
Abstract
OmniGen은 이미지 생성에 다양한 작업을 통합하여 처리할 수 있는 Diffusion model입니다.
다른 디퓨전 모델과 달리 Control-Net, IP-Adapter와 같은 추가 모듈 없이도 다양한 조건을 처리할 수 있는 특징을 가집니다.
해당 모델은 크게 3가지 특징을 가집니다.
1. Unification: 텍스트에서 이미지를 생성할 뿐만 아니라 image editing, subject-driven generation, and visual-conditional generation와 같은 생성을 통합하여 할 수 있습니다.
2. Simplicity: OmniGen은 아키텍쳐는 매우 간단하여 추가적인 텍스트 인코더가 필요하지 않습니다.
3. Knowledge Transfer: 통합된 포맷으로 학습되어 OmniGen은 서로 다른 작업 간의 지식을 전이하고 새로운 작업에도 놀라운 효과를 보여줍니다.
Introduction
LLM의 등장으로 다양한 언어 작업에서 인공지능이 활용될 수 있음을 확인했습니다.
이미지 생성에서 LLM 정도의 보편성을 반영하는 모델은 등장하지 않았습니다.
이미지 생성은 매우 뛰어난 성능을 보이는 것을 확인했습니다.
텍스트-이미지 생성에서 최첨단 모델들이 공개되었고 특정 작업에 대한 확장과 최적화를 위해 많은 방법이 제안되었습니다.
Control-Net, T2i-Adapter와 기법은 디퓨전 모델에 조건을 추가하여 이미지를 생성하기 위한 추가 네트워크를 설계합니다.
하지만 이런한 네트워크에도 불구하고 특정 작업에 제한되어 있으며 포괄적인 이미지 생성 능력을 보여주지 않습니다.
텍스트-이미지에서 다양한 이미지 생성 작업을 GPT가 언어 작업을 처리하듯이 유사하게 단일 프레임워크에서 해결할 수 있을까요?
단일 프레임워크에서 가능하다면 추가 모듈을 훈련할 필요가 적을 것입니다.
OmniGen은 추가 인코더 없이 VAE와 트랜스포머 모델의 두 가지 주요 구성 요소만으로 구성된 간결한 구조를 가지고 있습니다.
통합 모델을 훈련하기 위해 다양한 작업을 하나의 형식으로 통합한 최초의 대규모 이미지 생성용 데이터셋인 X2I를 구축했습니다.
여러 벤치마크를 통해 제안한 방식이 경쟁력 있는 텍스트-이미지 생성 능력을 가지고 있음을 입증합니다.
OmniGen의 설계는 다양한 시나리오에서 강력한 transfer learning이 가능하여 새로운 작업 및 도메인을 처리할 수 있는 새로운 능력을 발휘할 수 있게 됩니다.
3가지의 큰 기여가 있습니다.
- OmniGen은 여러 도메인에서 뛰어난 성능을 기록하는 이미지 생성 모델입니다.
- "anything to image"를 의미하는 X2I라는 포괄적인 이미지 생성 데이터셋을 구축했습니다.
- 구축한 데이터셋에서 통합 훈련을 통해 OmniGen은 학습한 지식을 바탕으로 보지 못한 작업 및 도메인을 해결할 수 있으며 새로운 능력을 발휘할 수 있습니다.
OmniGen
Model Design
Principles:
현재의 디퓨전 모델은 일반적인 텍스트-이미지 작업게 한정되어 있으며 더 넓은 범위의 이미지 생성은 수행할 수 없습니다.
application을 위해서는 사용자들은 추가 네트워크 구조를 설계하고 통합하고 이는 매우 번거로운 작업입니다.
추가 네트워크 작업은 다른 작업에 사용할 수 없다는 단점도 존재합니다.
이를 해결하기 위해 OmniGen의 설계 원칙은 다음과 같습니다.
