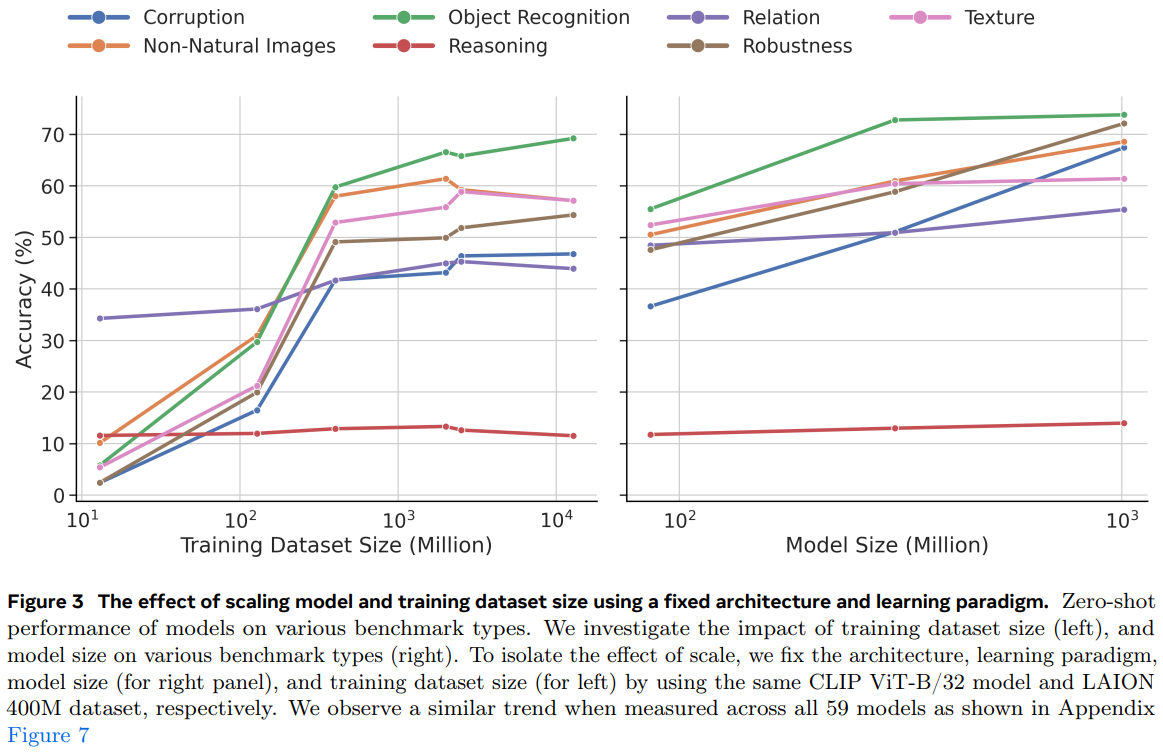
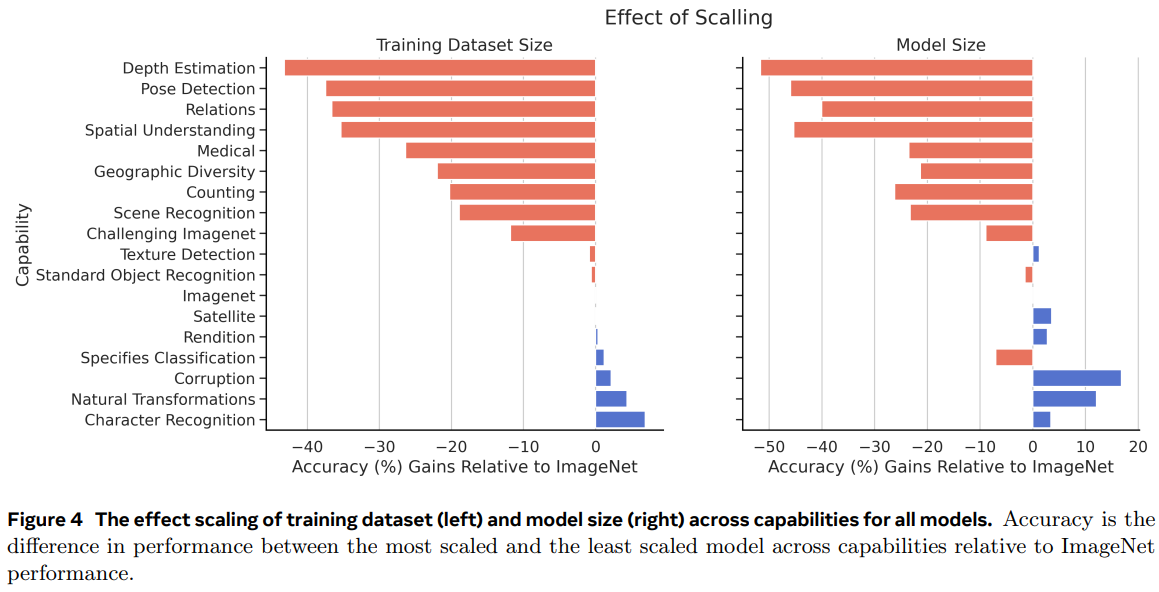
데이터셋 크기의 확장은 많은 작업에서 성능을 향상시키지만 관계 이해와 추론 능력을 평가하는 벤치마크에서는 이러한 경향이 보이지 않습니다.
그림3에서 다른 요인을 통제하고 학습 데이터 크기만 조정한 결과를 확인할 수 있습니다.
데이터셋의 크기를 1,000배를 늘렸지만 관계, 추론 벤치마크의서 성능 변화가 거의 없는 것을 확인할 수 있습니다.
데이터 크기의 확장뿐만 아니라 모델의 크기 확장 역시 관계, 추론 성능의 이점을 제공하지 않습니다.
모델의 크기를 86M에서 10B로 확장했을 때도 다른 성능은 증가하였지만 관계, 추론 성능은 거의 증가하지 않는 것을 확인할 수 있습니다.
A Case Study: Digit Recognition and Counting are notable limitations for VLMs even with the right training data
VLM 모델의 놀라운 점은 비교적 간단한 MNIST, CIFAR-10, CIFAR-100과 같이 전통적으로 간단하다고 여겨지는 벤치마크에서 매우 저조한 성능을 보인다는 점입니다
MNIST에서 저조한 성능은 주목할만 한데, 2 layer MLP도 99%의 정확도를 달성하지만 59개의 VLM은 모두 이보다 성능이 낮았습니다.
