
- Semantic Gap
- 바라보는 방향, 밝기, 자세, 가려짐, 배경과의 일치, 종의 다양성 등 같은 클래스를 갖는 객체여도 다양한 모습이 존재
- 인간은 이를 쉽게 같은 클래스로 인식하지만, 기계는 어떻게 이를 같은 클래스로 인식하는가?
- Data-driven approach (데이터 중심 접근 방법)
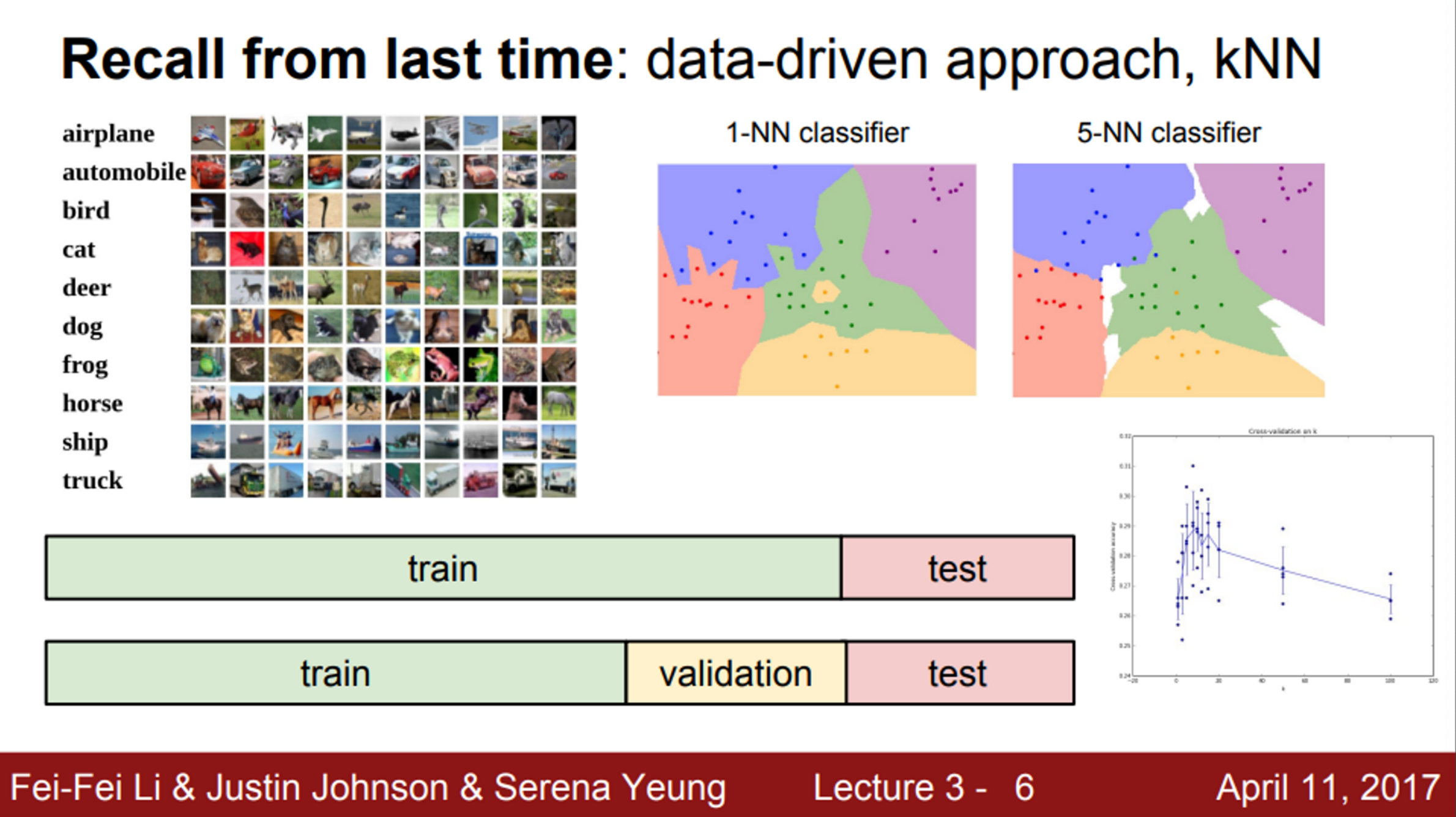
- K-Nearest Neighbor
- Train dataset을 학습하고, 이를 이용하여 predict 과정을 수행
- KNN은, train dataset 중 가장 유사하다고 판단되는 이미지를 선택 후, 해당 클래스로 예측을 하는 방법
- 유사성을 판단하는 척도는 L1 distance / L2 distance 사용
- Dataset을 어떻게 나눌 것 인가?
- train / validation / test 셋으로 나눠서 하이퍼 파라미터를 test 해보고 가장 좋은 것을 선택하는 것이 좋음 (비단, 하이퍼 파라미터에만 해당되는 내용은 아님)
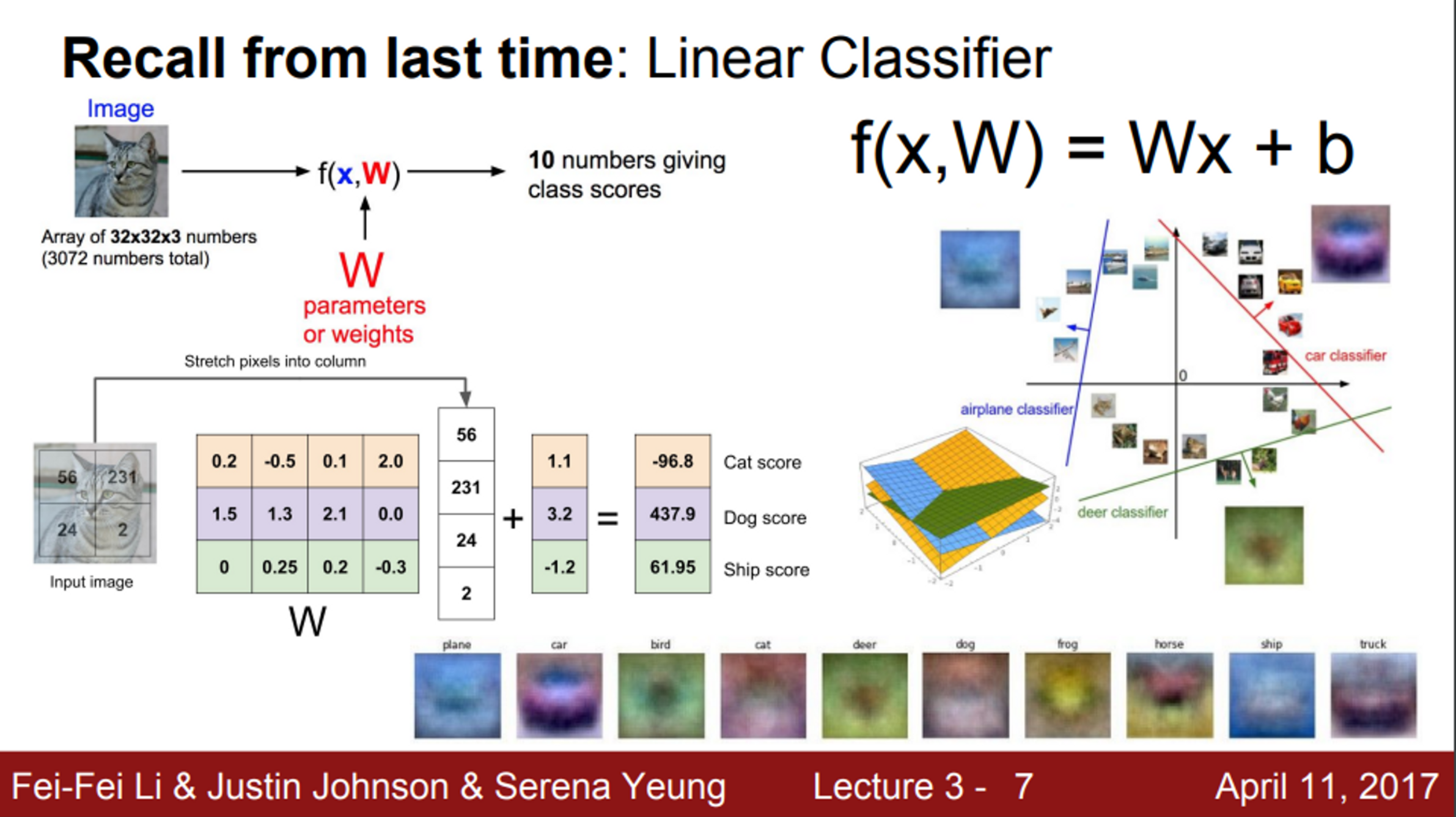
- Linear classifier
- parametric classifier의 일종
- train 단계에서 training set의 정보가 모델 파라미터인 행렬 W로 요약 (W가 학습되는 것)
- 이후, input image에 대한 클래스별 score를 계산한 후, score가 가장 높은 클래스로 예측을 진행

