Abstract
Multimodal Large Language Models(MLLMs)는 일반적으로 사전 학습된 LLM과 또 다른 사전 학습된 transformer를 MLP로 연결 시켜 LLM에게 시각적인 능력을 부여합니다.
structural textual embeddings과 continuous image embeddings 사이의 불일치로 인해 시각정보와 텍스트 정보의 융합에 어려움이 있습니다.
시각과 텍스트 임베딩을 잘 정렬시키도록 설계된 Ovis를 제안합니다.
Ovis는 비전 인코더의 학습 가능한 추가적인 임베딩 테이블을 통합합니다.
더 많은 시각 정보를 포착하기 위해 이미지 패치는 임베딩 테이블에 여러 번 인덱싱되며 최종적으로는 인덱싱된 임베딩의 확률적 조합으로 구성됩니다.
해당 구조는 텍스트 임베딩을 생성할 때 사용하는 방법과 유사합니다.
해당 방법을 이용하여 모델을 생성하였고 다양한 벤치마크에서 높은 성능을 확인했습니다.
Introduction
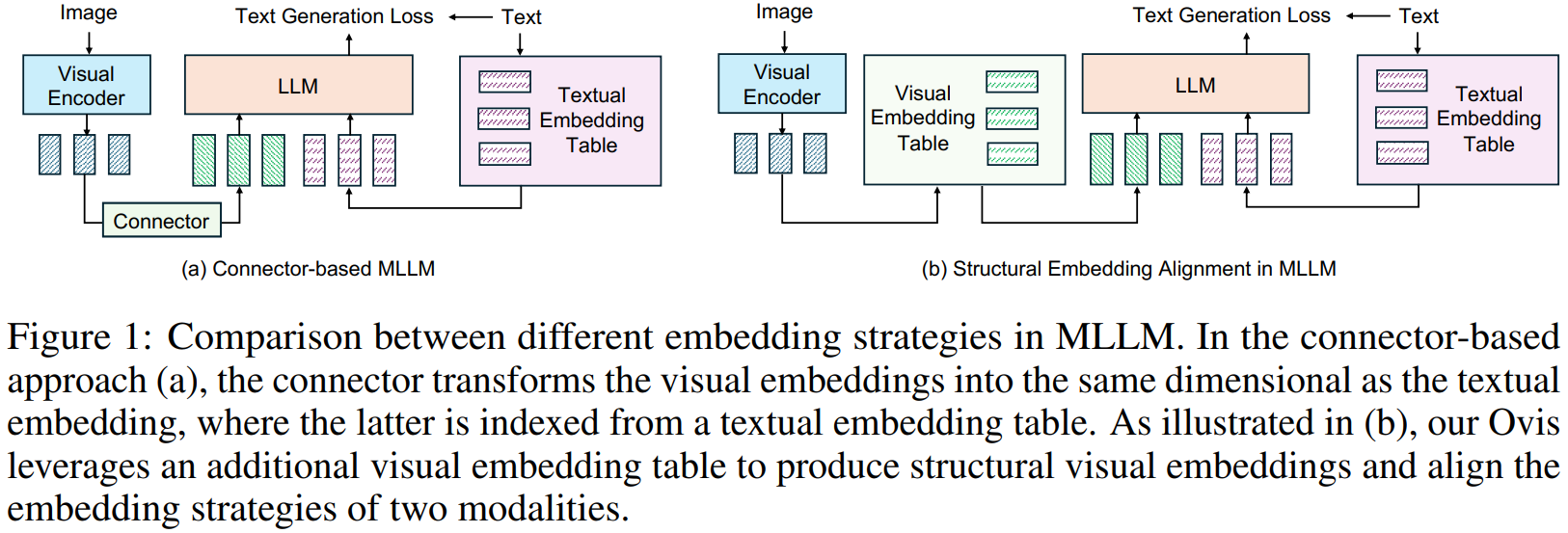
초록에서 설명한 모델 아키텍쳐의 간략한 구조.