여러 변수를 통제하여 예기치 못한 결과를 더 깊게 분석합니다.
VLM confusions go beyond top-1: MNIST의 성능을 분석하기 위해 상위-(2,3,4,5) 정확도를 계산하여 모델이 유사한 숫자를 혼동하는지 분석합니다. 상위-5 정확도(무작위 수준)에서도 VLM은 겨우 90%에 도달하며 성능 저하가 단순한 숫자 혼동에 문제는 아님을 판단할 수 있습니다.
Prompt engineering isn’t enough for good performance: 프롬프트의 문제일 수도 있어 다양하고 상세한 프롬프트로 실험하였으나 여전히 크게 뒤떨어지는 성능을 확인했습니다.
Training data contains ample samples with digit concept: 학습 이미지에 숫자 개념이 부족해서 성능이 떨어졌는지 확인하기 위해 라이온 400M 데이터를 분석하였지만 데이터 부족의 성능 저하의 주된 원인이 아니였습니다.
VLMs struggle on other digit benchmarks: MNIST 데이터 뿐만 아니라 다양한 숫자 벤치마크에서도 어려움을 겪는 것을 확인했습니다.
What contributes to better model performance?
그렇다면 모델의 성능에 직접적인 연관이 있는 요소를 찾아야 합니다.
데이터의 양보단 품질: 데이터가 의미 없이 증가하는 것보다 고품질의 데이터가 증가하는 것이 모델 성능에 더 중요한 역할을 하는 것을 확인할 수 있습니다.