- Linear classification의 최적화 과정은?
- 다음과 같이, 10개의 클래스를 분류하는 Linear classification이 있다고 가정해보자,
- 고양이 이미지를 넣었을 때, 각 클래스별 점수를 보면, 성능이 좋지 않은 것을 확인할 수 있음
- 자동차의 경우 분류를 잘 하지만, 개구리는 분류를 거의 못함
- 이런 상황에서, 우리가 해야할 일은
- loss function을 정의
- loss function이 최소가 되는 파라미터 찾기


- 3개의 클래스로 줄여서 생각해보자
- loss function은 해당 classifier의 성능이 어떤지 판단하는 척도


- 먼저 살펴볼 loss function의 예시는 SVM loss
- 정답의 스코어와 다른 클래스의 스코어를 계산
- 는 클래스 별 스코어, 는 정답 클래스의 스코어

- SVM loss 계산 방법

- Q1. Car 스코어가 조금 변하면, Loss에는 어떤 일이 생길까?
- Car 스코어는 이미 높은 스코어를 갖고 있기 때문에, 조금 변한다고 해도 다른 스코어들과의 간격을 유지가 될 것이며, 따라서 Loss는 변하지 않을 것임

- Q2. SVM loss가 가질 수 있는 최대/최소값은 어떻게 될까?
- 최소값은 0 → 모든 클래스에 대해서 정답 클래스의 스코어가 가장 크다면, 모든 Loss는 0이 될 것임
- 최대값은 무한대 → 정답 클래스의 스코어가 엄청 낮은 음수 값을 가지고 있는 경우

- Q3. 모든 스코어 S가 거의 0에 가깝고, 서로 값이 거의 비슷하다면, Loss가 어떻게 될까?
- 클래스의 수 - 1
- loss 계산 방법을 보면, 이므로, 계산되는 Loss는 1이 될 것

- Q4. SVM loss를 계산할 때, 정답인 클래스는 빼고 전부 다 더했음. 만약 정답인 클래스도 함께 더하면 어떻게 될까?
- Loss에 1이 증가
- 우리가 정답 클래스만 빼고 계산하는 이유는, 일반적으로 Loss가 0이 되어야지, 우리가 아무것도 잃는 것이 없다고 쉽게 해석할 수 있음

- Q5. Loss에서 전체 합을 쓰는 것이 아니라, 평균을 사용하면 어떻게 될까?
- 영향을 미치지 않음
- 평균을 쓴다는 것은, 그저 손실 함수를 리스케일 할 뿐
- 즉, 스케일만 변할 뿐, 상관은 없음
- 우리는 Loss의 절대적인 스코어는 관심이 없음. 상대적인 비교가 중요함

- Q6. 손실 함수를 아래와 같이 제곱항으로 변경하면 어떻게 될까?
- 여러가지 손실 함수 중 하나
- 우리가 에러에 대해서 얼마나 신경을 쓰고 있는지, 그것을 어떻게 정량화 할 것인지에 따라, 선택하는 Loss 함수가 다르다
- 즉, 조금 잘못된 것이든 많이 잘못된 것이든, 우리가 하고자 하는 일은 잘못된 것을 고치는 일
- 중요한 것은 잘못된 것을 고치는 일이지, 많이 잘못된 것이든 조금 잘못된 것이든 큰 차이는 없다

- Loss에 대한 또 다른 질문. 만약 운좋게 Loss가 0인 W를 찾았다고 가정해보자. 이것은 유니크한가? (하나만 존재하는가?)
- W의 스케일은 변함. 따라서, W에 2배를 해도 Loss는 0임.

- 즉, W와 2W의 경우, 정답 스코어와 정답이 아닌 클래스의 스코어의 차이인 margins이 2배가 될 것임
- 모든 margins이 1보다 크다면, 우리가 두배를 한다고 해도 여전히 1보다 클 것이고, 결국 Loss는 0이 될 것
- 근데, 여기서 발생하는 모순
- 손실 함수라는 것이, 분류기에게, 우리가 어떤 W를 찾고 있고 어떤 W에 신경을 쓰고 있는지 말해주는 것이라면,
- 다양한 W 중, Loss가 0인 것을 선택하는 것은 모순임

- 현재 우리는 데이터의 Loss만 신경을 쓰고 있음
- 즉, training data의 Loss에만 신경을 씀 → 이는 training data에 꼭 맞는 W를 찾으라고 하는 것과 동일함
- 하지만, 우리가 원하는 것은 training data에 꼭 맞는 W가 아니라, test data를 잘 분류하는 W

