Abstract
오픈소스 MLLM의 발전은 주로 모델의 기초 성능 개선에 초점이 맞춰져 있어 인간의 선호도를 반영한 alignment 향상은 아직 부족한 상태입니다.
이 논문에서는 이러한 문제를 해결하기 위해 『OmniAlign-V』라는 새로운 데이터셋을 제안합니다.
이 데이터셋은 총 20만 개의 고품질 학습 샘플을 포함하고 있으며 다양한 이미지, 복잡한 질문, 여러 형태의 응답 형식을 담고 있어 멀티모달 대규모 언어 모델이 인간의 선호도와 더 잘 일치하도록 학습하는 데 도움을 줍니다.
더불어 논문에서는 『MM-AlignBench』라는 새로운 벤치마크를 소개합니다. 이 벤치마크는 인간이 annotate한 평가 기준으로, MLLM 모델들이 인간의 가치와 얼마나 잘 정렬되어 있는지를 측정하기 위해 설계되었습니다.
실험 결과에 따르면, OmniAlign-V 데이터셋을 활용하여 SFT나 DPO를 통해 멀티모달 대규모 언어 모델을 미세조정하면 다음과 같은 효과가 나타납니다.
- 인간 선호도 alignment가 크게 향상됩니다.
- 기존의 일반적인 VQA 벤치마크에서도 성능이 유지되거나 오히려 개선되어, 모델의 본래 가진 기초적 능력 역시 보존됩니다.
OmniAlign-V 데이터셋과 MM-AlignBench 벤치마크의 도입을 통해, 멀티모달 대규모 언어 모델이 보다 인간의 선호와 가치에 맞춰 발전할 수 있음을 확인하였습니다.
Introduntion
LLM의 급속한 발전과 함, MLLM 역시 괄목할만한 향상을 보이고 있습니다다.
대부분의 오픈소스 MLLM은 기존에 훈련된 LLM에 Vision Encoder를 연결한 뒤 vision instruction tuning을 수행하도록 개발됩니다.
그러나 기존의 시각 지시학습 데이터셋과 다중 모달 평가 벤치마크는 주로 객체 인식이나 광학 문자 인식(OCR)과 같은 기초적인 능력 평가에 초점이 맞춰져 있어, human preference alignment에 대해서는 거의 관심을 기울이지 않았습니다.
오픈소스 MLLM이 이러한 기본적인 능력에 대한 객관적인 지표에서는 독점 모델과 비슷한 성능을 달성함에도 불구하고 인간의 선호와의 일치성 측면에서는 상당한 성능 저하를 보이고, 이는 멀티모달 대화 형태의 상호작용에서의 사용자 경험에 부정적인 영향을 미친다는 것을 확인했습니다.
본 연구에서는 MLLM에서 나타나는 인간 선호도 정렬 저하를 정량적으로 분석하기 위한 예비적 조사를 수행하였습니다.
텍스트만을 사용하는 주관적 평가 벤치마크에서의 실험 결과, MLLM이 해당 LLM보다 인간 선호도 정렬 성능이 현저히 떨어짐을 확인하였습니다.
이러한 현상은 MLLM이 시각 지시학습 과정에서 "catastrophic forgetting"을 겪기 때문일 가능성이 있습니다.
이를 바탕으로, 멀티모달과 텍스트 전용 SFT 데이터를 결합하여 학습하는 방식을 시도하였으나, 이 접근법은 인간 선호도 정렬 성능을 향상시키지 못했을 뿐 아니라, MLLM의 기초적 다중 모달 능력에도 부정적인 영향을 주었습니다.
이러한 결과는 인간 선호 정렬 성능을 개선하기 위해서는 특화된 멀티모달 지시학습 데이터셋 개발이 필수적임을 시사합니다.
기존의 다중 모달 지시학습 데이터셋은 대개 기초적 능력 평가를 위주로 구성되어 있어, 언어 패턴이 단순하고 응답 형태도 균일합니다.
본 연구는 인간 선호도 정렬 성능 향상을 위해 효과적인 멀티모달 데이터셋이 갖추어야 할 주요 특징으로 다음을 제시합니다.
