Node.js 심화
우리는 지금까지 계층형 아키텍처 패턴을 공부하고 있었다. 기억나지 않는다면 241002 TIL 로 다시 돌아가보자
컨트롤러
클라이언트의 요청을 받고 응답을 반환하는 단. 요청에 대한 처리는 스무스하게 서비스에게 떠넘겨버리는 문지기.
- 하위 계층에서 발생하는 예외를 처리
- 클라이언트 데이터 유효성 검증
- 클라이언트 요청 처리 후 응답 반환
서비스
컨트롤러한테 짬처리 당한 요청을 처리하는 실세중에 실세인 단. 그러나 얘도 DB 정보가 필요할 경우 리포지토리에게 요청을 떠넘겨버린다.
리포지토리
DB 관리 역할을 담당. DB 접근이 필요한 요청이 들어오면 서비스에게서 떠안은 요청을 처리하기 위해 DB의 CRUD 작업을 처리한다.
컨트롤러는 그뤈거 몰롸😎 - 추상화 덕분에 몰라도 돼
컨트롤러는 하위 계층의 내부 구조에 대해 신경쓰지 않는다. 외부에 공개된 메서드를 호출하기만 할 뿐. 이것이 가능하게 해주는 게 바로 '추상화'의 특성 덕분!
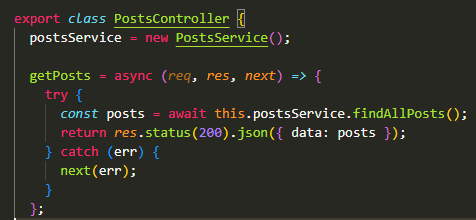
-> 컨트롤러 클래스는 전달된 요청 처리를 위해 서비스를 호출하도록 구현되어 있다.
-> 본인이 비즈니스 로직 수행하지 않고 클라이언트의 요청을 서비스 계층으로 전달한다 짬때리기
-> 전달 했으면 끝! 컨트롤러는 그뤈거 몰롸😎 서비스 계층이 어떻게 로직 돌리는지 알고 싶지도 않고, 그냥 일 다하고 응답 다되면 나한테 건네줬으면 하는 것. 마치 콜백함수 처럼(?)
-> 이런 식으로 각 계층이 자신의 역할에만 집중할 수 있고, 다른 계층의 세부사항에 대해 알 필요가 없어지는 것이 3계층 아키텍처 이다.
서비스는 바빠🤸 컨트롤러한테 요청받고, 리포지토리한테 요청하고
프레젠테이션 계층(컨트롤러)과 데이터 액세스 계층(리포지토리) 사이에서 중간다리 역할을 하며, 두 계층이 직접 통신하지 않도록 만들어 준다.
어플리케이션의 규모가 커질 수록 이 서비스 계층의 역할과 코드의 복잡도도 커진다.
어플리케이션의 핵심적인 비즈니스 로직을 수행, 클라이언트들의 요구사항을 반영하여 원하는 결과를 반환해주는 계층.
장점
- 사용자의 유즈케이스와 워크플로우를 명확히 정의, 이해할 수 있도록 도와준다
-> 이게 뭔 소리여?🤯🤯🤯🤯 - 이름이 직관적이라 뭔 메소드인지 알기 쉽다는 것! - 비즈니스 로직이 API 뒤에 숨겨져 있어, 서비스 계층의 코드를 자유롭게 수정하거나 리팩터링 할 수 있다
- 저장소 패턴 및 가짜 저장소(Fake repository)와 조합하면 높은 수준의 테스트를 작성할 수 있다

가짜 저장소...?
단점
- 서비스 계층도 하나의 추상화 계층이라서, 잘못 사용하면 코드 복잡성이 증가한다!
- 한 서비스 계층이 다른 서비스 계층에 의존하는 경우 의존성 관리가 복잡해진다!
-> 이 경우는 생각보다 흔하다. 사용자 테이블과 게시글 테이블을 같이 조회한다던지 하는 경우가 많다. - 서비스 계층에 너무 많은 기능을 넣으면, '빈약한 도메인 모델' 같은 안티 패턴이 생길 수 있다.