-
우리가 하고자 하는 일은, 어떤 곡선을 파란색 점에 피팅시키는 것
- 우리가 분류기에게 말할 수 있는 것은, 그저 training data에 fit 하게 하라고 말하는 것
- 분류기는 모든 training data를 완벽하게 분류하기 위해서 구불구불한 곡선을 만들 것임
- But, 이는 좋지 않음 → 성능에 대해서 전혀 고려하지 않았기 때문
- 우리는 test data의 성능을 고려해야함
- 만약 초록색의 새로운 데이터가 들어온다면, 앞서 만든 구불구불한 선은 완전히 틀리게 됨
- 사실 우리가 의도한 것은 초록색 선을 찾는 것임
- training data에 완벽하게 fit한 곡선을 원한 것이 아님
-
보통 이러한 문제를 해결하는 방법을 통틀어, Regularization이라고 함
- 손실 함수에 항을 하나 추가함
- Data loss 텀에서는 분류기가 training data에 fit하게 하고, Regularization 텀은 모델이 좀 더 단순한 W를 선택하도록 도와줌
-
Regularization (정칙화)란?
- 가장 먼저, overfitting을 생각해보자. (위 그림에서 파란색 선)
- overfitting이란, 특정 data set에만 지나치게 최적화된 상태
- 학습데이터에 대해 과하게 학습하여 실제 데이터에 대한 오차가 증가할 경우 발생
- 그렇다면, overfitting을 해결할 수 있는 방법은 무엇일까?
- training set을 늘린다 → 이는 학습 시간이 늘어나고, 비용도 늘어나기 때문에 효율적이지 않음
- Regularization
- W가 너무 큰 값을 가지지 않도록 하는 것
- W가 너무 큰 값을 가지게 되면, 과하게 구불구불한 형태의 함수가 만들어지는데, Regularization은 이런 모델의 복잡도를 낮추기 위한 방법
- 가장 먼저, overfitting을 생각해보자. (위 그림에서 파란색 선)

-
가장 보편적인 Regularization은 L2 regularization (weight decay)
- 가중치가 너무 크지 않은 방향으로 학습되게 함
- W를 이용하여 편미분한 값을 이용해서 가중치를 업데이트
-
L1 regularization은 W의 크기와 상관 없이 W의 부호에 따라 상수값을 빼주는 방식
-
L1, L2 Regularization의 차이와 선택 기준
- L1 Regularization은 가중치 업데이트 시, 가중치의 크기에 상관 없이 상수값을 빼면서 진행됩니다.
- 때문에 작은 가중치들은 거의 0으로 수렴 되어, 몇개의 중요한 가중치들만 남게 됩니다.
- 그러므로 몇 개의 의미 있는 값을 끄집어내고 싶은 sparse model 같은 경우에는 L1 Regularization이 효과적입니다.
- 다만, L1 Regularization은 아래 그림처럼 미분 불가능한 점이 있기 때문에 Gradient-base learning 에는 주의가 필요합니다.
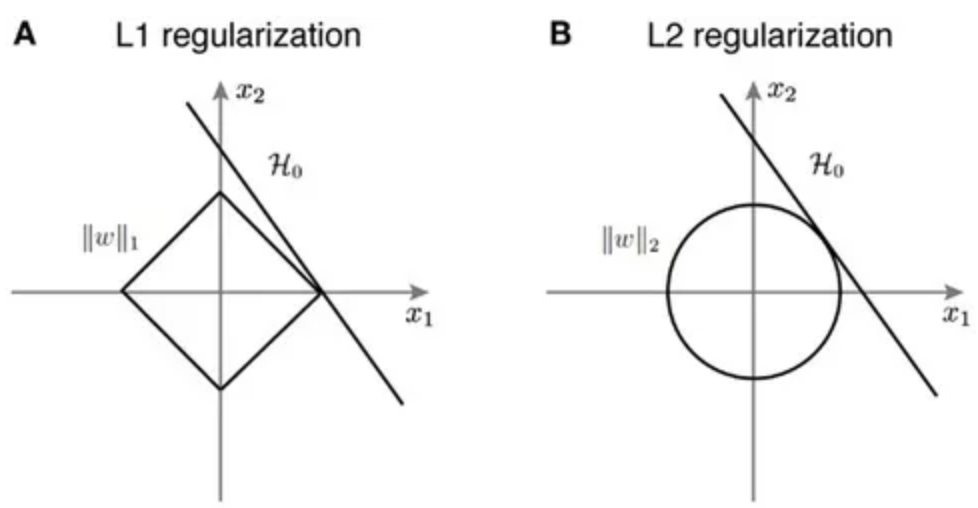
- L2 Regularization은 가중치 업데이트 시, 가중치의 크기가 직접적인 영향을 미칩니다.
- 따라서, L2는 L1 보다 가중치 규제에 좀 더 효과적입니다.


- w1와 w2 모두 다 x와 내적을 했을 때의 값은 1로 동일 (즉, class score가 같다는 의미)
- L1 regularization을 사용하게 되면, w1의 형태를 더 선호
- 보통 영어로는 sparse matrix라고 표현하는데, w1처럼 몇 개만 non-zero 값이고 나머지가 0으로 구성된 경우를 희소 행렬이라고 함
- L1 regularization은 이러한 형태를 더 선호
- L1 regularization은 weight vector에서 모델의 복잡도를 non-zero의 개수로 측정하게 되고, 이는 0이 아닌 게 많을수록 복잡하다고 판단
- 따라서 w1와 같은 형태의 weight vector를 갖도록 강제함
- 이와는 다르게, L2 regularization을 사용하게 되면, w2의 형태를 더 선호
- L2 regularization은 weight를 분산시켜 x의 다른 값들에 대해서 영향력을 분산시키는 역할을 함
- 이는 모델이 특정 x에만 치중되어 class score를 계산하는 것이 아니라, x의 여러 요소들을 반영하여 class score를 계산하게 되기 때문에 훨씬 더 강건한(robust) 모델이 되도록 만들어주는 효과를 가져옴
- L1 regularization은 sparse 한 solution을 만들어내기 때문에, 우리가 input으로 둔 데이터 중에 일부만 가지고 class score를 예측하게 됩니다. 즉, 필요 없는 feature는 제외하는 효과를 가져오는 것이죠. 따라서 feature extraction 혹은 feature selection 효과를 가져오는 것
- 실시간으로 detection을 해야 한다거나 하는 상황처럼, computation을 줄이는 것이 요구되는 상황에서 사용된다고 보시면 될 것
- L1 regularization을 사용하게 되면, w1의 형태를 더 선호


- SVM loss에서, 각 클래스의 스코어 자체에는 관심이 없었음
- 그냥 다른 클래스의 스코어보다 높은지 낮은지가 중요했음
- softmax classifier에서는, 각 클래스의 스코어를 이용해서, 클래스 별 확률 분포를 계산
- 원하는 것은 정답 클래스의 확률이 1에 가깝게 계산되는 것


- Q1. Softmax loss의 최댓값, 최솟값은 얼마인가?
- Loss의 최솟값은 0이고, 최댓값은 무한대
- softmax의 결과 값은 확률이기 때문에, 최솟값이 0이고, 최댓값은 1 (log 안에 값)

