
Pandas로 2차원 데이터 다루기 - dataframe
dataframe?
- 2-D labeled table
- 인덱스를 지정할 수도 있음
d = {"height" : [1,2,3,4], "weight" : [30,40,50,60]} df = pd.DataFrame(d) df
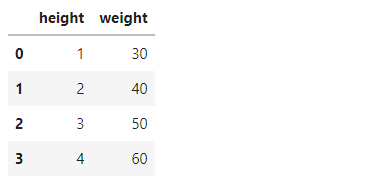
- 각 column 별로 datatype 이 다를수 있기에
.dtype가 아닌.dtypes를 사용
df.dtypesheight int64 weight int64 dtype: object
From CSV to Dataframe
- Comma Seperated Value를
DataFrame으로 생성해줄 수 있다. .read_csv함수를 이용
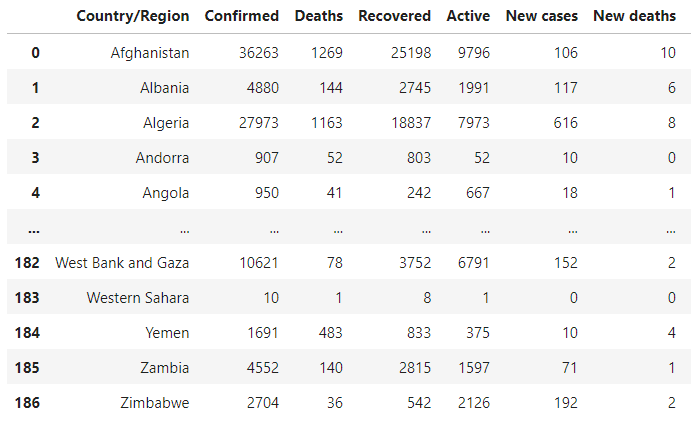
.read_csv함수에 매개변수로 csv 파일 경로를 입력covid = pd.read_csv("./archive/country_wise_latest.csv") covid
Pandas 활용1 : 일부분만 관찰하기
.head(n): 처음 n개의 데이터를 참조
- 상위 5개를 관찰하는 방법
covid.head(5)

.tail(n): 마지막 n개의 데이터를 참조
- 하위 5개를 관찰하는 방법
covid.tail(5)

Pandas 활용2 : 특정 데이터 접근하기
- dict 스타일로 접근 :
df['column_name'] - 개채적 관점에서 접근 :
df.column_name
covid['Active']0 9796 1 1991 2 7973 3 52 4 667 ... 182 6791 183 1 184 375 185 1597 186 2126 Name: Active, Length: 187, dtype: int64
covid.Active1 1991 2 7973 3 52 4 667 ... 182 6791 183 1 184 375 185 1597 186 2126 Name: Active, Length: 187, dtype: int64
- column_name에 띄어쓰기가 있다면 개채적 관점에서의 접근은 사용할 수 없다.
TIP!! : Dataframe의 각 column은 "Series"이다!
dataframe의 각 column은series이다.
type(covid['Active'])pandas.core.series.Series
covid['Confirmed'][1:5]1 4880 2 27973 3 907 4 950 Name: Confirmed, dtype: int64
Pandas 활용3 : '조건'을 이용해서 데이터 접근하기
- 열을 기준으로 데이터 접근
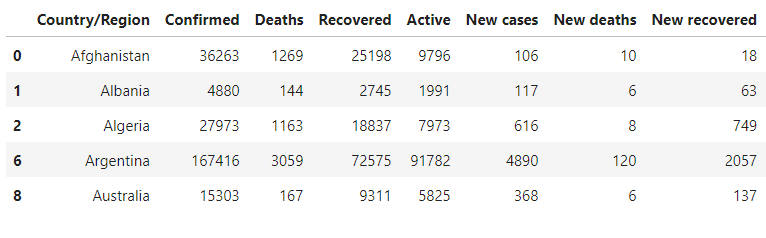
- 신규 확진자가 100명이 넘는 나라를 반환
covid[covid['New cases'] > 100].head(5)
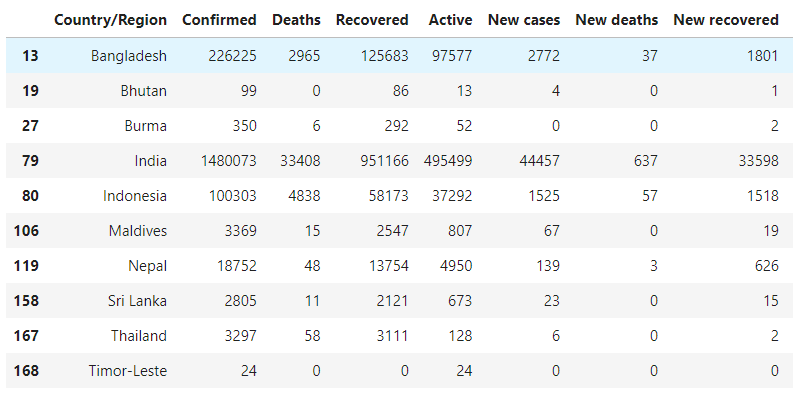
- WHO 지역(WHO Region)이 동남아시아인 나라 찾기
covid[covid['WHO Region'] == 'South-East Asia']
Pandas 활용4 : 행을 기준으로 데이터 접근
books_dict = {"Available" : [True, True, False], "Location" : [102,215, 323], "Genre" : ["Programming" , "Physics", "Math"]} books_df = pd.DataFrame(books_dict, index = ["버그란 무었인가", "두근두근 물리학", "미분해줘 홈즈"]) books_df

