
0. 들어가기 전에 - 기본 개념 정리
-
DBMS : DB 관리 도구로 사용자의 명령을 DB에 전달하고, DB에서 받아온 응답을 사용자에게 전달해주는 사용자와 DB 사이의 프로그램이다
- ORACLE, MS-SQL, MYSQL, MARIADB
-
SQL : DBMS가 DB를 관리하기 위한 용도로 사용하는 언어로 특정 VENDOR에 의존적이지 않다
- VENDOR에서는 SQL + 자체 기술을 통해 VENDOR에 의존적인 SQL을 만들기도 한다. 대표적으로 ORACLE의 PL/SQL이 있다
-
DATABASE : DATA를 TABLE에 담아 저장하는 저장소로 DATA를 담는 큰 그릇과 같다
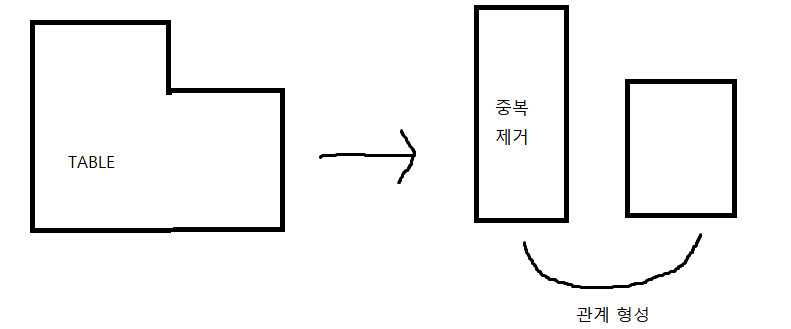
- 빈 공간과 중복이 존재하는 TABLE이 존재할 때, 이 TABLE을 L자 구조로 만든 다음, TABLE을 빈 공간이 존재하는 COLUMN을 기준으로 나누어서, 중복이 존재하면 안되는 TABLE의 중복을 없애고, 주 TABLE과 보조 TABLE 사이에 관계를 형성 시켜준다
- 생성된 TABLE은 관계를 형성하여 유의미한 데이터를 추출해 낼 수 있게 된다
- 이러한 관계형 DATABASE는 여전히 많이 사용되고 있지만, 최근의 경량과 같이 소규모 DATA의 잦은 입출력에 대해서는 관계형보다는 NoSQL 등을 활용하는 경향이 늘어나고 있다
-
기본 키 ( PK ) : 각 ROW를 구분하는 유일한 COLUMN