- Q2. s가 0 근처에 모여 있는 작은 수 일때, Loss는 어떻게 될까?
- =
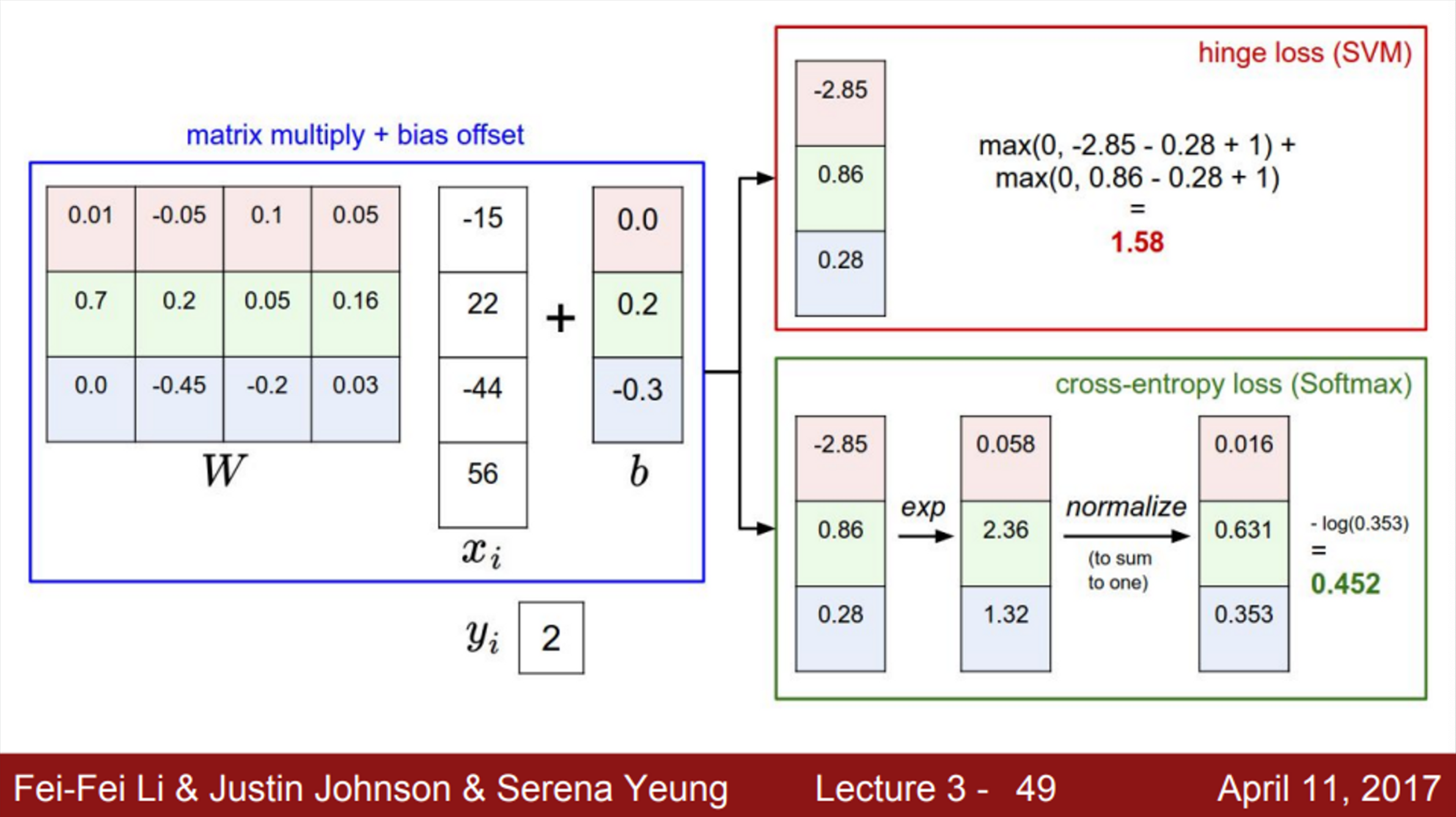
- hinge loss는 정답 클래스의 스코어가, 정답이 아닌 클래스의 스코어보다 정해진 margin만큼 크기만 하면 Loss 값을 0으로 계산하는 특징이 있었음
- 즉, 두 차이가 margin보다 크다면, 그 이후에는 성능을 개선하려고 시도하지 않음
- softmax loss는, 정답 클래스가 선택된 확률을 이용하여 Loss를 계산
- 즉, 정답 클래스가 선택될 확률이 1에 가까우면, Loss는 0에 가까워짐

-
지금까지 다룬 내용을 정리하면,
- dataset을 가지고 있다면, 각 data를 score function에 넣어서 각 클래스 별 스코어를 계산
- 클래스 별 스코어를 이용해서 loss를 계산 (loss function)
-
우리가 다룬 Loss function은 softmax, SVM loss
-
그렇다면, 이제 우리가 생각해볼 문제는, 어떻게 최적의 W를 찾을 것인가? 하는 문제
- 이는 Optimization의 영역

- Optimization을 설명하기 위해, 다음과 같은 예시를 제시
- 우리가 큰 협곡에서 걷고 있다고 가정, 모든 지점에서의 풍경은 parameter W에 대응
- 즉, 위 이미지의 사람이 서있는 지점도 어떤 특정 parameter 값을 나타냄
- 협곡에서의 높이는 해당 parameter에 의해 계산되는 loss와 동일
- 우리의 목표는, 이 협곡의 바닥을 찾는 것 (즉, loss가 0이 되는 경우를 찾고 싶음)


- 첫 번째로 생각할 수 있는 전략은, random search
- 수 많은 weight 중에서 랜덤으로 하나를 샘플링하고, 이를 loss function에 집어 넣어서 해당 weight가 얼마나 잘 예측하는지 보는 것
- 이 방식은, 정확도가 매우 낮기 때문에 실제로는 사용할 수 없음