(대충 이렇게 되나보다)
저장소 aka 데이터 액세스 계층 - DB관련 작업을 해요📝
- 데이터 접근과 관련된 세부사항을 숨기는 동시에, 메모리 상에 데이터가 존재하는 것 처럼 가정하여 코드를 구현하게 된다.
- 저장소 계층을 도입하면 데이터 저장 방법을 쉽게 변경할 수 있고, 테스트 코드 작성 시 가짜 저장소(Mock Repository)를 제공하기 쉬워진다.
-> 나중에 컨트롤러나 서비스 계층을 유닛테스트 하게될 수 있는데, 이때 리포지토리 계층 아래는 진짜 저장소와 연결되어 있기 때문에 이거 말고 외부에 있는 가짜 저장소라는 별도의 계층을 사용하게 된다. - 다른 계층들은 저장소의 세부구현 방식을 알지 못해도 쓸 수 있다. 저장소 계층에 변경사항이 생겨도 다른 계층에 영향을 주지 않는다😎
-> 이게 뭔 소리야?🤯
-> findAll()이라는 메서드가 있다고 가정해보자. 이때 저장소 계층이 로우쿼리로 데이터를 찾아오든 Prisma를 써서 findMany로 데이터를 찾아오든 나머지 계층은 이와 상관이 없다는 것. 결과만 찾아와주면 OK!
-> 위에서 말한 '컨트롤러는 그뤈거 몰롸😎' 와 같이 추상화 덕분에 이렇게 되는 것. 😁
대표적인 저장소 계층의 메서드
add(), create() : 새 원소를 저장소에 추가
get(), find(): 이전에 추가한 원소를 저장소에서 가져옴
장점
- 데이터 모델(DB)과 데이터 처리 인프라(저장소 계층)를 분리했기 때문에 단위 테스트를 위한 가짜 저장소를 쉽게 만들 수 있다
- 도메인 모델을 미리 작성하여, 처리해야 할 비즈니스 로직 문제에 더 집중할 수 있다
- 객체를 테이블에 맵핑하는 과정을 원하는 대로 제어할 수 있어서 DB스키마를 단순화 할 수 있다
- 저장소 계층에 Prisma 같으 ORM을 사용하면 필요할 때 MySQL이나 Postgres와 같은 다른 DB로 쉽게 전환할 수 있다
단점
- 저장소 계층이 없더라도 ORM은 모델과 저장소의 결합을 완화시켜줄 수 있다. 굳이? 라는 것
-> ORM이 없을 때는 저장소 계층의 사용 목적이 명확했다. 대부분의 코드는 로우쿼리로 작성되어 있기 때문에 이걸 관리하려면 저장소 계층이 필요했기 때문 - ORM 매핑을 수동으로 하려면 개발 코스트가 더 소모된다
-> 몽구스든 프리즈마든 사용하려면 그 세팅을 개발자가 스스로 해줘야 하기 때문에 더 힘들 수도 있다는 것. (프리즈마 스키마로 머리 터지던 내 모습🤯🤯🤯)
컨트롤러, 서비스, 리포지토리로 나누면 에러처리는 어떻게 하지?