- 개방형 질문 (open-ended questions)
- 다양한 주제 범위(broad topic coverage)
- 다양하고 유연한 응답 형식(다양한 길이와 스타일)
- 지시에 대한 엄격한 준수(strict adherence to instructions)
이 원칙으로 본 논문에서는 OmniAlign-V 라는 데이터셋을 구축하였습니다.
OmniAlign-V는 자연 이미지뿐 아니라 포스터나 차트와 같은 인포그래픽도 포함하고 있으며, 자연 이미지 중에서도 의미적으로 풍부한 이미지를 선별하는 새로운 기법을 개발하여 적용하였습니다.
task의 관점에서도 복잡한 지식 기반 질의응답(Knowledge-based QA), 창의적 과제, 추론 과제 등을 다양한 이미지 유형에 맞게 설계하였습니다.
또한 각 과제 유형별로 다양한 하위 과제를 포함하고, 최신의 MLLM을 활용하여 양질의 다양한 응답을 확보하였습니다.
최종적으로 OmniAlign-V는 약 20만 개의 다중 모달 지시학습 샘플로 구성되어 있으며, 기존의 데이터셋과 뚜렷이 다른 데이터 분포 특성을 보입니다.
OmniAlign-V를 활용하여 MLLM의 인간 선호도 정렬 성능을 강화하는 다양한 실험을 진행하였습니다.
LLaVA-NeXT 구조에 OmniAlign-V를 통합하여 InternLM2.5-7B 및 Qwen2.5-32B 모델로 학습한 결과, 다양한 강력한 LLM 기반 인코더( InternLM2.5, Qwen2.5)에 걸쳐 인간 선호도 정렬 성능이 현저히 개선되었습니다.
나아가 MMMU(Yue et al., 2023) 또는 OCRBench(Liu et al., 2023e)와 같은 VQA 벤치마크에서도 OmniAlign-V로 학습된 MLLM은 기존 모델과 유사하거나 우수한 성능을 나타냈습니다.
SFT 외에도 OmniAlign-V를 DPO(Direct Preference Optimization)에 활용하였을 때도, 같은 데이터로 학습한 기존 모델 대비 추가적인 성능 향상을 보였습니다.
특히 Qwen2.5-32B 기반의 LLaVA-Next 모델은 SFT와 DPO 학습 과정을 거쳐, 방대한 독점 데이터로 학습한 현존 최고 성능 모델인 Qwen2VL-72B(Chen et al., 2024b)를 능가하였습니다.
연구 과정에서 기존의 다중 모달 인간 선호도 벤치마크가 이미지 출처 다양성 부족, 질문 반복성, 명확성 부족 등의 한계를 갖고 있음을 관찰하였습니다.
이를 해결하기 위해 본 논문에서는 인간 평가자들이 신중하게 작성한 252개의 고품질 샘플로 구성된 새로운 벤치마크인 MM-AlignBench를 소개합니다.
MM-AlignBench는 이미지 출처의 다양성을 높이고 질문의 명확성과 독창성을 갖추었으며, MLLM의 인간 선호도 정렬 성능을 포괄적이고 세밀하게 평가할 수 있습니다.
MM-AlignBench와 함께 기존의 MLLM 인간 선호도 벤치마크를 활용하여 전체 연구 과정에서 평가를 수행하였습니다.
본 논문의 주요 기여는 다음과 같습니다.
- MLLM의 인간 선호도 정렬 성능 저하를 심층적으로 조사하고 텍스트 전용 및 다중 모달 지시학습 데이터의 영향을 분석하였습니다다.
- 개방적이고 포괄적인 다중 모달 SFT 데이터셋인 OmniAlign-V 및 DPO 용도에 맞춘 OmniAlign-V-DPO를 제안하고, 이를 통해 인간 선호도 정렬 성능이 유의미하게 향상됨을 실험적으로 입증하였습니다.
- 인간 평가자들이 작성한 고품질의 샘플로 이루어진 MM-AlignBench를 개발하여 MLLM의 인간 선호 정렬 성능을 체계적으로 평가할 수 있도록 하였습니다.