- 예를 들면, 회원가입시 각 ROW의 유일성을 보장 받기 위하여 ID 를 필수 입력 사항으로 받는다. 이때 기존 DB에 동일한 ID가 있는지 여부를 미리 확인하고, 없을 경우에 DB에 행을 작성하게 된다. 우리는 ID를 통해 특정 USER를 확인할 수 있는데, 이러한 ID와 같은 COLUMN을 기본 키로 지정할 수 있다
- 기본 키로 지정되면 데이터 입력이 필수이므로, 별도로 CHECK하지 않더라도 NOT NULL로 지정된다
- 이와 비슷하게 DATA 작성시 유일성을 보장받기 위한 것으로 UNIQUE를 사용할 수 있다. 허나, 이는 회원가입시 휴대폰 번호와 같은 것으로 유일성을 보장받으나 반드시 입력해야 하는 사항은 아니다
- 기본 키 : 유일성 보장, 반드시 입력
- UNIQUE : 유일성 보장, 반드시 입력 X
-
외래 키 ( FK ) : 외래 키를 통해 부모 TABLE에 도달하면 부모 TABLE의 유일한 DATA를 참조할 수 있다
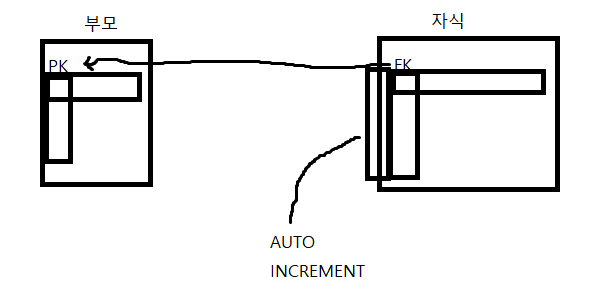
- 자식 TABLE에도 유일성을 보장해야 하므로 AUTO INCREMENT를 통해 DATA가 들어올 때 번호와 같은 것이 자동으로 증감해서 추가되게 한다. TABLE 설정시 이 값은 NULL로 두면 된다. 예를 들면, 주문을 할 때 주문 번호가 자동으로 증감해서 추가되게 하는 것이다
-
DATABASE 구축 절차
- DATABASE 생성 -> TABLE 생성 -> DATA 입력 -> 활용 ( select 정령... )
- 웹이나 CLI 와 연결하여 사용자에게 정보를 제공
1. SAMPLE DATABASE 설치 및 확인
P.28 | 샘플 DATABASE 설치로 실습시 자주 사용하므로 참조하자

- ~면 HOME DIRECTORY로 /root를 의미한다
