알고리즘
repeat()의 존재를 알면 이렇게 쉽고 깔끔한데!
function foodFormation(food) {
const foodNum = [];
let foodString = [];
food.forEach((item, index, arr) => {
let foodCount = Math.floor(arr[index] / 2)
foodNum.push(foodCount)
})
for (let i = 1; i < foodNum.length; i++) {
for (let j = 1; j <= foodNum[i]; j++) {
foodString.push(i)
}
}
const answer = foodString.join('') + 0 + foodString.reverse().join('')
return answer;
}
function solution(food) {
var answer = '';
answer = foodFormation(food);
return answer;
}나는 이렇게 forEach를 쓰고도 결국 무지성으로 이중for문을 써서 풀었는데, 다른 천재들의 풀이를 보니 10줄도 안되게 풀어낸 코드가 있었다. 바로 repeat().
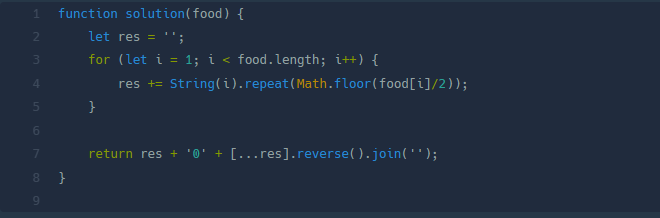
이 풀이를 본 내 기분: 롸? 이거 뭔데. 이거 어떻게 하는건데. 도와줘요 MDN!
repeat() mdn 문서
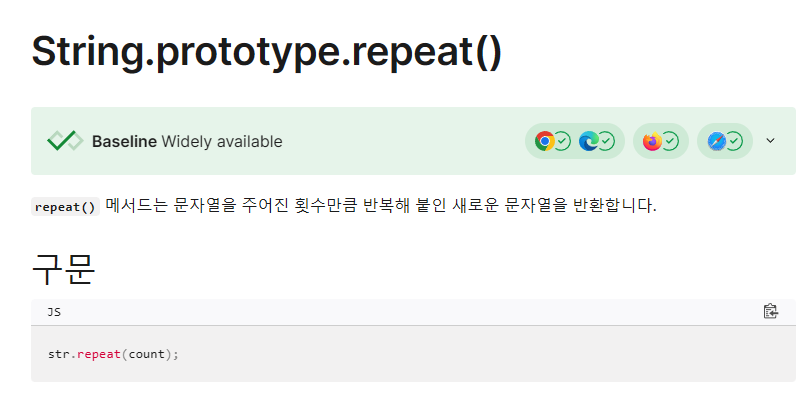
배열에 넣고 붙여서 문자열로 flat하게 만들려고 끙끙댔는데 repeat() 하나면 쉽게 풀리는 거였다. 그러고보니 repeat()는 로그라이크에서도 나왔었다.
웹소켓 과제
강의 타임라인 정리
처음 ~ -> 비동기로 데이터 테이블 JSON파일 불러오는 작업
27:41 -> 유저 접속 관련코드 시작
40:11 -> 스테이지 관련코드 시작
62:30 -> moveStage 관련 stage 핸들러 검증
80:03 -> 게임 끝났을 때 이 사람 몇점인지
현재의 구현상태
구현 여부 체크
-
시간에 따른 점수 획득 -> ✔
-
스테이지 구분 -> 없는 것 같다
-
스테이지에 따른 점수 획득 구분 -> 스테이지가 없으니 당연히 없겠지?
-
아이템 획득 -> ✔
-
아이템 획득 시 점수 획득 -> 없는 것 같다
-
아이템 별 획득 점수 구분 -> 아이템 획득시 점수가 없으니 당연히 없겠지?
일단 배경부터 바꾸고 싶은데 -> z축 개념이 없어도 된다
2D인데 배경을 갈아치울 수 있을까?
-> 있다. 배경이 될 이미지를 제일 먼저 draw() 해주면 된다.
이벤트? 데이터 교환
그러므로 이벤트 핸들러 = 데이터 교환 핸들러를 말한다.
handler(data.userId, data.payload) 에서 userId는 변하지 않지만 payload는 핸들러마다 보내주는 내용이 다르다.
게임 시작할 때 시간을 받아야 한다 -> 스테이지 저장 시 시간을 같이 저장해야 한다!
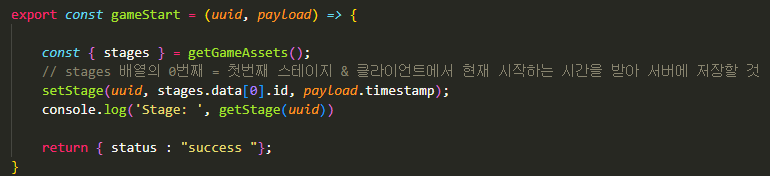
그러면 이런 코드가 나온다.