Human Alignment of MLLMs: The Preliminary Study
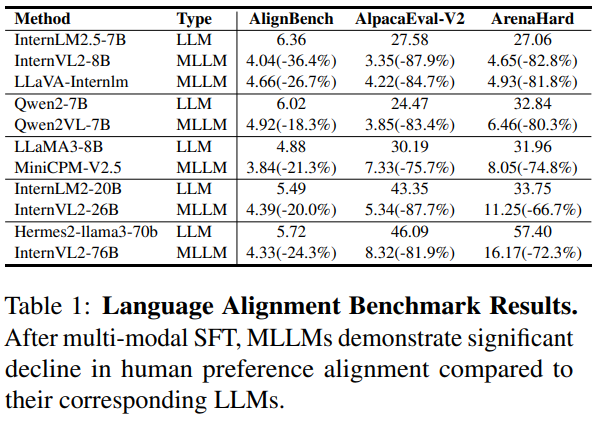
다양한 이미지 관련 질문을 처리할 때 최신 오픈소스 MLLM들은 특정 인식 작업에서는 우수한 성능을 보이지만 GPT-4o에 비해 인간 선호도와의 정합성(alignment)이 크게 떨어지는 현상이 나타납니다.
우리는 이러한 멀티모달 정합성 감소가 멀티모달 Supervised Fine-Tuning, SFT을 거친 이후 언어 모델의 성능 저하 때문일 수 있다고 가설을 세웠습니다.
이 가설을 검증하기 위해, 최신 MLLM 모델들을 텍스트만으로 이루어진 인간 선호 정합성 벤치마크에 대해 평가하였습니다.
또한 InternLM-2.5-7B 모델을 기반으로 LLaVA-Next-778k 데이터셋을 이용하여 미세조정한 LLaVA 기준 모델을 추가로 구축하여 평가하였습니다.
표1(Tab.1)에서 볼 수 있듯이, 멀티모달 지도미세조정 이후 텍스트 기반의 다양한 질문에 대한 언어모델의 대응 능력이 뚜렷하게 감소하였습니다.
이러한 성능 감소 현상은 (1) 멀티모달 미세조정 단계에서 텍스트 전용 학습 샘플의 양이나 질이 부족했거나, (2) 기존 VQA 데이터셋에서 유래된 멀티모달 미세조정 데이터가 지나치게 단순한 스타일로 구성되어 있기 때문일 수 있다고 생각합니다.
첫 번째 요인이 멀티모달 정합성에 미치는 영향을 평가하기 위해 우리는 멀티모달 지도미세조정에 쓰이는 텍스트 전용 데이터의 역할을 자세히 조사했습니다.
LLaVA-Next-778K 데이터셋에는 약 4만 개의 텍스트로만 구성된 샘플이 포함되어 있는데 이는 ShareGPT에서 얻은 것으로 비교적 구식이며 질적으로 떨어지는 데이터셋입니다.
인간과의 정합성을 개선하기 위해 우리는 이 데이터를 더 고품질의 데이터로 대체하고 그 비율을 증가시키는 실험을 수행하였습니다.
구체적으로, Magpie-Llama3.3 및 Condor라는 두 가지 고품질 언어 SFT 데이터셋에서 각각 4만 개와 8만 개의 샘플을 추출해 원래의 텍스트 데이터를 대체했습니다.
그리고 이렇게 다른 데이터 혼합으로 미세조정한 모델을 대상으로 텍스트 전용 벤치마크뿐만 아니라 WildVision 같은 인간 선호 정합성 평가를 위한 멀티모달 벤치마크 및 OpenVLM 리더보드에 속한 다양한 기초적인 멀티모달 능력 평가용 벤치마크를 통해 성능을 측정하였습니다.