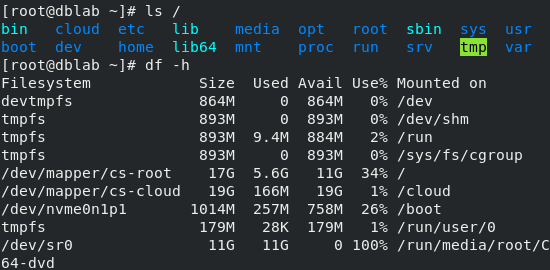
- ls를 통해 생성한 DIRECTORY들과 df -h를 통해 설정한 용량들을 확인하자
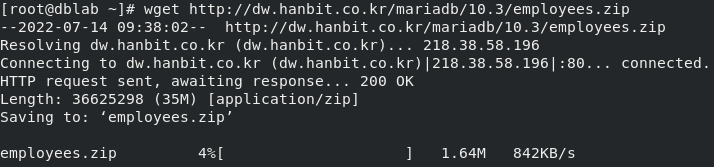
- SAMPLE DATABASE zip 파일을 wget을 통해 다운받자

- 잘 다운 받아졌다

- dbtest 폴더를 만들어서 mv로 다운 받은 파일을 dbtest 폴더 안으로 옮긴다
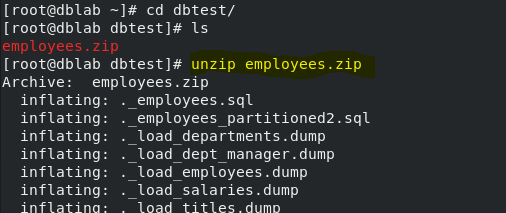
- dbtest 폴더에 들어가서 파일을 확인하고, unzip을 통해 압축을 풀어주자
- 안에 DB가 백업된 sql 파일들이 들어있다
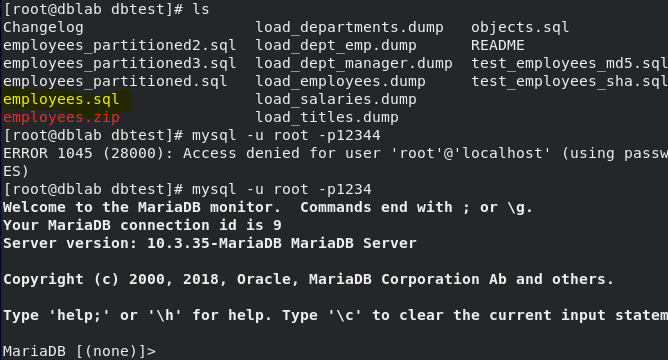
- employees.sql 파일이 있는 폴더에서 sql을 실행시킨다
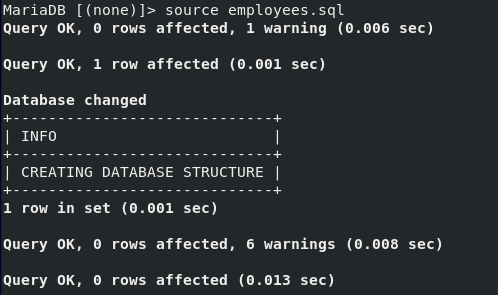
- source를 통해 백업된 sql 파일을 현재 sql에 반영시킨다

- TABLE 리스트와 TABLE의 구조를 확인하자
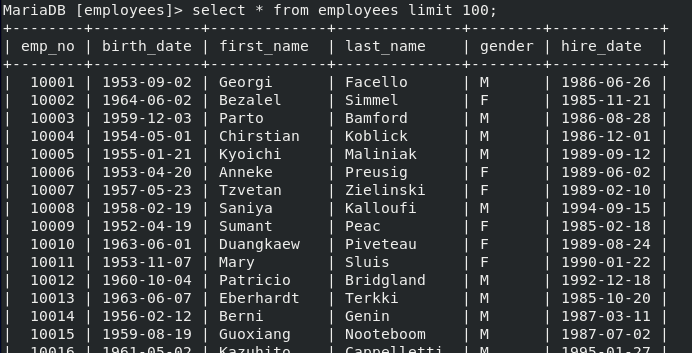
- employees TABLE의 DATA 100개만 출력해보자
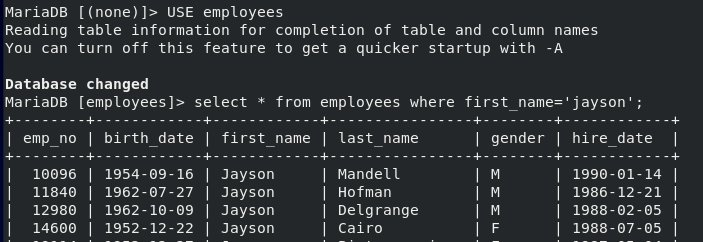
- 이름이 jayson인 employee의 정보를 출력하자
- 혹시 나가게 되면 다시 접속해서 USE '사용할 DB 이름' 으로 다시 들어오면 된다
2. DATA 복사 & Index 사용해보기
p.65
INDEX