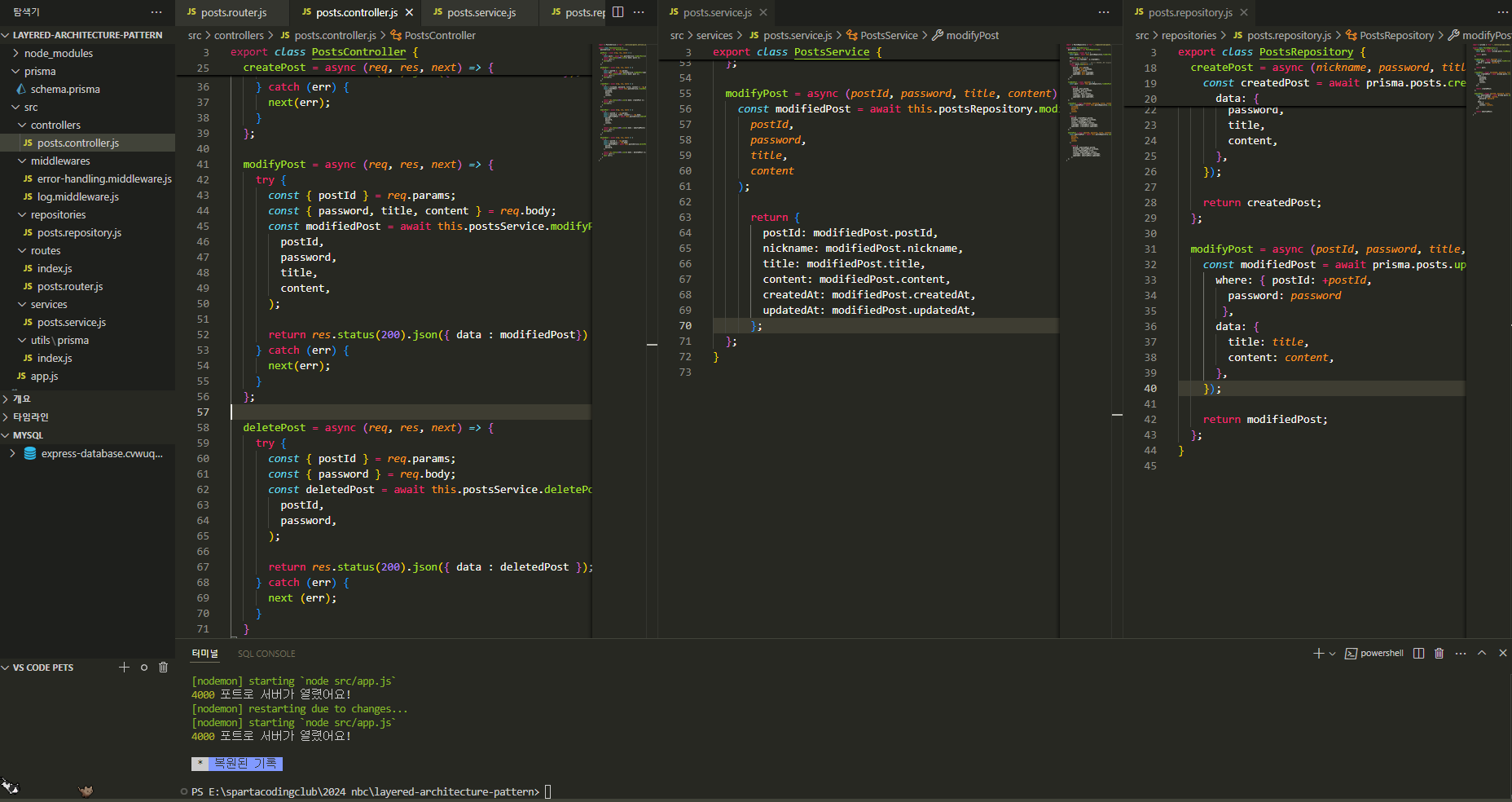
이를테면 이렇게 나눠서 만들고 있을 때, 비밀번호가 맞아야만 게시글의 수정이나 삭제가 가능하게 된다고 생각해보자.
그러면 비밀번호 일치 여부에 대한 검증 로직은 어디에 들어가야 할까..?! 🤔
이전에는 에러가 생긴다면 return.res 절에 넣어 돌려줬으니 컨트롤러 단인가? 싶지만 그건 아닌 것 같다. 예전에는 이 세개의 로직이 다 한 곳에 들어있었기 때문에 그냥 그런 것 같은...
핵심 비즈니스 로직은 서비스단에 들어간다고 하니 서비스단인가? 싶기도 한데 비밀번호는 DB에 저장될테니 리포지토리인가? 싶기도 하다.