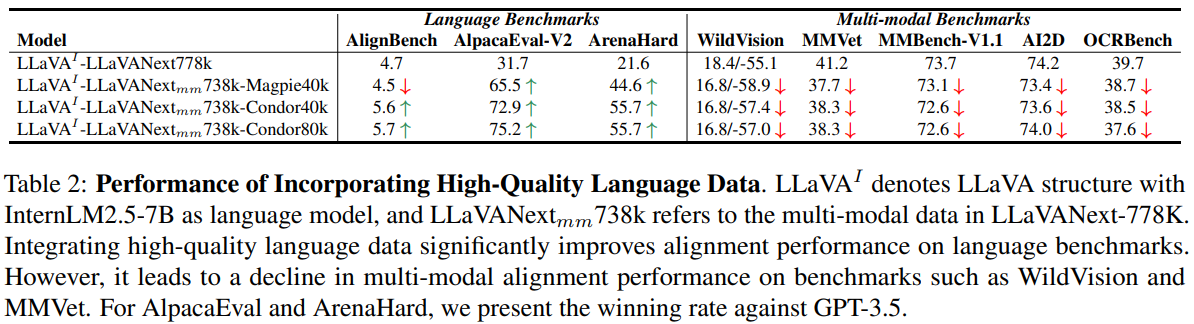
실험 결과(표2)는 몇 가지 중요한 발견을 제공합니다. 고품질 텍스트 전용 데이터를 활용해 미세조정한 멀티모달 언어모델들은 텍스트 전용 인간 선호도 벤치마크에서는 상당한 성능 향상을 보였지만 예상과 달리 멀티모달 정합성 벤치마크 및 일반적인 VQA 성능 평가에서는 오히려 성능이 저하되는 양상이 관찰되었습니다.
이는 직관과는 반대로 텍스트 기반의 언어적 정합성 능력이 곧바로 멀티모달 정합성 능력으로 연결되지 않음을 시사합니다.
따라서 우리는 고품질의 멀티모달 인간 정합 데이터가 MLLM의 멀티모달 상황에서의 인간 선호도 정합성을 높이는 데 필수적이라는 결론을 제시합니다.
OmniAlign-V
현재의 MLLM을 위한 instruction tuning 데이터셋은 주로 인식(perception), 광학문자 인식(OCR), 수학적 추론 등과 같은 기본적인 능력을 향상시키는 데 초점을 맞추고 있습니다.
이러한 데이터셋들은 일반적으로 간단하고 짧은 질문과 답변 쌍으로 구성되어 있어 인간의 선호와 실제 상호작용의 복잡성을 제대로 반영하지 못합니다(그림 5 참고).
우리는 멀티모달 훈련 데이터가 다음과 같은 특성을 갖춰야 한다고 제안합니다:
(1) 개방적이고, 다양하며, 창의적인 질문으로, 학제간 지식을 필요로 함.
(2) 포괄적이고 지식이 풍부한 응답
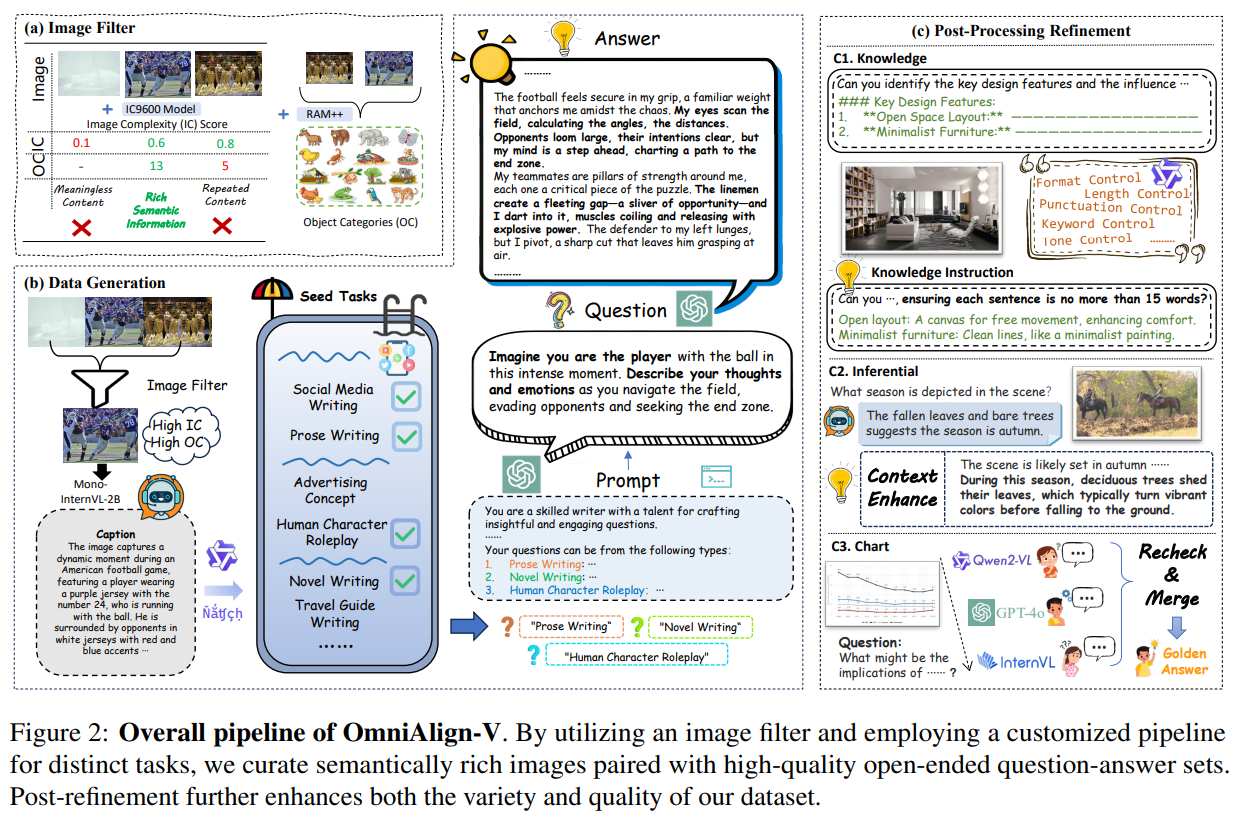
우리는 인간의 선호에 부합하는 높은 품질의 멀티모달 훈련 데이터를 생성하는 새로운 데이터 합성 파이프라인을 개발하여 OmniAlign-V를 제작하였습니다.

