
시퀀스 컨테이너
- 데이터가 선형적으로 저장되는 컨테이너
- 순서를 유지하는 구조
1) 벡터(Vector)
- 동적 배열 구조로, 런타임에 크기를 임의로 변경할 수 있다.
동적배열
- 여유분을 두고 메모리를 할당
- 메모리가 꽉차면 메모리를 증설
- 메모리에 데이터가 연속적으로 위치한다.
- 벡터는 포인터 세 개로 구현되어 있다.
- 할당된 배열의 시작 주소를 가리키는 포인터
- 다음에 데이터가 삽입될 위치를 가리키는 포인터
- 할당된 배열의 끝 주소를 가리키는 포인터
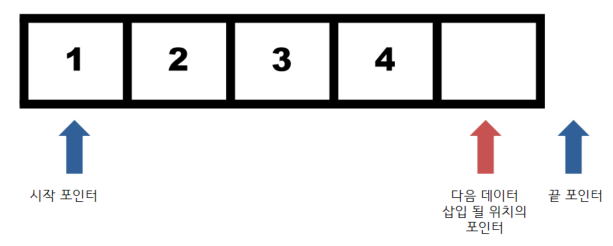
- 데이터를 삽입하면 빨간 포인터가 가리키는 부분에 삽입되고, 빨간 포인터가 1 증가한다.
- 벡터의 메모리 할당 방식은 size(실제 사용 데이터 개수)와 capacity(여유분을 포함한 용량 개수)로 이루어져있다. (항상 size <= capacity)
- capacity는 변화할 때마다 delete하고 복사하는 비용이 들어간다.
capacity를 작게 설정하고 데이터를 계속 늘릴 경우, 복사 비용이 지속적으로 들어 비효율적이다.
따라서 처음부터 복사 비용이 발생하지 않도록 capacity를 크게 잡는 것이 좋다.
이는 reserve()를 사용하는 이유이기도 하다.
- capacity는 변화할 때마다 delete하고 복사하는 비용이 들어간다.
- 중간 삽입/삭제가 비효율적이다.
삽입/삭제 위치 뒤의 모든 데이터를 한 칸씩 밀거나 당겨야 하기 때문이다.
-> 리스트를 사용하는 것이 더 효율적이다. - 데이터가 연속적이므로 특정 원소를 인덱스로 임의 접근(Random Access)이 가능하다.
2) 배열(Array)
- 벡터와 마찬가지로, 메모리에 데이터가 연속적으로 위치한다.
- 배열은 연속된 메모리들의 첫 주소를 담는 포인터이다.
- 중간 요소를 삭제할 경우, 뒤에 있는 데이터를 삭제한 수만큼 앞으로 이동시켜야 한다.
배열은 메모리를 미리 할당(pre-allocation)하므로 데이터를 추가하여 처음 할당한 것보다 요소가 많아지면 Resizing이 필요하다.
배열은 삽입/삭제 시 메모리 상에서 이루어지는 작업이 크므로, 삽입/삭제가 빈번하게 이루어지는 작업에는 적합하지 않다. - 특정 원소를 인덱스로 임의 접근(Random Access)이 가능하다.
3) 리스트(List)
- STL list는 이중 연결 리스트(doubly linked list)로 노드 기반 컨테이너이다.
- index로 직접 접근 불가능
- 양끝 부분의 값들에만 접근 가능하며, 그 사이의 값들은 순차적으로 하나씩 선형 탐색해야 접근 가능
- 메모리 상에 데이터가 비연속적으로 저장된다.
- 중간 삽입/삭제는 모든 데이터를 하나씩 밀거나 당길 필요없이, 링크 필드만 변경하면 되므로 벡터보다 효율적이다.
- 원소 접근보다는 추가/제거가 빈번한 작업에 적합하다.
- 노드 기반으로 데이터를 저장하기 때문에 임의 접근(Random Access)가 불가능하다.
연관 컨테이너
- Key - Value 구조를 가지는 컨테이너
- 특정 기준에 따라 원소를 자동 정렬하는 컨테이너
1) 맵(Map)
- 각 노드가 key와 value의 쌍으로 이루어진 트리
- 중복을 허용하지 않는다.
- map의 각 원소들은 pair 객체로 저장되는데, first가 key, second가 value로 저장된다.
- Red-Black Tree(자가 균형 이진 탐색 트리)로 구현되어 있다.
- 자료를 저장할 때 자동으로 key 값을 기준으로 오름차순 정렬한다.
- 자동 정렬하므로 원소의 삽입/삭제가 빈번할 경우 성능 저하
- key를 통해 value 접근
2) unordered_map
- map과 달리, 정렬되지 않고 랜덤하게 저장된다.
- 자동 정렬하지 않으므로, 정렬이 필요없는 경우에 사용하면 성능 향상이 가능하다.
- map과 다르게 Hash Table로 구현되어 있다.
- 어떤 원소가 삽입될 때, 원소 값을 해시 함수에 넣어 1 ~ N(==해시 테이블의 크기) 중 특정 해시값을 반환해 삽입된 원소가 저장될 해시 테이블의 인덱스로 삼게 된다.
- 1이라는 원소를 넣을 때 hashFunc(1) = 2 라면 Hash Table의 2번 인덱스에 저장된다.
- 같은 원소를 해시 함수에 전달한다면 같은 해시값을 리턴하므로 원소의 탐색을 빠르게 수행할 수 있다.
- 해시 함수는 해시값 계산을 상수 시간에 처리하기 때문에 unordered_map은 탐색을 상수 시간 0(1)에 처리할 수 있다.
- 다만, 해시 테이블의 크기가 원소 개수보다 적기 때문에 다른 원소이지만 같은 해시값을 가져 같은 해시 테이블에 저장되는 경우가 발생할 수 있다. (== 해시 충돌)- 위와 같은 경우 같은 상자 내에서 한 번 더 탐색을 거쳐야 한다. 운이 매우 나쁘다면 해시값이 겹치는 경우가 많이 발생해 O(N)의 탐색 시간이 걸릴 수도 있다.
- 어떤 원소가 삽입될 때, 원소 값을 해시 함수에 넣어 1 ~ N(==해시 테이블의 크기) 중 특정 해시값을 반환해 삽입된 원소가 저장될 해시 테이블의 인덱스로 삼게 된다.
- 많은 자료를 저장하고, 검색 속도가 빨라야 하는 경우에 사용하면 좋다. (자료양이 적을 때는 메모리 낭비 발생)
- 나머지는 map과 동일한 특징을 가진다.
참고
https://velog.io/@doorbals_512/UNSEEN-테스트-대비-C-컨테이너들의-동작-원리
https://velog.io/@starkshn/vector-1-2-3-4
https://kim-mj.tistory.com/236
https://velog.io/@knavoid/C-List-Container