어디에 들어가야 하는걸까? 혹시 이 셋이 아니라 에러처리 미들웨어로 가는걸까? 🥺
참고 블로그 가 스파르타 선배님인 것 같다..! 흠흠. 아무튼.
참고 블로그를 보고 이 글을 상단으로 올려 다시 보니 내가 이미 써놓았구나. 3계층 아키텍처에서 예외처리는 컨트롤러 단에서 해주는 것 이었다.
(컨트롤러의 역할 중 하나가 하위 계층에서 발생한 예외를 처리해주는 것이기 때문)
어라? 강의를 보니 내가 원하는 유효성 검증은 서비스단에서 이루어지고 있었다! 🤔
아까 서비스 계층에서 에러처리를 어떻게든 해보고 싶어 throw new Error를 써본 적이 있었는데, 이 방법도 틀리지 않은가보다.
트러블슈팅
아니, 왜 안돼?! - 라우터에서 기본 URL을 정해줄 수도 있구나
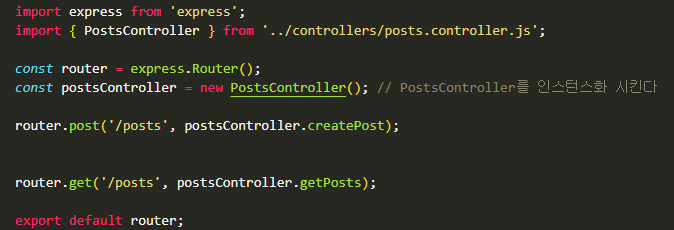
포스트 라우터에서 이렇게 /posts 라고 URL을 써 주었는데,
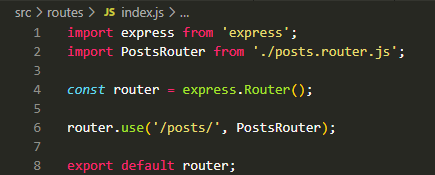
라우터 폴더에서 router.use('/posts/', PostsRouter) 라고 post 관련 라우터에 대한 기본 URL을 픽스해주었다. 그러니 포스트 라우터에서는 /posts가 아니라 / 만 써주면 되는 것.
@prisma/client가 초기화 되지 않았다고? 프리즈마 깔려있는데? 😨😫🤯
결론 : 재설치가 답이었다! yarn add prisma

yarn run dev로 nodemon을 실행시키려는데 이런 메시지가 떴다. 뭐지? 프리즈마 작업이 안 됐나?🤔
npx prisma generate만 입력하면 되는 줄 알았는데, 뭐가 없니 마니 하면서 잘 되지 않았다. 힝🥺
-> 원인은 prisma client가 제대로 설치되지 않았다는 것. 그런데 난 node_modules 디렉토리에 이미 prisma와 @prisma가 다 있었다. 뭐지?🤔
-> 참고 블로그 는 React 문제였는데 React의 버전 차이라고 했다.
-> yarn으로 package.json에 있는 디펜던시 재설치 시도를 했고 다시 다 깔렸는데(이 과정에서 프리즈마 클라이언트가 재설치됨), 그럼에도 불구하고 제대로 되지 않았다. 😥
Environment variable not found: DATABASE_URL ?! 아니 왜 .env도 못불러와?
결론 : VS Code를 재실행해보자
Environment variable not found: DATABASE_URL 라는 메시지가 뜨면서 env("DATABASE_URL") 에 빨간 줄과 화살표를 친절하게 그어주는 프리즈마.
npx prisma generate 해서 MySQL하고 연결도 됐고 DB랑 테이블 다 생겼는데 뭐지? 싶었는데, 결론은 재시작 해보니 되네, 였다. 시도 과정은 다음과 같다.