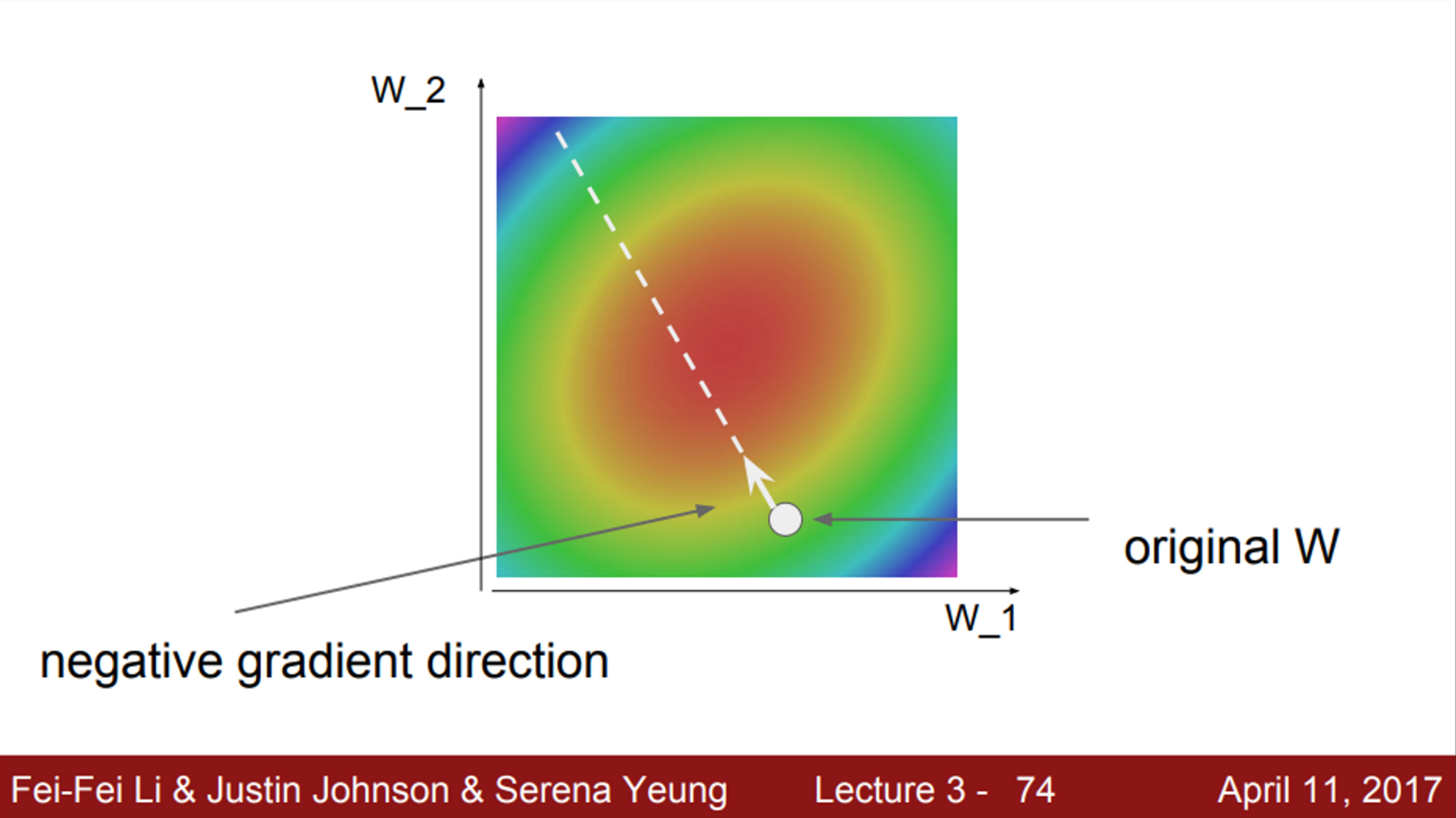
- 다음으로 생각해볼 수 있는 방법은, 기울기(slope)를 따라서 가보는 것
- 실제로 우리가 계곡에서 걷는다고 생각했을 때, 계곡의 바닥으로 가는 경로를 바로 알 수는 없을 것
- 그러나, 현재 위치에서 어떤 방향으로 가야 내리막길로 가게 되는지, 바닥의 기울기를 통해서 찾을 수 있음
- 따라서, 현재 위치에서 어느 방향으로 가야 내리막인지를 판단한 뒤, 해당 방향으로 약간 이동하고, 또 그 자리에서 다시 방향을 판단한 뒤, 해당 방향으로 약간 이동하고 하는 과정을 계속 거쳐서 협곡의 바닥을 찾아낼 수 있음

- 함수의 미분을 이용하여 점의 기울기를 구함


- Numerical gradient (수치 미분)
- 현재 가중치 W에 아주 작은 값을 더해준 후, 두 weight의 loss를 이용하여 를 계산하면, 쉽게 기울기를 찾을 수 있음
- 그러나, 보통 weight의 차원이 매우 크다는 점을 감안했을 때, 이렇게 계산하는 것은 매우 느리다.
- 모든 차원의 값들을 전부 계산해야 하기 때문에

- 따라서, 해석적 미분을 통해 loss function을 W에 대해서 미분하는 방법을 이용
- 이는 고차원의 데이터도 한 번에 계산할 수 있기 때문에

- 요약하면, gradient를 계산하는 방법은, numerical gradient와 analytic gradient 두 가지가 존재
- 실제로는 analytic gradient를 사용
- 우리가 짠 코드가 잘 맞는지 확인해보기 위해서는 numerical gradient를 이용하여 일종의 unit test를 진행 → 이를 gradient check라고 부름
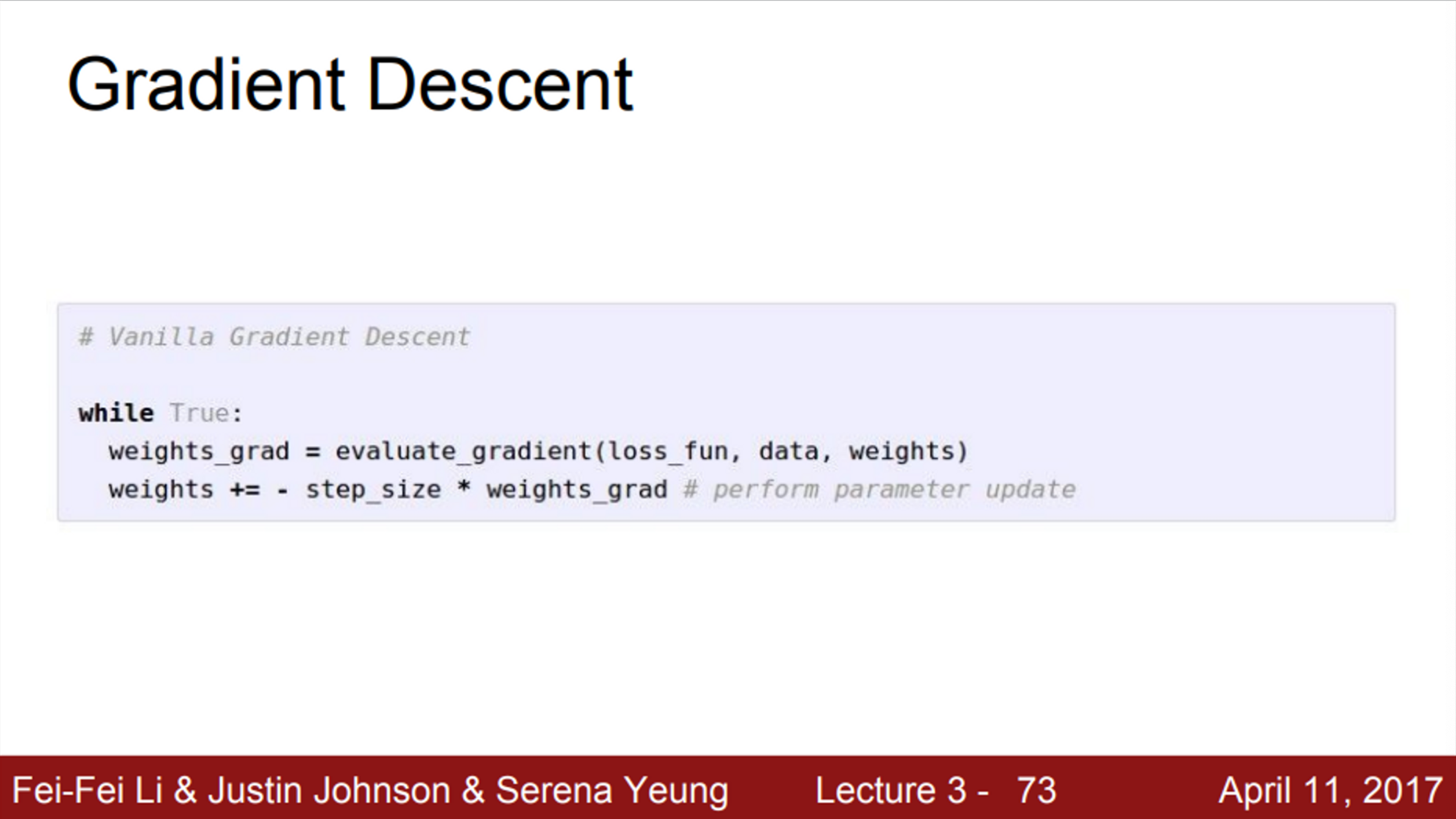
- gradient descent를 어떻게 계산할 것인지 코드로 구현
- 우선 W를 임의의 값으로 초기화
- 그 후, Loss와 gradient를 계산한 뒤, 가중치를 gradient의 반대 방향으로 업데이트
- 이걸 반복하다보면, 결국에는 수렴할 것
- step_size는 learning rate
- optimizer에는 여러가지가 존재함
- 중요한 것은, 모두 gradient descent를 기반으로 만들어짐