- INDEX는 검색 속도를 높이기 위한 튜닝 기법 중 하나로 책의 색인과 같은 것이다. INDEX는 TABLE의 COLUMN 단위에 생성한다
- 허나, 무조건 INDEX를 사용한다고 해서 속도가 높아지는 것 만은 아니다. 그냥 DATA를 찾는 것이 INDEX를 확인하고, 그에 해당하는 DATA를 찾는 것보다 빠른 경우가 있기 때문이다
- 보통은 PK 열에 지정하는 경우가 많다
- 복사할 TABLE의 COLUMN과 복사된 DATA를 받아올 TABLE의 COLUMN은 타입과 구조는 같아야한다. COLUMN 이름은 달라도 된다
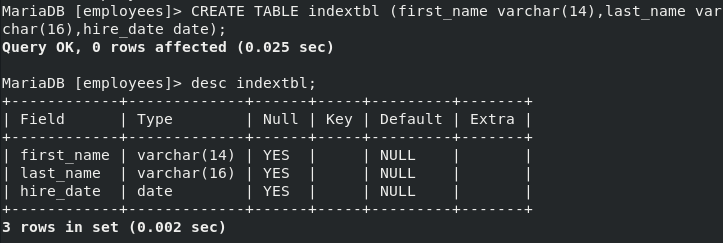
- 복사할 DATA의 TABLE의 COLUMN의 구조와 동일하게 TABLE을 생성한다
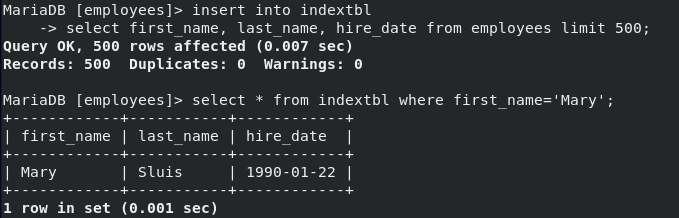
- Value를 통해 insert를 하면 하나하나 다 입력해야한다
- 따라서, select를 통해 employees Table에서 3가지 DATA 500개를 복사해서 insert 한다
- 확인해보면 잘 저장된 것을 확인할 수 있다

- 해당 sql 문 실행에 대한 설명을 확인하면 type이 ALL이라고 되어있다. 이는, 모든 DATA를 참조하여 원하는 DATA를 검색한 것이다

- first_name 열에 INDEX를 생성한다

- 다시 실행해보면 바뀌어있다. type이 ref가 되어있다. 이는 검색에 INDEX를 사용한 것을 의미한다. 뒤에 extra도 확인하면, index를 사용한 것을 확인 가능하다
3. VIEW 사용해보기
p.68
VIEW
