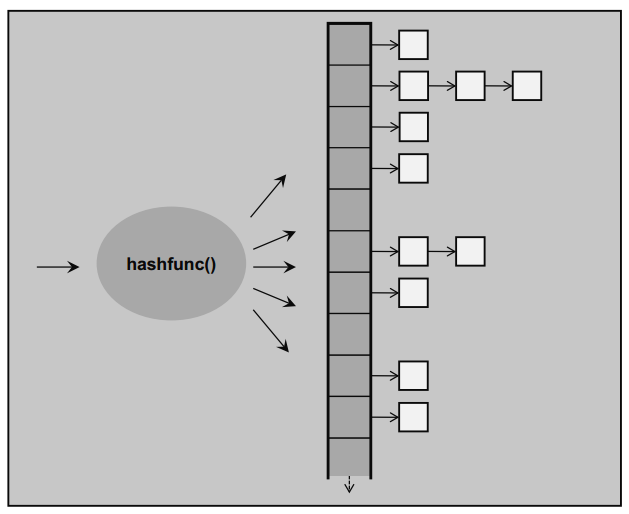
unordered_set
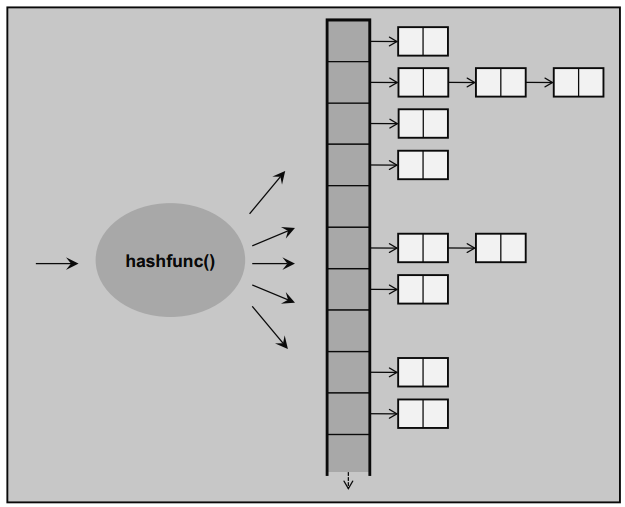
unordered_map
정의
- set, map보다 더 빠른 탐색을 하기 위한 자료구조
- set, map과 비슷하나 원소들이 정렬되어 있지 않다.
- 해시 함수를 이용해 값을 저장하고 탐색한다.
원소의 key 값(데이터형)을 hash function을 통해 생성한다. (대부분 정수값)
- 데이터를 담을 때 해시 함수를 거쳐서 번호표를 받는다.
해시 값을 미리 내부에 vector로 만들어 놓는다. (버킷을 만들어 놓는다.)
버킷 번호와 해시 값을 매칭시켜 데이터를 찾는다.
= key 값마다 해시 번호표가 있어서 원하는 데이터를 즉각 찾을 수 있다.
-> 탐색, 삽입, 삭제 시 O(1)의 시간 복잡도를 갖는다.
<-> set, map은 O(log n)의 시간 복잡도를 갖는다.
- 상수 시간에 원소를 삽입, 검색할 수 있다.
- 다른 원소이지만 같은 해시값을 가질 수 있다(해시 충돌)
시간 복잡도
- 탐색, 삽입, 삭제 시 O(1)의 시간 복잡도를 갖는다.
- 해시 충돌이 많이 일어나 한 상자 안에 서로 다른 원소들이 몰려서 저장되게 되면 해당 상자 안에서 찾고자 하는 원소를 탐색해야 하므로 최악의 경우 모든 원소가 한 곳에 모였을 때 O(N) 시간이 걸릴 수 있다. (set보다 오래 걸릴 수 있다.)
원소의 개수가 많을수록 해시충돌이 일어날 확률도 높아지므로
원소의 개수가 적고 빠른 성능을 원할 땐 unordered_set
원소의 개수가 많아 안정성을 원할 땐 set
장점
- 중복된 데이터를 허용하지 않고 set, map에 비해 데이터가 많을 시 월등히 좋은 성능을 보인다.
단점
- key가 유사한 데이터가 많을 시 해시 충돌로 인해 성능이 떨어질 수도 있다.
- 빠른 성능을 위해 많은 메모리를 필요로 한다.
unordered 컨테이너에 사용자 정의 자료형의 삽입
- 직접 정의한 자료형(struct, class)을 unordered 컨테이너에 담기 위해서는 해시 번호표를 만들 수 있어야 한다.
-> hash <> 함수를 거칠 수 있어야 한다.
-> hash<> 함수를 거치기 위해서는 ==와 () 연산자가 const로 오버로딩 돠어있어야 한다.
-> hash <> 템플릿에 대해서 특수화해준다.
참고 사이트
https://dev-su.tistory.com/m/60
https://math-coding.tistory.com/31
https://ssinyoung.tistory.com/48