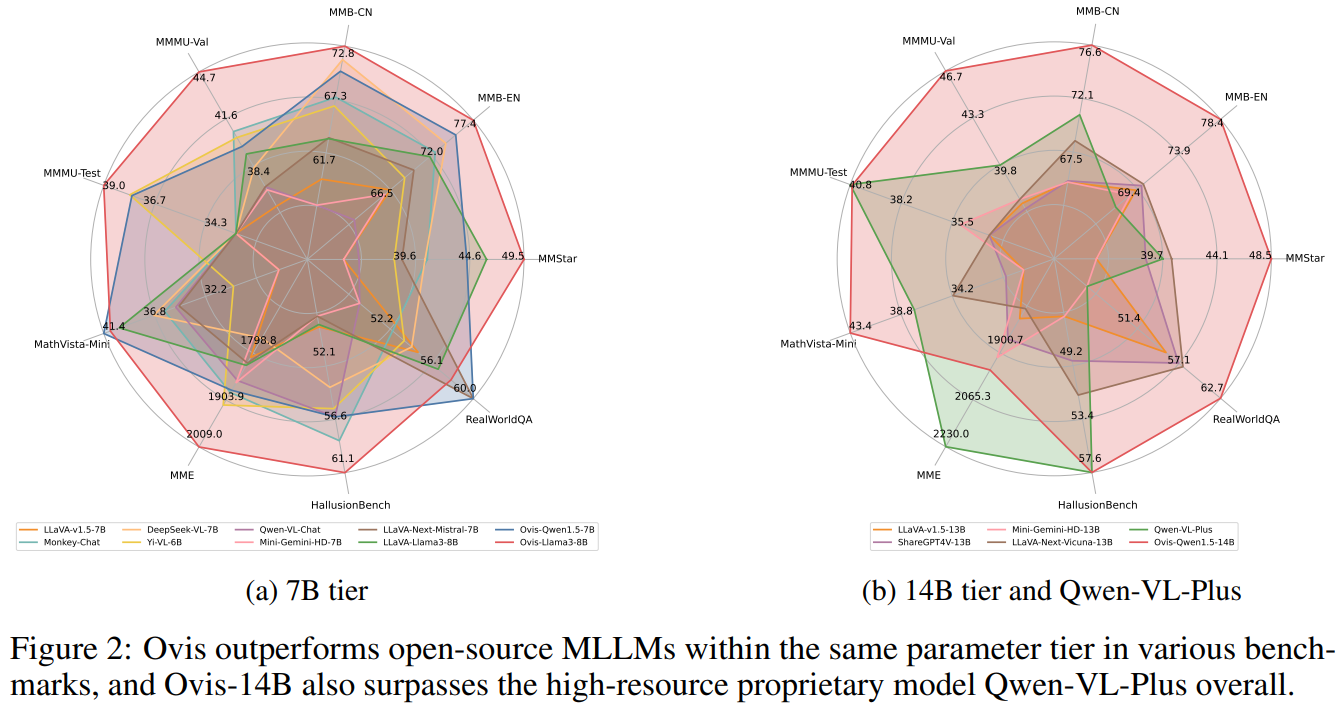
Qwen-VL보다 좋은 성능을 보이는 것으로 확인된다.
LLM은 빠른 속도로 개선되고 있습니다.
정교한 모델들은 다양한 텍스트를 이해하고 생성하는데 뛰어난 능력을 보입니다.
하지만 인간의 다재다능함과 가까워지려면 텍스트에만 국한된 이해를 뛰어 넘어설 필요가 있습니다.
시각적 정보를 이해하는 능력은 AGI로 나아가는 중요한 과정입니다.
오픈 소스 MLLM은 직접 학습을 시키기 보다는 주로 사전 학습된 LLM과 Visual-Encdoer에서 능력을 합치고 있습니다.
비전과 텍스트는 서로 다른 토크나이징과 임베딩 전략을 가지고 있습니다.
이러한 다른 두 차원을 맞추기 위해서 MLP와 같은 연결로 같은 공간으로 이동시켜 LLM의 입력으로 사용될 수 있게 합니다.
해당 아키텍쳐는 차원을 맞추는 연결만을 수행하지만 다양한 작업에서 유망한 성능을 보이고 있습니다.
하지만 이러한 커넥터 기반 아키텍처는 토큰화와 임베딩 전략에서 본질적인 차이로 인해 잠재적인 한계가 존재할 수 있으며 해당 문제에 대한 질문이 떠오릅니다.
텍스트 임베딩 전략과 맞춰 시각적 임베딩을 구조화된 방식으로 생성하면 MLLM에서 성능 향상을 이룰 수 있을까요?
해당 질문에 대한 답으로 Ovis라는 새로운 MLLM 아키텍처를 제안하며, LLM의 능력을 시각적 입력의 구조화된 임베딩에 적용하려고 합니다.
그림1에서 솔 수 있듯이 Ovis는 텍스트와 유사한 일관성을 가진 시각 토큰을 변환하기 위해 추가적인 학습 가능한 visual embedding look-up table을 도입합니다.
동일한 파라미터에서 가장 우수한 성능을 보이는 것을 확인했습니다.
Ovis는 고유한 시간 패턴을 나타태는 시각적 단어에 해당하는 행을 포함하는 visual embedding talbe을 사용합니다.
비전 인코더가 출력한 시각 토큰을 통해 Ovis는 시각적 단어 집합과 유사성을 나타내는 확률 토큰으로 맵핑합니다.