- select 가 실체이다
- 실제 테이블이 아니라 원본 테이블에서 필요한 열만 추출하여 별도의 가상테이블을 만드는 것
- 원본 테이블에 연결된 일종의 링크 개념
- 하나의 테이블에서 별도의 view를 만들 수도 있지만, 여러 테이블에서 필요한 열을 조합하여 하나의 가상 테이블로 만드는 것도 가능하다
- 보안상 중요 column에 접근하는 것이 꺼려지는 경우 별도의 view를 만들고 이에 접근할 수 있는 사용자를 지정한다

- view를 하나 생성한다. indextbl에서 두 가지 column에 대해 50개를 가져온다
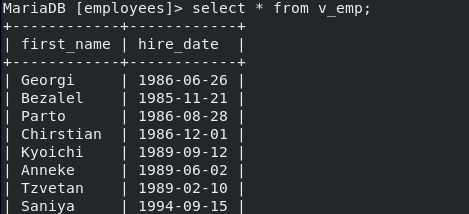
- 잘 생성됬다
- Heidi SQL에서도 잘 확인된다
- 별도로 저장하는 것이 아닌 SELECT로 참조하는 가상 테이블이다
4. 스토어드 프로시져 사용해보기
p.70
스토어드 프로시져
- MariaDB에서 제공하는 프로그래밍 기능으로 함수와 비슷하게 프로그램을 작성한 뒤, 필요할 때마다 호출하여 사용할 수 있다
- 일반적인 인터렉티브한 명령 실행이 아닌 전체 내용을 한꺼번에 실행하는 형식으로 동작한다
- SQL 문은 ;을 통해 명령의 끝을 명시한다. 이 스토어드 프로시져는 전체 프로그램을 기능해야 하므로 ;로 전체 프로그램이 종료되지 않기 위해서 DELIMITER를 사용한다
- 이 DELIMITER를 통해 전체 프로그램을 종료시키는 문자를 바꿔준다

- 프로시져를 만든다
- DELIMITER를 통해 전체 프로그램 종료 문자를 //로 바꿔서 프로시져의 끝에 명시하고, 다시 ;로 바꿔준다