- 원래 클라이언트의 그 어떤 정보도 서버에 '바로' 저장하진 않는다. 이유는 간단하다. 데이터 변조의 위험이 있기 때문. 서버 기준으로 검증되지 않은 정보들은 절대로 저장하면 안된다.
그러나 편의&개발속도를 위해 현재는 클라이언트의 데이터를 신뢰한다고 가정하고 가자.
유저의 점수 = 각 스테이지에서 계산한 값의 합
각 스테이지 별로 초당 얻는 점수를 다르게 세팅한다면, 각 스테이지별로 시작하는 시간을 저장해줘야 한다.
1스테이지: 1점/초, 60초 진행, 아이템점수 300이라면 (1점 60초) + 300 = 360
2스테이지: 2점/초, 100초 진행, 아이템점수 500이라면 (2점 100초) + 500 = 700점
내 합계점수 = 360 + 700 = 1060점 -> 이런 식으로 나온다.
connection일때 클라이언트 버전을 체크하고 싶다면?
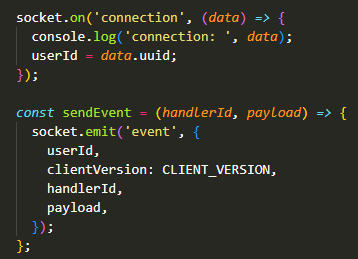
위 코드 상으로는 connection일때는 클라이언트 버전 체크가 안 된다.
event일때 말고 connection일때 체크할 순 없을까? 어떻게 해야할까?
-> helper.js에서 handleConnection을 어떻게 수정하면 되지 않을까?
아무쪼록. 일단 '바구니를 만들어준다'를 잊지 말자. 스테이지 상태든 스코어 상태든 뭐든 담아줄 바구니가 필요하다.
clearStage가 필요한 이유 - 이전 게임기록이 삭제되지 않아
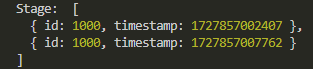
clearStage를 만들기 전에는 이렇게 나왔다. 새로 시작했는데도 이전 게임의 스테이지 정보가 배열에 들어가있어 배열 요소가 여러개인 상태.

gameHandler의 gameStart()에 clearStage()를 넣어주니 이제는 위와 같이 나왔다. 이전 게임 기록이 배열에 들어가있지 않고 새 게임 시작 시 한개씩만 들어가있는 모습을 볼 수 있다.
파비콘 에러는 대체 왜 뜨는걸까 - 안 넣어도 해결할 수 있다
참고 블로그
나는 참고 블로그 내용대로 <link rel="shortcut icon" href="#"> 를 index.html의 head 부분에 넣어서 처리했다. 다만 JAVA의 경우 #을 넣으면 문제가 생길 수 있다고 하니 href=""로 넣도록 하자.
싱글톤? 일종의 디자인 패턴
참고 블로그
언제 어디서나 한번만 생성하자는 것! 관리하기 편하게.
-> 생성자를 통해 여러번 호출이 되더라도 인스턴스를 새로 생성하지 않고 최초 호출 시에 만들어두었던 인스턴스를 재활용하는 패턴이다.
한 프로그램 수명 안에서 한번만 생성해서 어디서나 가져다 재활용 할 수 있다. 생성자를 private으로 써주기 때문에 (JAVA 기준) new로 계속 생성하는 것 또한 막을 수 있다고. 희원님의 지식의 샘은 끝이 없다. 으아아.
AABB? OBB라는 것도 있어요. 충돌에 관한 것
참고 블로그
희원님이 AABB라는 말씀을 해주셨는데, 저게뭐여!? 컨트롤러 입력인가?! 했지만 전혀 아니었다. 바운딩 박스의 충돌에 관한 내용이었다.
이 얘기가 나오게 된건 웅상님이 공룡점프의 충돌에 대한 고민을 하고 계셨기 때문.
AABB는 Axis Aligned Bounding Box. 축이 정렬된 박스들끼리의 충돌.
OBB는 Oriented Bounding Box. 축이 회전한 물체의 충돌이다.
Node 심화
다시만난 MVC - 프론트와 백이 잘 나누어지지 않았을 때 자주 사용하던 패턴
UI가 필요한 어플리케이션에서 많이 사용되는 패턴이기도.
- 모델: 데이터와 비즈니스 로직을 담당
- 뷰: UI를 담당
- 컨트롤러: 클라이언트의 요청을 모델과 뷰로 전달해주는 역할 담당
계층형 아키텍처 패턴 - 앞으로 우리가 배우게 될 것
Presentation -> Business -> Presistence -> Database 순서로 되어 있는데, DB는 몽고DB같이 진짜 DB 레이어라서 제외하고 보면 Presentation - Business - Presistence 로 구성되어 있다.