인덱스를 이용해서 가져오기 : .loc[row,col]
print(type(books_df.loc["버그란 무었인가"])) books_df.loc["버그란 무었인가"]<class 'pandas.core.series.Series'> Available True Location 102 Genre Programming Name: 버그란 무었인가, dtype: object
- '미분해줘 홈즈'책이 대출 가능한지 확인
books_df.loc["미분해줘 홈즈", "Available"]False
숫자 인덱스를 이용해서 가져오기 : .iloc[rowidx, colidx]
- 인덱스 0행의 인덱스 1열 접근
books_df.iloc[0,1]102
- 인덱스 0행의 인덱스 0~1열 접근
books_df.iloc[0, 0:2]Available True Location 102 Name: 버그란 무었인가, dtype: object
Pandas 활용5 : groupby
- groupby의 기능
- Split : 특정한 기준을 바탕으로 DataFrame을 분할
- Apply : 통계함수 -
sum(),mean(),median()- 을 적용해서 각 데이터를 압축 - Combine : Apply된 결과를 바탕으로 새로운
Series를 생성
- WHO Region 별 확신자수
- covid에서 확진자 수
column만 추출- 이를 covid 의 WHO Region을 기준으로
groupby한다.covid_by_region = covid['Confirmed'].groupby(by = covid["WHO Region"]) covid_by_region.sum()WHO Region Africa 723207 Americas 8839286 Eastern Mediterranean 1490744 Europe 3299523 South-East Asia 1835297 Western Pacific 292428 Name: Confirmed, dtype: int64
- 국가당 감염자 수
covid_by_region.mean()WHO Region Africa 15066.812500 Americas 252551.028571 Eastern Mediterranean 67761.090909 Europe 58920.053571 South-East Asia 183529.700000 Western Pacific 18276.750000 Name: Confirmed, dtype: float64
Mission:
1. covid 데이터에서 100 case 대비 사망률(Deaths / 100 Cases)이 가장 높은 국가는?
.sort_values를 이용하여 사망률이 가장 높은 순으로 정렬 후.iloc과.head를 이용하여 가장 상위의 국가명을 출력하였다.covid.sort_values('Deaths / 100 Cases',ascending = False).head(1).iloc[0,0]
2. covid 데이터에서 신규 확진자가 없는 나라 중 WHO Region이 'Europe'를 모두 출력하면?
Hint : 한 줄에 동시에 두가지 조건을 Apply하는 경우 Warning이 발생할 수 있습니다.
- 1차적으로 신규확진자가 없는 나라를 구성, 최종적으로 유럽의 국가를 반환
covid_newcases_0 = covid[covid['New cases'] == 0] covid_newcases_0_Europe = covid_newcases_0[covid_newcases_0['WHO Region'] == 'Europe'] covid_newcases_0_Europe56 Estonia 75 Holy See 95 Latvia 100 Liechtenstein 113 Monaco 143 San Marino 157 Spain Name: Country/Region, dtype: object


AI Tensorflow Python