정확한 학습 목표 설정: 학습에서 설정한 정확한 학습 목표는 궁극적으로 다양한 모델의 성능에 중요한 영향을 미치는 것을 확인할 수 있습니다.
Which model should I use?
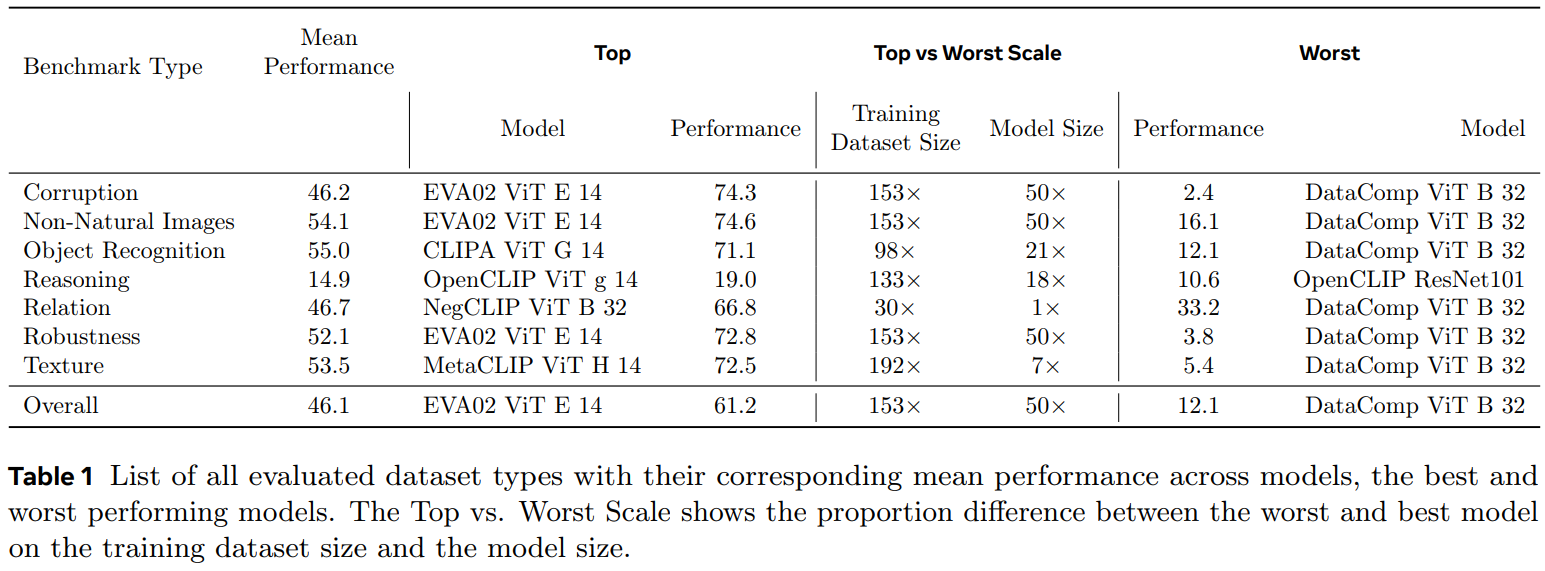
실무자의 사용 목적과 작업의 요구 사항에 따라 적절한 모델을 선택하는 것이 중요하며, 전반적인 성능을 고려한다면 Eva-2 ViT-E/14와 같은 대형 ViT 모델이 좋은 선택일 수 있습니다.
UniBench: A Practical Way Forward for Faster Comprehensive VLM Evaluations
53개의 벤치마크에서 VLM을 평가하는 것이 가장 포괄적인 통찰력을 제공하겠지만 컴퓨팅 요구 사항과 방대한 데이터 분석의 복잡성이 부담이 될 수 있습니다.
평가를 간소화하기 위해 UniBench의 전체 벤치마크 세트를 각 축의 진보를 가장 잘 대표하는 7개의 벤치마크로 압축했습니다