Task Taxonomy: A Big Picture
이미지 콘텐츠는 멀티모달 훈련 데이터를 구성하는 데 핵심적인 역할을 합니다.
데이터의 포괄적인 범위를 보장하기 위해 우리는 이미지를 크게 두 가지 범주로 분류한다:
자연 이미지(natural images)와 인포그래픽 이미지(infographic images).
데이터 합성 파이프라인은 먼저 입력된 이미지가 자연 이미지(현실 세계의 장면을 촬영한 이미지)인지 또는 인포그래픽 이미지(정보 전달을 위해 사람이 만든 이미지)인지 판단합니다.
이 분류에 따라 서로 다른 비전-언어 작업이 부여된다.
자연 이미지의 경우, 지식(Knowledge), 추론(Inferential), 창작(Creation)이라는 세 가지 주요 작업을 정의하고, 각각은 포괄적이고 논리적으로 추론된 답변을 요구하는 다양하고 복잡한 질문 형식을 사용합니다.
이러한 작업은 모델이 현실 세계 장면을 효과적으로 해석할 수 있도록 돕습니다.
인포그래픽 이미지의 경우, 콘텐츠가 다양하므로 예술(Arts), 차트(Charts), 다이어그램(Diagrams), 포스터(Posters)와 같이 복잡하고 도전적인 질문을 유발하는 네 가지 주요 유형을 정의하였습니다.
이 범주들은 추상적이고 세부적인 요소를 포함하는 인간이 만든 시각자료에 대한 깊은 이해를 요구합니다.
Image Selection Strategy
자연 이미지의 경우 풍부한 의미론적 콘텐츠가 보다 포괄적이고 통찰력 있는 QA 쌍을 유도합니다.