-
Presentation - 클라이언트와 서버가 가장 처음 만나게 되는 부분. 어떤 URL과 메서드를 사용할지 정하고, URL과 메서드가 일치할 때 콜백함수를 실행하는 식으로 여러 라우터를 구현했었다. 클라이언트에서 요청이 들어오는 부분을 정의하기 위해서는 Presentation 계층에서 해당하는 로직들이 사용된다.
-> 컨트롤러 계층으로 분리됨 -
Business - 실제 해당하는 핵심적인 비즈니스 로직이 작성되는 부분. 만들었던 쿠키를 반환, 클라이언트에서 받은 id, pwd 등을 검증하는 등의 여러 로직이 돌아간다.
-> 서비스 계층으로 분리됨 -
Presistence - 영속성 계층. 아래에 있는 데이터베이스 계층을 사용하기 위한 계층이라고 보면 된다. 실제 DB에 있는 특정 메서드를 구현하기 위해 사용하는 경우가 대부분. 특정 사용자의 정보를 가져오고 싶다면 이 레이어에서 DB 레이어로 '이 이메일에 해당하는 유저 정보를 나한테 줄래?' 라고 요청하게 된다.
-> 리포지토리 계층으로 분리됨
스프링에서는 이게 필수다! 그래서 내가 스프링 할때 이걸 배웠던 것.
-> 단순하고 대중적이면서 비용도 적게 들어서, 사실상 모든 어플리케이션의 표준 아키텍처와 같다. 어떤 패턴을 도입할지 확신이 없다면 좋은 선택지일 수 있다.
각 계층을 명확하게 분리해서 유지하고, 각 계층이 자신의 바로 아래 계층에만 의존하게 만드는 것이 계층형 아키텍처 패턴의 목표.
클린 아키텍처 패턴이 뭔데?
계층형 아키텍처를 쓰다 보면 문제점이 보이기 시작할 것이다. 서비스 계층에 비즈니스 로직이 너무 많이 생긴다거나, 리포지토리 계층에 여러 테이블을 사용해야 하는데, 의존성을 어떻게 관리할 것인지 등..
그 문제점을 해결하기 위해 나타난 패턴. 핵심 비즈니스 로직이 제일 내부인 엔티티 레이어에서 돌아가기 때문에, 최종적으로 의존성이 내부 도메인으로 향하도록 만들어진 패턴.
-> 클라이언트의 요청 처리, DB조작, 외부 시스템과의 통신 등 외부에서 들어온 것은 외부 계층에서 처리한다.
-> 소프트웨어의 유지보수성과 확장성을 향상시키는 것이 주요 목표인 패턴.
마이크로 서비스 아키텍처(MSA) 패턴 - 작고 독립적으로!
시스템을 작고 독립적으로 배포 가능한 서비스로 분할하는 패턴. 그래서 하나의 시스템에서 다양한 언어와 프레임워크를 도입할 수 있다. A는 스프링으로 만들고, B는 Next.js로 만들고, C는 Go로 만들고...
-> 서비스 간의 통신은 API 또는 이벤트 기반 아키텍처(EDA)를 통해 통신한다.
GRPC, Kafka, Redis, SQS 등 메시지 큐를 통해 각각의 서비스가 통신한다.
아키텍처 패턴이 항상 정답은 아니야 - 이유를 잘 알자
- 아키텍처 패턴이 주는 이점과 비용에 대한 확실한 이유가 있어야 한다! 그냥 코드 짜는게 더 나을 수도 있다.
- 해당 아키텍처 패턴을 채택했을 때 어떤 장단점이 존재하는지 명확하게 인지해야 한다.
- 여러 계층을 추가하기 위해 들이는 노력과 시간을 투자할 가치가 있을 정도로 어플리케이션과 도메인이 복잡한 경우에만 도입해야 한다!
-> 가벼운 프로그램에 복잡한 패턴 도입해봐야 리소스 낭비일 뿐일 수도...😥
계층화의 핵심 - 높은 응집도, 낮은 결합도
각 계층은 높은 응집도를 가지면서, 다른 계층과는 결합도를 최소화 하는 것이 계층화의 핵심. 상위 계층은 하위 계층을 사용할 수 있지만, 하위 계층은 자신이 어떤 상위 계층에 속하는지 알 필요 없이 독립적으로 동작할 수 있어야 한다.
-> 영속성 계층은 비즈니스 로직 계층에 어떤 코드가 있는지 알 수도 없고, 사용해서도 안된다는 얘기
일반적으로 계층형 아키텍처는 3계층으로 분리된다. 더 복잡하면 3 + 알파!
-> 이게 내가 아는 컨트롤러 서비스 리포지토리 이다.
3계층 아키텍처
- 프레젠테이션 계층 -> 컨트롤러. 요청/응답을 처리
- 비즈니스 로직 계층 -> 서비스. API의 핵심 동작이 일어나는 부분
- 데이터 액세스 계층 (=영속성 계층) -> 리포지토리. 어플리케이션 가장 내부, DB와 맞닿은 부분