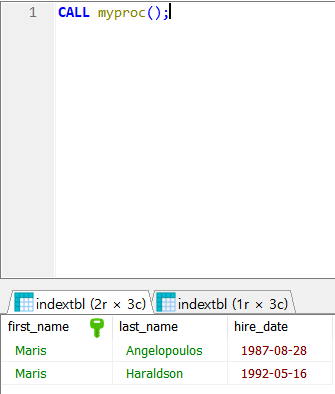
- 프로시져는 CALL로 실행한다
5. TRIGGER 사용해보기
p.73
-
TRIGGER
- TABLE에 부착되어서 TABLE에 작업이 발생되면 실행되는 코드
- 만약, 회원 삭제를 하면 이 회원 정보를 미리 다른 곳에 저장되는 작업이 실행되어 차후에 복구를 가능하게 하는 경우가 있다
-
SQL 설명
- BEFORE/AFTER : 테이블에만 부착되며, 대상 테이블의 insert, delete, update 도착 직전/직후에 미리 지정한 동작을 수행한다
- INSTEAD OF : 대상 테이블의 insert, delete, update 동작 대신 지정한 동작이 대신 수행되며, 이벤트 발생 전 동작한다. 테이블에는 부착되지 않고, 뷰에만 부착된다
- OLD.컬럼명 : DELETE 시 임시 저장되는 공간이다. 삭제 전에 임시로 저장해 놓는다
- NEW.컬럼명 : INSERT, UPDATE, DELETE 작업시 변경할 새로운 DATA를 임시 저장. 따라서 NEW를 조작하면 입력되는 값을 변경 시킬 수 있음
- CUTDATE(), CURTIME(), NOW(), SYSDATE() : 시간을 구하는 프로시져 ( p.243 )
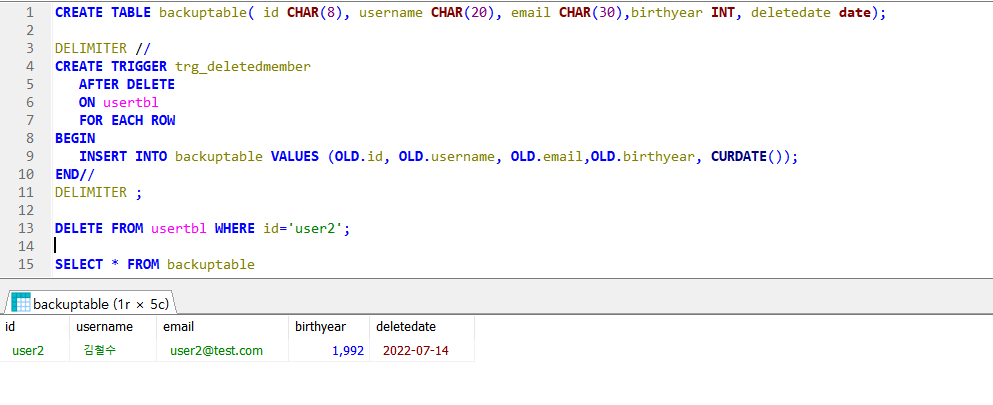
- 백업할 테이블을 만들고, 트리거를 만들어 삭제시 이 백업 테이블에 저장되게 한다
- OLD 테이블에 임시로 저장된 DATA를 백업 테이블에 INSERT 해준다
- CURDATE()를 통해 삭제 명령을 내린 시간을 기록한다