- 우리가 정의했던 손실 함수를 보면, 전체 Loss는 전체 트레이닝 셋 Loss의 평균으로 사용했음
- 하지만, 실제로 N이 엄청 커질 수 있음 → 이런 경우라면, Loss를 계산하는 것은 오래 걸림
- 따라서, 전체 트레이닝 셋을 이용하는 것이 아니라, Minibatch라는 작은 트레이닝 샘플 집합으로 나눠서 학습하는 방법을 사용
- 작은 minibatch를 이용해서 Loss의 전체 합의 추정치와 실제 gradient의 추정치를 계산하는 것
- 그래서 stochastic 하다는 것은 Monte Carlo Method의 실제 값 추정 방법과 유사하다고 볼 수 있음
- 즉, 임의의 minibatch를 만들어내고, minibatch에서 loss와 gradient를 계산. 그리고 W를 업데이트
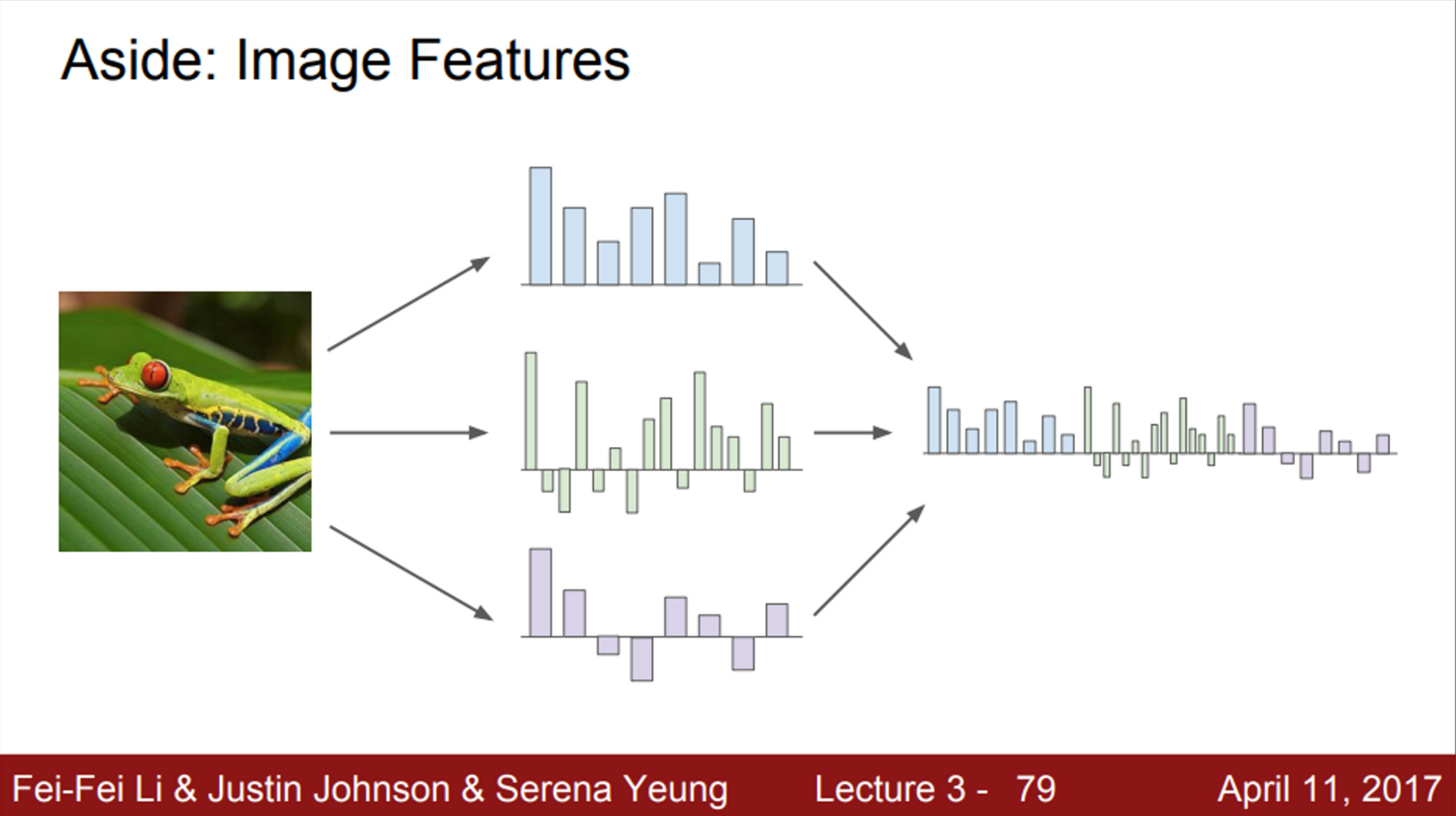
- 지금까지 linear classification에 대해서 이야기를 했음
- 실제 Raw 이미지 픽셀을 입력으로 받는 방식에 대해서 살펴봄 (원본 이미지 그대로)
- 이런 경우는 좋은 방식이 아님 → 지난 시간에 얘기했던, 말 머리가 2개인 케이스,,
- 즉, 실제 이미지를 그대로 사용하는 것은 성능이 좋지 않음