확률 토큰은 단일 시각 패치 내에서 다수의 시각적 단어로부터 패턴을 포함할 수 있는 풍부한 의미를 포착하며 이를 통해 연속 토큰을 visual embedding table에서 샘플링된 것처럼 사용합니다.
Ovis는 확률적 토큰에 따라 임베딩 테이블을 여러 번 인덱싱하여 최종 시각 임베딩을 생성하는데, 이는 테이블 전체 임베딩에 대한 기대로서의 결합된 임베딩입니다.
이를 통해 Ovis는 시각적 임베딩 전략을 텍스트와 유사한 구조적 특성과 맞추고자 합니다.
Ovis의 학습 과정은 텍스트 생성 손실과의 조합을 통해 3단계 방식으로 진행되며, 추가적인 벡터 양자화를 사용한 오토인코더와 같은 복잡한 손실을 사용하지 않습니다.
Ovis

해당 파트에서는 MLLM에서 visual embedding 전략과 text embedding 전략 간의 차이를 확인합니다.
확률 토큰에 대한 선형 매핑과 LLM 내에 추가적인 visual embedding lookup table을 포함하는 아키텍쳐 Ovis를 소개합니다.
Difference between Visual and Textual Tokens
MLLM에서는 이미지와 텍스트가 입력으로 제공되면 이들은 다양한 토큰화 전략을 가지고 있습니다.
이미지는 C, H, W로 구성되어 있고 사전 학습된 Vision Transformer를 사용하여 visual
representations으로 변환됩니다.
텍스트의 경우 LLM에 의해 처리됩니다.
MLLM에서 시각 토큰과 텍스트 토큰은 모두 동일한 형식으로 변환되어야 하며 모든 토큰을 텍스트 토큰의 형태의 출력 시퀀스로 표현합니다.
멀티모달 입력 토큰은 다음과 같습니다.
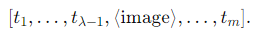
를 직접 대채하는 것은 어려운 과정입니다.
기존 접근 방식에서는 시각 토큰을 텍스트와 동일한 형식으로 맵핑하기 위해 추가적인 MLP, Transformer를 도입합니다.
Probabilistic Visual Tokens
연속적인 시각 토큰을 사용하는 대신 이미지와 텍스트 간의 내부 토큰화 전략을 일치시켜 MLLM 성능을 향상시키려고 합니다.
이산 텍스트 토큰을 모방하기 위해 우리는 선형 헤드를 사용하여 시각 토큰을 변환합니다.
여기서 K는 visual vocabulary size, 고유한 시각 단어의 수를 나타냅니다.
시각 토근 이 주어지면 NLP와 softmax 정규화를 통해 로 만듭니다.
이때 는 시각 단어에 포함된 K개의 시각 단어에 대한 확률 분포를 나타내는 일종의 확률 토큰으로 설정됩니다.
만약 가 특정 패턴과 더 관련이 있다면 내에서 해당 요소들이 더 크게 나타나야 합니다.
Training Strategy of Ovis
시각과 텍스트 임베딩은 LLM의 입력으로 결합됩니다.
특히 아래와 같은 멀티 모달 입력 임베딩 시퀀스가 LLM에 입력으로 제공됩니다.
모든 토큰은 동일한 차원을 가지며 embedding table을 사용하여 유사한 방식으로 생성됩니다.
Ovis는 3단계의 학습 과정을 거치며 텍스트 생성 loss를 통해 최적화됩니다.
Ovis는 출력 텍스트 토큰과 정답 텍스트 간의 cross entropy를 사용하여 최적화됩니다.
1단계
LLM의 모든 파라미터와 비전 인코더 𝑔(오픈소스 사전 학습된 ViT 백본)의 대부분의 파라미터를 고정합니다.
𝑔의 마지막 블록 내의 파라미터를 무작위로 다시 초기화한 후, COY와 같은 시각 캡션 데이터셋을 사용하여 다시 초기화된 파라미터와 Ovis의 투영 𝑊 및 시각 임베딩 테이블 을 학습합니다.
2단계
이 단계에서는 Ovis의 𝑊, 시각 임베딩 테이블 , 비전 인코더 𝑔의 모든 파라미터를 학습합니다.
LLM은 계속 고정된 상태를 유지합니다.
단계에서 사용한 캡션 샘플과는 달리, ShareGPT4V-Pretrain과 같은 시각 설명 데이터셋을 활용하며, 이 데이터셋은 이미지 설명을 담은 대화 형식의 학습 샘플로 구성됩니다.
3단계
1단계와 2단계의 학습을 통해 Ovis에 시각적 인식 능력을 부여한 후 멀티모달 명령어 학습에 집중합니다.
목표는 Ovis가 멀티모달 명령어를 따를 수 있는 능력을 갖추도록 하는 것입니다.