-> 참고 블로그 는 .env의 이름을 .env.local로 바꿨을 때 나타나는 현상이라서 나와는 다른 케이스였다. 언젠가 나도 .env의 이름을 바꿀 때가 올까? 🤔
-> yarn add dotenv로 dotenv 설치
-> npx prisma generate 시도
-> npx prisma db push 시도
-> 구글 검색 후 DATABASE_URL을 DB_URL로 바꾸는 등 이름변경 시도
-> 아니 왜안돼?! 하면서 VS Code 종료 후 재실행 - 성공
WHERE 1=1이 뭐지? 챌린지반 수업때 본것 같은데🤔
1=1은 당연한거 아냐? 어차피 참이니까 쓸 필요가 굳이 있나? 그런데 쿼리문 끝에 계속 붙어나온다. 용도가 있을 거 같은데 뭘까?

참고 블로그 를 보니 다음과 같은 이유가 있다고.
- 쿼리 디버깅 시 편리한 주석 처리
SELECT *
FROM POST
WHERE POSTID = '5'
AND POSTNAME LIKE 'liha%'예를 들어 이렇게 써놓은 경우 WHERE절의 조건을 주석처리 하는게 귀찮아진다. POSTID = '5'를 주석처리 해야 한다면 줄바꿈을 지우고 뭐하고 뭐하고 해야하기 때문.
- 동적 쿼리에서 특정 상황마다 WHERE절을 다르게 작성해줘야 할때 편리
예.....??? 이게 뭔 소리야.....???? 🤯🤯🤯🤯🤯🤯🤯
-> 동적 쿼리는 조건에 따라 결과값이 달라지는 쿼리를 말한다. 파라미터를 받아 조건을 거는 경우가 대표적이라고.
특정 상황마다 WHERE절을 다르게 작성해줘야 하는 경우는 생각보다 흔하다. 무언가를 조회할 때. 하다못해 주차정산 할때 차 번호를 입력하는 것도 해당.
정규표현식의 gi는 뭐지? g-전역, i-대소문자 구분안함
그래서 Jest에서 제대로 돌아가는 정규식은 다음과 같다!
const localPartRegex = new RegExp(/^[a-zA-z+-_]+$/gi);
const domainRegex = new RegExp(/^[0-9a-zA-Z.-]+$/gi);SQL
NULL인 경우 다른걸로 바꿔주고 싶다면 - IFNULL
SELECT 절에 IFNULL(컬럼명, "NULL일때 다른걸로 치환하고 싶은 값") 으로 써주면 된다.
LIKE절을 좀더 정확히 쓰려면 앞뒤로 %를 붙여주자
열선시트니 통풍시트니 찾는 문제에서 %시트 만 써서 헤맸는데, %시트% 를 써주니까 맞았다.
REPLACE, SUBSTRING, CONCAT은 SQL에도 있다
- REPLACE
REPLACE(바꿀 컬럼, 현재 값, 바꿀 값)
select restaurant_name "원래 상점명",
replace(restaurant_name, 'Blue', 'Pink') "바뀐 상점명"
from food_orders
where restaurant_name like '%Blue Ribbon%'- SUBSTRING
SUBSTRING(문자열 추출할 컬럼, 시작 위치, 추출할 글자수)
select addr "원래 주소",
substr(addr, 1, 2) "시도"
from food_orders
where addr like '%서울특별시%'- CONCAT
CONCAT(붙일 값 1, 붙일 값 2, 붙일 값 3...)
select restaurant_name "원래 이름",
addr "원래 주소",
concat('[', substring(addr, 1, 2), '] ', restaurant_name) "바뀐 이름"
from food_orders
where addr like '%서울%'두 테이블을 붙이되 한 테이블에만 값이 있는걸 찾고 싶다면?
240912 챌린지반 TIL 에서 내가 이 공부를 한 적이 있었다. 과거의 나 기특하다. (?)
SELECT i.NAME, i.DATETIME
FROM ANIMAL_INS as i
LEFT JOIN ANIMAL_OUTS as o ON i.ANIMAL_ID = o.ANIMAL_ID
WHERE 1=1
AND o.DATETIME is NULL
ORDER BY i.DATETIME ASC
LIMIT 3WHERE절에 1=1 붙이는게 왠지 맛이 들려 버렸는데 나 괜찮은걸까(?)