- 트리거는 AFTER DELETE를 통해 삭제 후에 실행되며, usertbl에 부착한다. 이는 FOR EACH ROW를 통해 각 행에 적용되어 각각의 행을 모니터링하며, 아래 BEGIN / ROW 사이의 명령을 실행한다
- 트리거가 잘 생성됬으며, DELETE시 잘 작동한다
6. 데이터 베이스 백업 및 관리
p.76
- 백업은 데이터 베이스 관리 측면에서 가장 중요한 주제 중 하나다
- 이번에는 리눅스에 실제 존재해하는 DATA를 윈도우에 백업해보자
- AWS에서 데이터를 백업할 때는 비밀 통신을 통해 백업한다. 이때 VPN을 사용한다
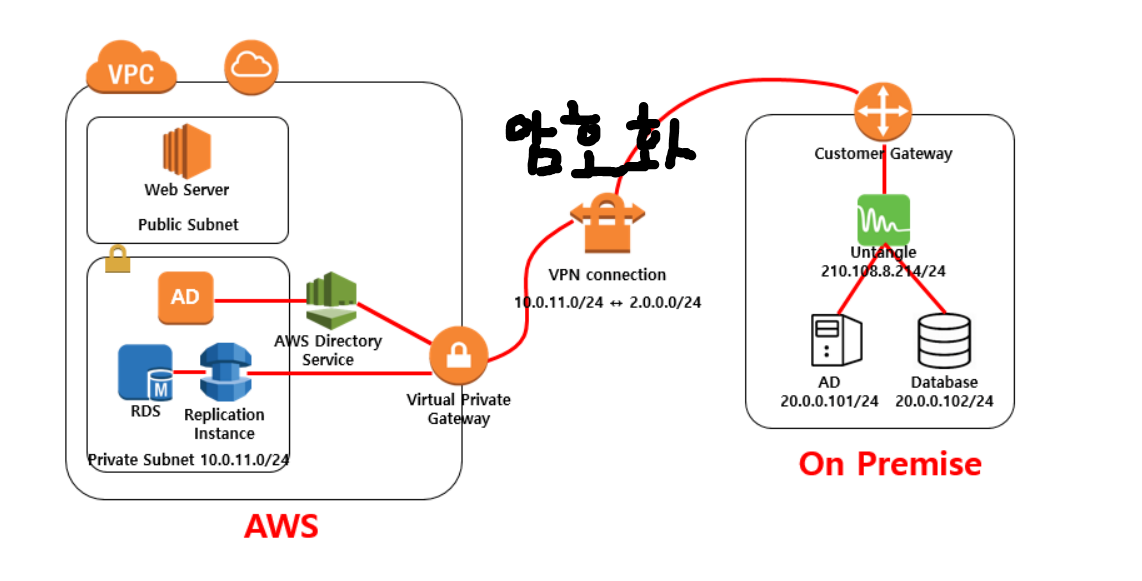
- ON PREMISE : 클라우드가 아닌 LOCAL에 구축하는 환경
- 이 VPN을 통해 전송되는 DATA들은 자동으로 ENCAP, HASH 등과 같은 암호화 기술을 통해 암호화 된다
- AWS에 도착하면 Replication을 통해 복제해서 RDS에 저장한다. 이 RDS에서 용량이 부족하면, 설정을 통해 자동으로 용량을 늘릴 수 있다. 또한 RDS에 대한 백업 공간도 존재한다

- 백업할 SQL 파일을 저장할 폴더를 생성
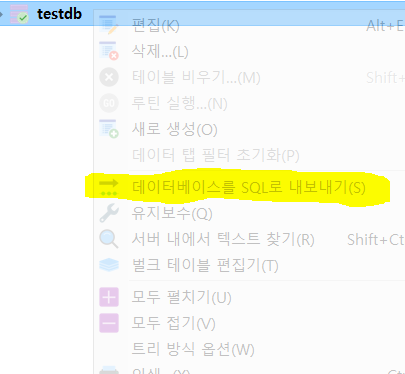
- 백업할 DB를 우클릭해서 내보내기를 누른다
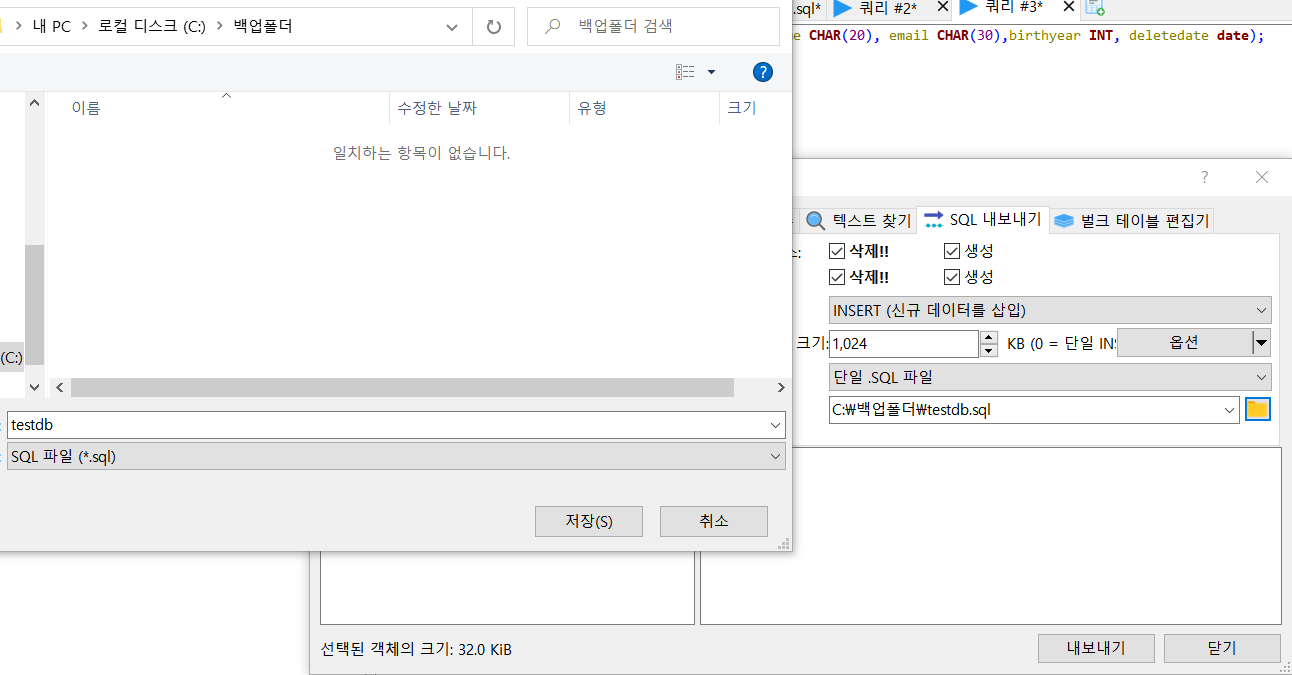
- 다음과 같이 설정한다
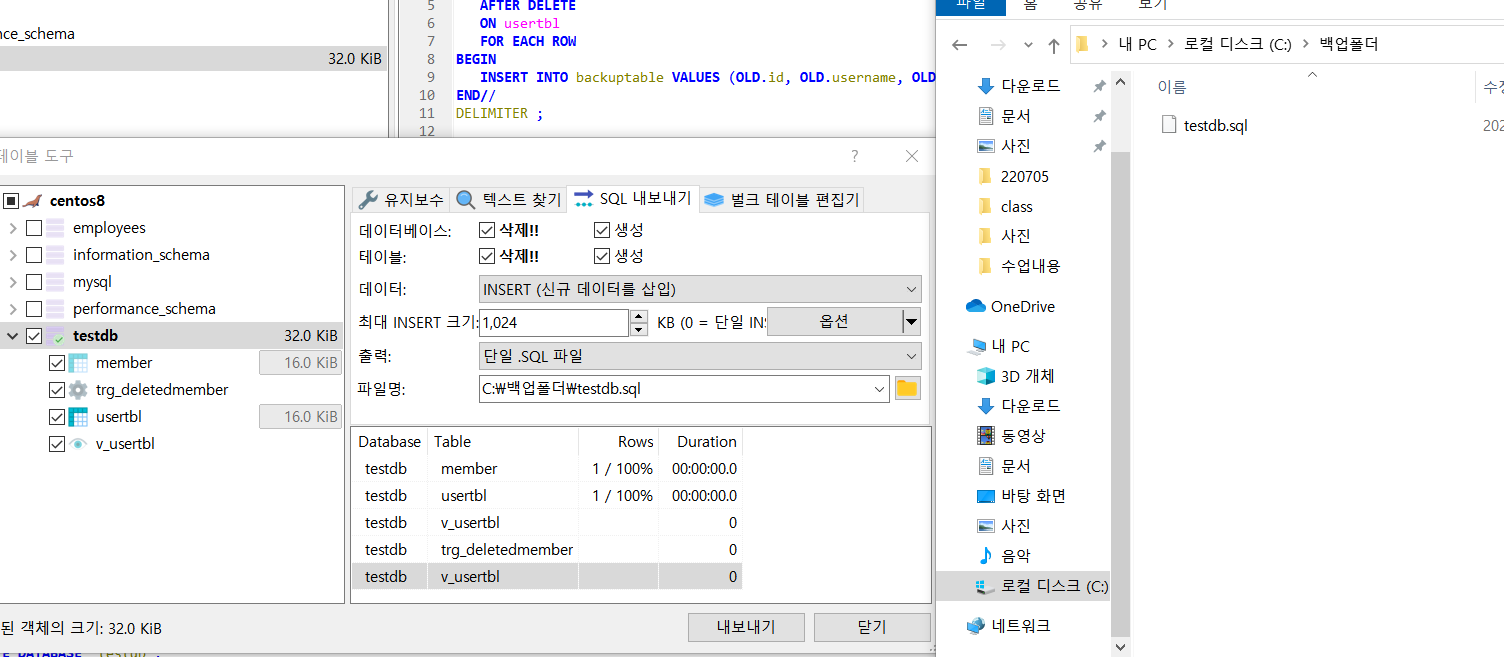
- 내보내기를 누르면 백업 sql 파일이 잘 저장된다
- 복원은 불러오기를 통해 sql 파일을 가져오면 된다

멋진 엔지니어가 될 때까지