훈련 데이터의 품질을 향상시키기 위해 다양한 출처에서 의미적으로 풍부한 이미지를 선택하는 파이프라인을 개발했습니다.
이 파이프라인은 두 가지 주요 단계로 구성된다.
먼저, 이미지 복잡도(IC)를 평가하는 모델인 IC9600을 사용해 각 이미지에 IC 점수를 할당합니다.
객체가 적거나 배경이 단순하고 균일해 의미가 적은 이미지는 IC 점수가 낮아 제외됩니다.
IC9600은 저복잡도 이미지를 효과적으로 필터링하지만, 높은 IC 점수만으로는 의미론적 풍부성을 보장하지 않습니다.
예를 들어 텐트가 가득한 이미지는 높은 IC 점수를 받을 수 있지만, 멀티모달 훈련을 위한 의미 정보가 부족할 수 있습니다.
이미지 선정을 보다 세분화하기 위해, Recognize Anything 모델을 사용하여 이미지 내 객체를 식별하고, 복잡성은 높지만 의미 있는 콘텐츠가 부족한 이미지를 걸러냅니다.
이 두 단계 접근법으로 복잡하면서도 의미론적으로 풍부한 이미지를 정확히 선택할 수 있다.
Data Generation Pipeline
SFT QA 생성
SFT QA 쌍 생성 프로세스가 그림 2(b)에 요약되어 있습니다.
자연 이미지 관련 비전-언어 작업(지식, 창작, 추론)의 경우, CC-3M, Flickr30k, GQA에서 의미론적으로 풍부한 이미지를 필터링하는 이미지 선택 전략을 먼저 적용합니다.
인포그래픽 이미지 작업의 경우 기존 여러 출처에서 이미지를 수집합니다.
지식 및 추론 작업
예비 실험을 통해 GPT-4o가 잘 설계된 few-shot 프롬프트를 제공할 경우 다양한 콘텐츠 관련 질문을 생성할 수 있음을 발견했습니다.
따라서 각 작업 범주별로 포괄적 지침과 선정된 few-shot 예시를 포함한 단일 프롬프트를 신중히 설계하여 다양한 이미지에서 GPT-4o를 통해 QA쌍을 생성하였습니다.
창작 작업
단일 프롬프트로는 창작 질문의 다양성이 부족하므로, Condor에서 영감을 받은 더 정교한 파이프라인을 개발했습니다.
먼저 다양한 창작 작업에 대응되는 seed question 집합 Qs를 만든다.
모든 seed question을 직접 few-shot 예시로 사용하는 대신 경량의 MLLM을 이용해 이미지별 상세 캡션을 생성하고 이를 통해 LLM이 캡션에 적합한 일부 seed question만 선별합니다.
그런 다음, 최종적으로 GPT-4o의 few-shot 예시로 무작위로 세 가지 질문 유형을 선택해 품질과 다양성을 유지합니다.
인포그래픽 작업
인포그래픽 이미지(차트, 다이어그램 등)의 질문과 답변은 이미지의 특정 콘텐츠와 연결됩니다.
자연 이미지와 달리 인포그래픽은 주로 텍스트, 색상, 선, 기호적 요소를 통해 정보를 전달하므로 이미지 복잡도나 객체 범주 기반의 평가가 부적절합니다.
정보가 풍부한 이미지를 포함한 소스를 신중히 선택하고 GPT-4o가 포괄적 배경 지식을 요구하는 질문을 생성하도록 특화된 프롬프트를 설계했습니다.
후처리(Refinement)
생성된 데이터 품질을 향상시키기 위해 지시 기반 지식 QA, 풍부한 설명을 포함한 추론 QA, OCR 정확도 및 배경 지식을 결합한 인포그래픽 QA를 만드는 후처리 파이프라인을 구현했습니다.
OmniAlign-V는 지식QA 39K개, 추론QA 37K개, 창작QA 10K개, 지시추종 지식QA 38K개, 인포그래픽 QA 44K개를 포함하며, 추가로 이미지 세부 사항 QA 35K개를 생성하여 총 205K개의 고품질 SFT 훈련 샘플을 구성했습니다.