이를 위해 LLM의 학습을 시작하고 LLaVA-Finetune과 같은 멀티모달 명령어 데이터셋을 사용하여 Ovis의 전체 파라미터 집합을 학습합니다.
Experiments
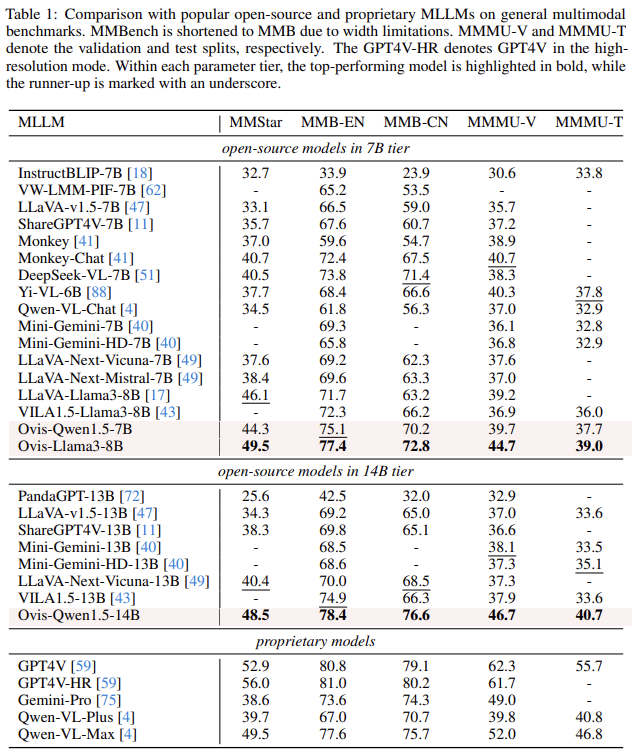
오픈 소스에 공개되어 있는 7B와 14B에서는 가장 좋은 모습을 보이는 것을 확인할 수 있다.
프론티어 모델인 GPT, Gemni, Qwen등과 비교해서는 살짝 부족한 성능을 보이는 것을 확인할 수 있다.
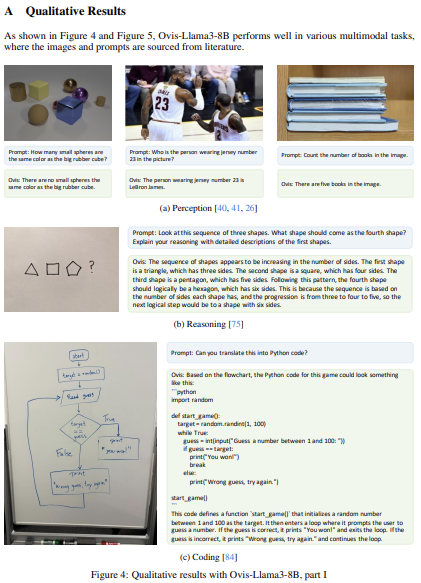

다양한 작업이 가능함을 확인할 수 있다.
Conclusion
본 논문은 MLLM에서 시각 임베딩과 텍스트 임베딩을 구조적으로 일치시키는 것을 강조합니다.
이는 두 임베딩의 토큰화 및 임베딩 전략이 다르기 때문에 발생하는 성능 저하를 막을 수 있습니다.
Ovis 또한 추가적인 visual embedding look-up table을 도입하여 이미지 패치를 확률 토큰으로 매핑하고 이를 시각 임베딩 테이블에 인덱싱하여 텍스트 임베딩과 유사한 구조적 방식으로 변환합니다.
Broader Impact and Limitations
Broader Impact
Ovis는 강력한 멀티모달 대형 언어 모델 아키텍처로서, 시각 콘텐츠와 텍스트 분석 간의 상호작용을 향상시킴으로써 다양한 사용자들에게 혜택을 제공할 잠재력을 가지고 있습니다.
그러나 Ovis는 잘못된 정보나 오해를 불러일으킬 수 있는 환각(hallucination)의 위험과 같은 부정적 영향도 있을 수 있음을 인지하는 것이 중요합니다.
Limitations
Ovis는 유망한 성능을 보여주었지만, 고해상도 이미지를 처리하는 능력은 고해상도 부스트 기술의 부재로 인해 제한적입니다.
또한, Ovis는 단일 이미지 샘플로만 학습되어 다중 이미지 이해가 요구되는 상황에서는 어려움을 겪을 수 있습니다.
이러한 문제를 해결하기 위한 연구가 주로 커넥터 기반 프레임워크 내에서 이루어졌으며 이를 통해 향후 고해상도 이미지를 더 잘 처리하고 다중 이미지 입력을 다룰 수 있는 Ovis의 성능 향상을 계획하고 있습니다.

늘 아주 멋지시네요..