- 그래서, 이전에 사용하던 방법은 두 가지 stage를 거치는 방법을 사용했음
- 이미지가 있으면, 여러가지 특징 표현을 계산하는 것
- 여러 특징 표현들을 하나로 연결시켜(concat) 하나의 특징 벡터로 만듦
- 이 특징 벡터가 Linear classifier의 입력으로 들어감
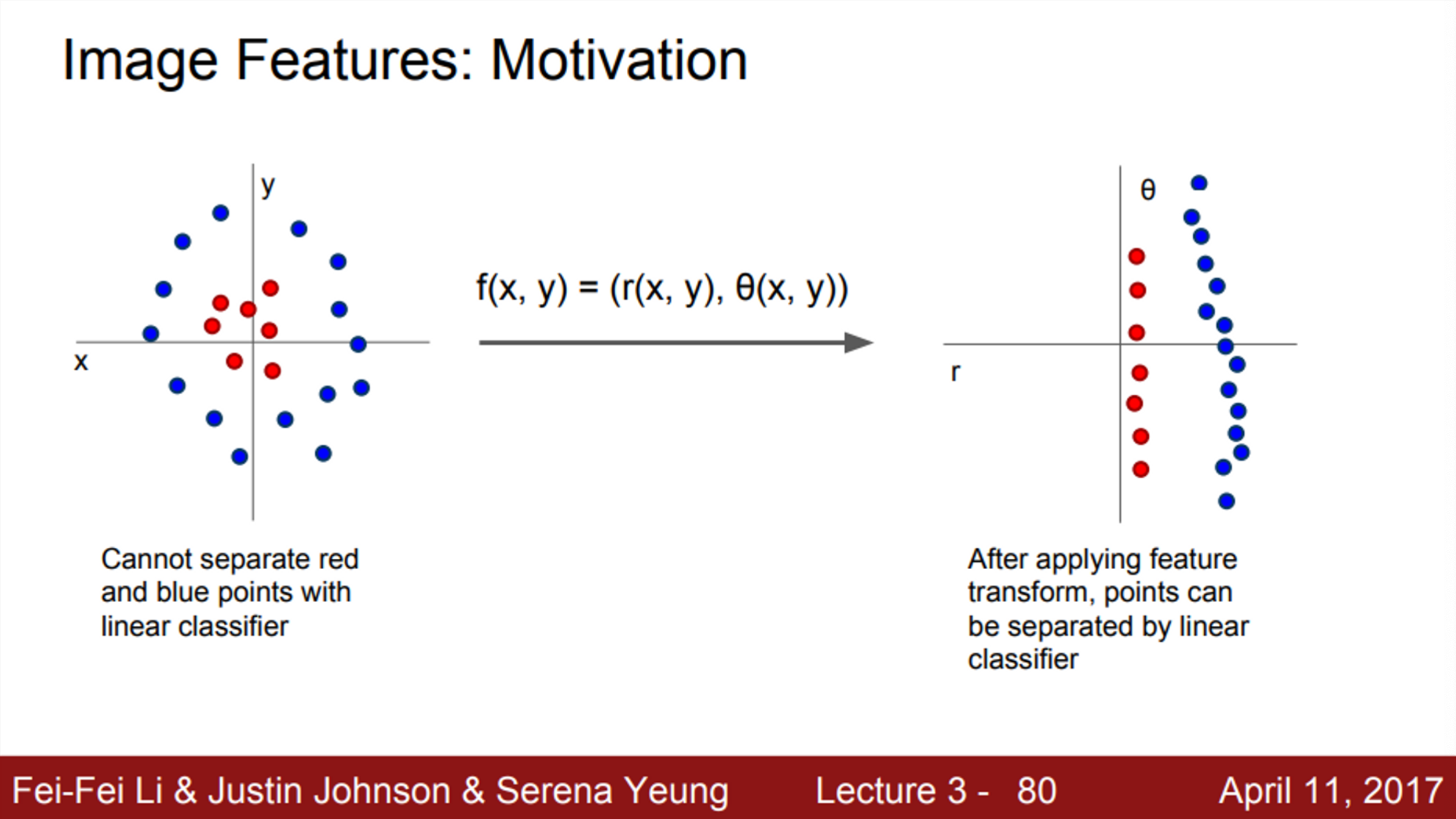
- 우리가 이전에 봤던, Linear classification의 한계점인, 하나의 직선으로 데이터를 모두 구분할 수 없다는 문제를 해결하기 위한 방법을 사용한 것
- 즉, feature transform을 이용하여 data들의 분포된 형태를 바꿔주게 되면, linear classifier를 이용하여 분류할 수 있게 된다
- 따라서, 사람들은 이미지에 대해서 어떤 feature representation을 뽑게되면, 더 좋은 성능을 낼 수 있을거라고 생각함
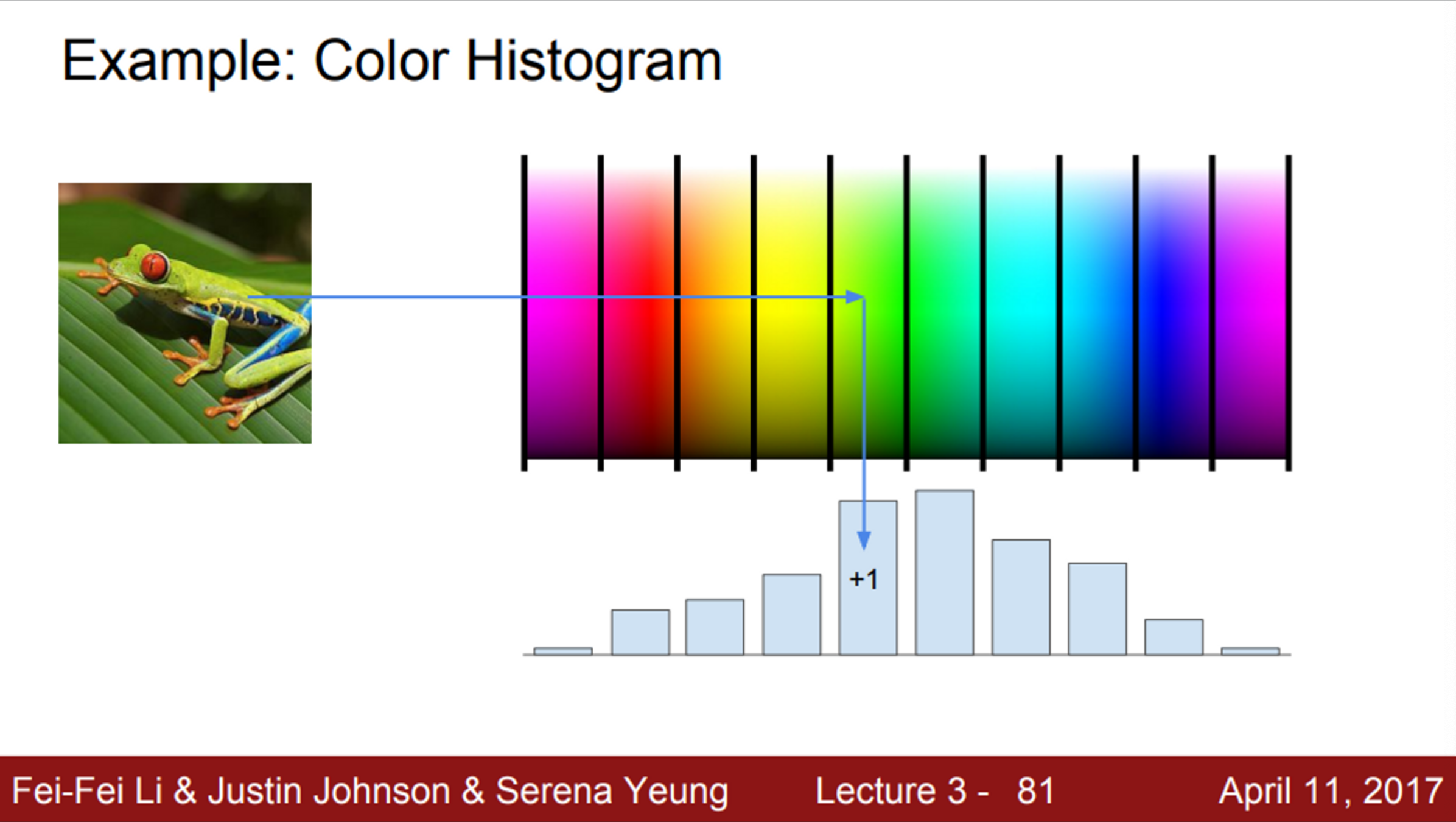
- 그렇다면, 딥러닝 이전에 사람들은 어떤 feature representation을 사용했을까?
- 첫 번째 예시는 color histogram
- 색에 대한 스펙트럼으로 나누는 방법