- 보편성: 다양한 작업에 대해 어떠한 형태의 이미지나 텍스트를 수용할 것
- 간결성: 지나치게 복잡한 구조를 피할 것
Network Architecture:
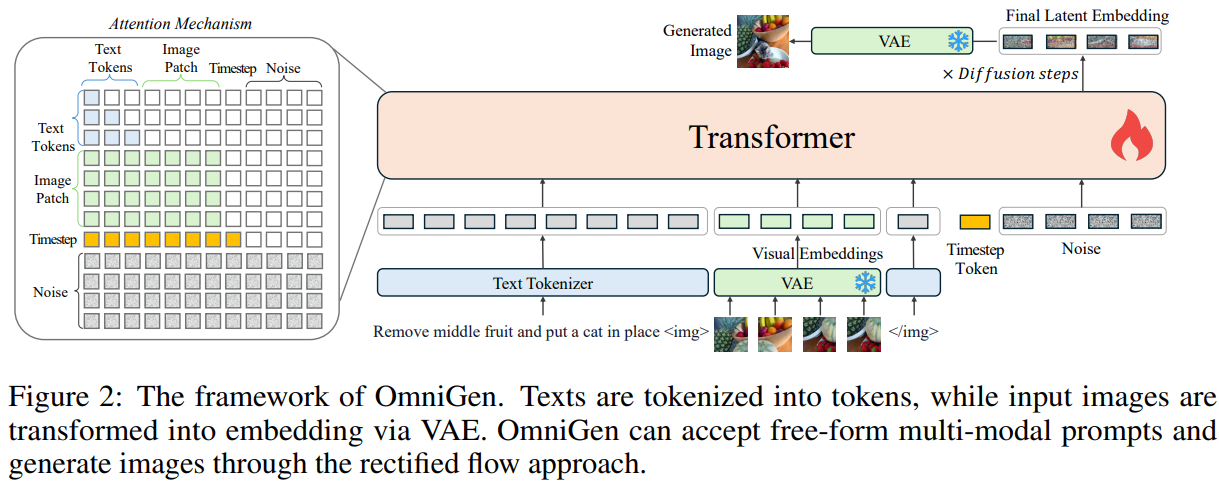
그림 2에서 볼 수 있듯이 OmniGen 프레임워크는 VAE와 사전 학습된 트랜스포머 모델로 구성된 아키텍처를 채택합니다.
VAE는 visual feature를 추출하고 transformer는 입력 조건에 따라 이미지를 생성합니다.
본 논문에서 제안한 아키텍쳐는 SDXL의 VAE를 고정하여 훈련 중 사용하며, 트랜스포머는 Phi-3을 이용하여 학습에 사용합니다.
기존의 디퓨전 모델들이 조건 정보를 학습할 수 있는 추가 인코더를 요구하는 것과 달리 OminGen은 조건 정보를 직접 인코딩하여 바로 사용하기 때문에 파이프라인을 크게 단순화합니다.
Input Format:
다양한 이미지와 텍스트를 입력으로 처리할 수 있습니다.
Phi-3 토크나이저를 사용하여 자연어 그대로 입력을 받을 수 있습니다.
이미지는 linear layer가 있는 VAE를 사용하여 latent feature를 추출한 후
이를 평탄화하여 latent space에서 각 패치를 linear embedding하여 시각적 특징을 담고 있는 토큰 시퀀스로 변환합니다.
Visual token에 대해 frequency-based positional embeddings을 적용하고, 다양한 종횡비의 이미지를 처리하기 위해 SD3와 동일한 방법을 사용합니다.
각 이미지 시퀀스는 텍스트 토큰 시퀀스에 삽입하기 전에 두 개의 특별 토큰("", "")으로 묶어 사용합니다..
마지막으로 입력 시퀀스의 끝에 타임스텝 임베딩을 추가합니다.
Attention Mechanism:
텍스트는 개별 토큰으로 분해되어 모델링될 수 있는 반면, 이미지는 전체로 모델링 되어야 한다고 주장합니다.
common causal attention mechanism in LLM -> bidirectional attention.
그림 2에 왼쪽에서 볼 수 있듯이 2차원으로 구성된 토큰과 이미지 패치들이 양방향 어텐션을 적용한 것을 볼 수 있습니다.
해당 방식은 동일한 이미지 내의 다른 패치에 주의를 기울일 수 있으며, 각 이미지는 이전에 나타난 다른 이미지 또는 텍스트 시퀀스에만 주의를 기울일 수 있습니다.
Inference:
추론 과정에서는 가우시안 노이즈를 임의로 샘플링한 후 목표를 예측하는 방식을 사용하며, 여러 단계를 반복하여 final latent representation를 얻습니다.
VAE 사용하여 latent representation을 이미지로 디코딩하여 생성합니다.
기본 추론 단계는 50단계로 설정되어 있습니다.
Training Strategy
Train objective.
rectified flow를 사용하여 모델의 파라미터를 최적화합니다.
DDPM과는 달리 flow matching은 노이즈와 데이터를 직선으로 선형 보간하여 forward process를 수행합니다.
단계 t에서 xt는 다음과 같이 정의됩니다:
t =
여기서 는 원본 데이터이며, 는 가우시안 노이즈입니다.
모델은 노이즈가 있는 데이터 t, 시간 단계 t 및 조건 정보 c를 주어졌을 때 목표 속도를 직접 회귀하도록 훈련됩니다.
아래의 식을 따르고 있습니다:
image editing task의 목적은 주어진 이미지의 영역에서 편집이 필요한 부분은 수정하고 그렇지 않은 부분은 변경하지 않는 것입니다.