- 다음으로는, HoG
- 사람의 visual system에서 oriented edge가 중요한 역할을 하는데, 이를 직관적으로 포착하려고 시도

- 세 번째 예시는 Bag of words
- 이는 NLP에서 영감을 얻은 방법
- 먼저, 이미지의 각 patch들을 추출해서, 이를 visual word로 생각하고, K-means clustering 등의 방법을 이용하여 군집을 형성. codebook을 만듦
- 다음으로, 이미지에 대해서 visual word가 얼마나 자주 나오는지 count하여, 이미지의 feature representation을 얻을 수 있음
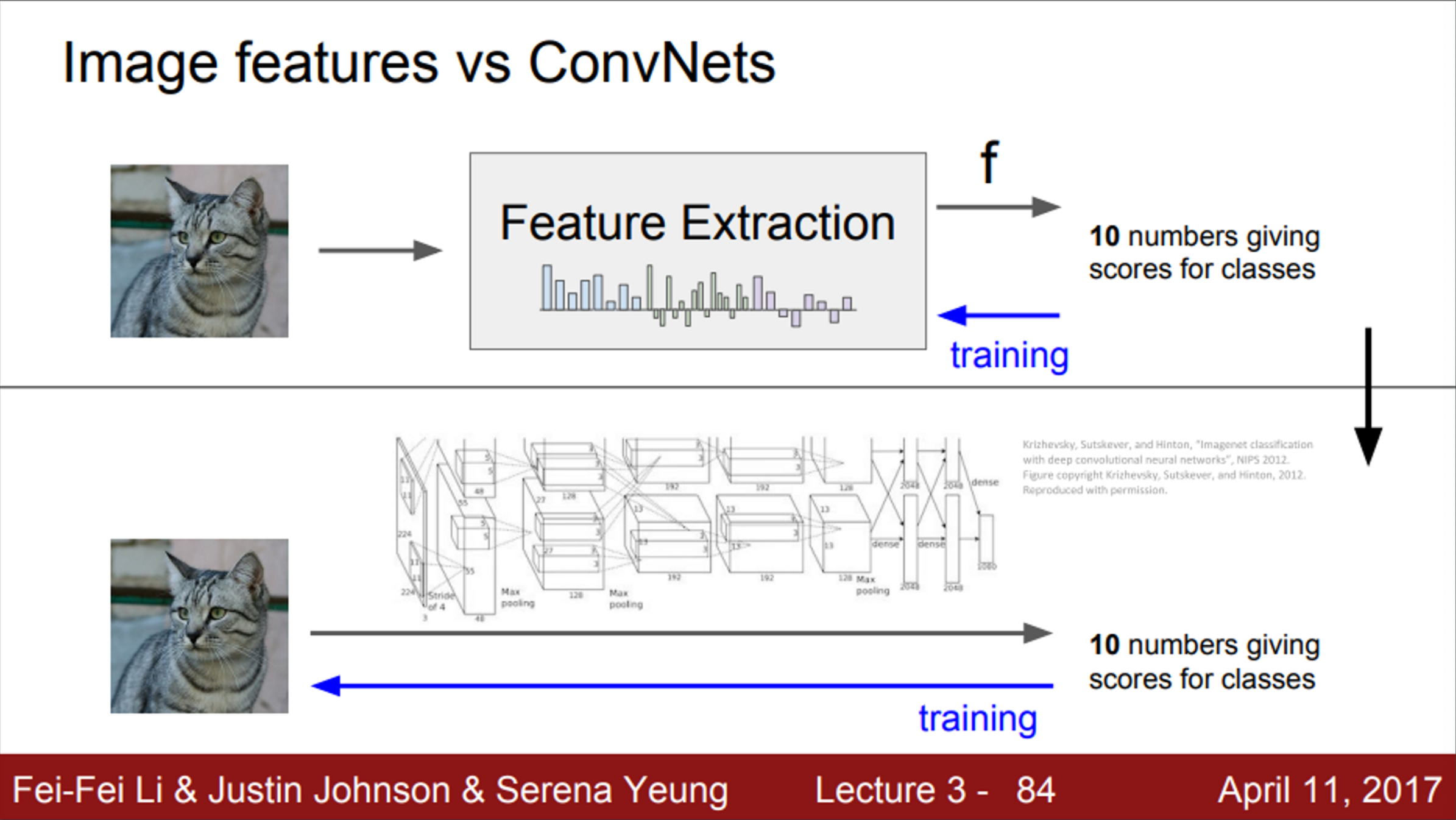
- 기존의 image classification에서는 bag of words나 HoG와 같은 방식으로 다양한 feature representation을 계산하고, 이를 linear classifier의 입력으로 사용했음
- 즉, feature가 한번 추출되면, classifier를 학습하는 동안에는 변하지 않았음
- 오직 linear classifier만 훈련됨
- CNN은 feature를 미리 만들어 놓고 사용하는 것이 아니라, 학습 과정에서 데이터를 통해 직접 찾음
- 그렇기 때문에, raw 픽셀이 그대로 입력으로 들어가고, 여러 레이어를 거쳐서 데이터를 통한 특징 표현을 직접 만들어냄
- 즉, linear classifier만 훈련하는 것이 아니라, 가중치 전체를 한꺼번에 학습하는 것

코딩하는 물리학도