수정이 필요한 부분의 영역이 상대적으로 적기 때문에 모델은 입력 이미지를 그대로 출력하게 되게 학습이 될 수 있습니다.
이러한 현상을 완화하기 위해 변경이 필요한 부분의 Loss를 증폭시킵니다.
입력 이미지 x'와 목표 이미지 x의 잠재 표현에 따라 각 영역의 손실 가중치를 계산합니다:
Training Pipeline.
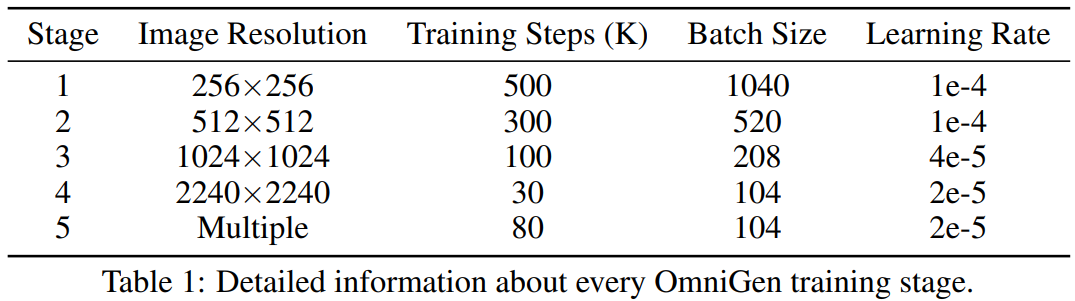
이미지의 해상도를 점진적으로 증가시킵니다.
낮은 해상도의 이미지는 학습 효율성을 증가시키고 높은 해상도의 이미지는 생성된 이미지의 품질을 향상시킬 수 있습니다.
X2I Dataset

이미지 생성을 위한 데이터를 구축하는 것은 매우 힘든 일입니다.
따라서 대규모의 다양한 이미지 데이터를 손쉽게 이용할 수 없는 상황입니다.
본 연구에서는 대규모 통합 이미지 생성 데이터셋을 구축했으며 이를 "X2I Dataset"으로 호칭합니다.
약 10억 장의 이미지로 구성되어 있습니다.
Text to Image
다양한 출처의 오픈소스 이미지 데이터셋을 이용하여 데이터셋을 구축합니다.
해당 데이터셋은 양은 방대하지만 품질은 그렇지 않습니다.
훈련 초기 단계에서는 광범위한 이미지-텍스트 매칭 관계와 다양한 지식을 학습하기 위해 이를 사용합니다.
3단계 학습 이후에는 고품질 이미지 1600만 장을 활용하여 생성된 이미지의 품질을 향상시킵니다.
Results



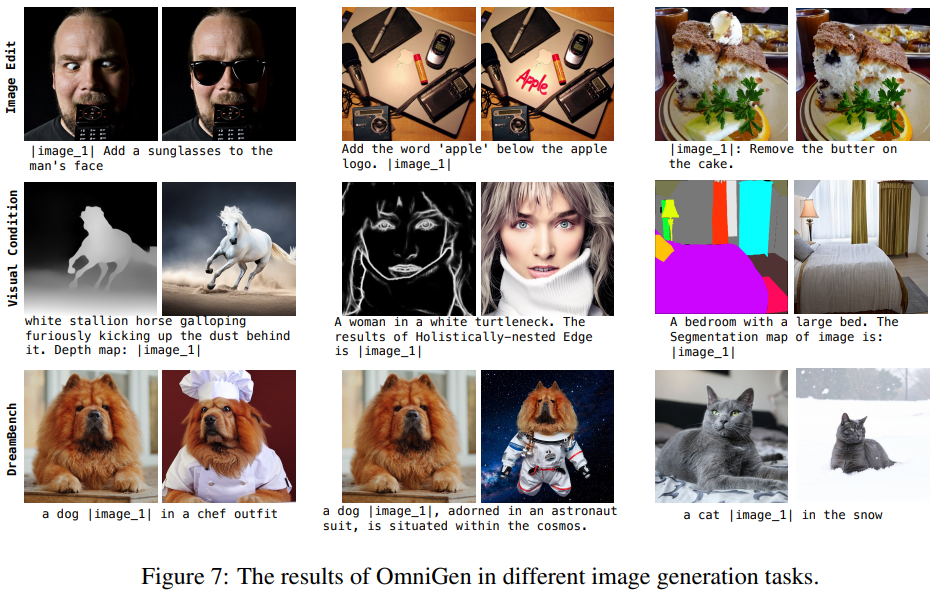
다양한 이미지 테스크에서 높은 퀄리티를 보이는 것을 확인할 수 있습니다.
